本文主要是介绍Spring Boot + EasyExcel + SqlServer 进行批量处理数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在日常开发和工作中,我们可能要根据用户上传的文件做一系列的处理,本篇文章就以Excel表格文件为例,模拟用户上传Excel文件,讲述后端如何高效的进行数据的处理。
一.引入 EasyExcel 依赖
<!-- https://mvnrepository.com/artifact/com.alibaba/easyexcel --><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.3.2</version></dependency>二.在接口中编写代码
(一).使用什么参数接收?
由于用户上传的是一个Excel文件,也就是说前端发来的是一个Excel表格的文件,那么我们后端就需要使用 MultipartFile file 来进行接收
@PostMapping("/importExcelUpdateFlag")public Map<String,Object> importExcelUpdateFlag(@RequestBody MultipartFile file) {//具体代码......}(二).如何存储到本地目录中(最后说为什么存储到本地)
既然前端发来了一个Excel文件,后端需要对其进行重命名还有大量的数据处理,那么如何存储到本地是一个问题。我们在三层架构的基础上,这个存储到本地的工作一般放在 Service 层进行处理。
Controller层的代码
下面的 uploadPath(也就是你要存储到本地的目录) 是自己在 yml文件中定义好的,然后进行使用,截图如下:
@PostMapping("/importExcelUpdateFlag")public Map<String,Object> importExcelUpdateFlag(@RequestBody MultipartFile file) {//把前端发来的文件数据,传到本机指定的 uploadPath 目录之下String pathAndFileName = jdCloudService.uploadFile(file,uploadPath);//其他代码....}注意这里 pathAndFileName 接收的是一个本地路径,后续需要根据这个路径找到指定文件
Service 层的代码
代码解读:我们假设前端传来了一个 hello.xlsx 文件@Overridepublic String uploadFile(MultipartFile file, String uploadPath) {if(file.isEmpty()){return "上传文件为空";}try {String originalFilename = StringUtils.cleanPath(file.getOriginalFilename());String fileExtension = originalFilename.substring(originalFilename.lastIndexOf("."));String newFilename = generateFilename() + fileExtension;File targetFile = new File(uploadPath + File.separator + newFilename);file.transferTo(targetFile);return uploadPath + "\\" + newFilename;} catch (Exception e) {return "文件上传失败: " + e.getMessage();}}private String generateFilename() {// 根据你的需求生成新的文件名,例如使用时间戳或随机字符串等,这里使用时间戳return String.valueOf("更新文件名.." + System.currentTimeMillis());}
String originalFilename = StringUtils.cleanPath(file.getOriginalFilename());这行代码会将 "hello.xlsx " 赋值给originalFilename变量。这行代码会从 "hello.txt" 中提取出文件扩展名 ".txt",并将其赋值给
String fileExtension = originalFilename.substring(originalFilename.lastIndexOf("."));fileExtension变量。这行代码会调用
String newFilename = generateFilename() + fileExtension;generateFilename()方法生成一个新的唯一文件名,例如 "abc123"。- 将生成的文件名 "abc123.xlsx" 与文件扩展名 ".txt" 拼接,赋值给
newFilename变量。假设
File targetFile = new File(uploadPath + File.separator + newFilename);uploadPath是 "/path/to/uploads/"。这行代码会创建一个File对象,代表文件的保存路径和文件名 "/path/to/uploads/abc123.xlsx"。那么这个就会创建出文件了(但是没有内容)这行代码会将用户上传的 "hello.xlsx" 文件的内容,写入到 "/path/to/uploads/abc123.xlsx" 文件中。
file.transferTo(targetFile);通过这样的处理,原本名为 "hello.xlsx" 的文件会被保存为 "abc123.xlsx",并且保存在 "/path/to/uploads/" 目录下。这样可以避免文件名与现有文件发生冲突,确保文件上传的安全性。
注意这里返回给 Controller 层的是一个本地目录,是根据目录来找到指定的文件!
三.假设需求
现在假设我们本地指定的目录下面已经有用户上传的文件了,那么我们要对这个文件进行一系列的处理。 现在假设我们的需求是根据Excel文件中用户的 工号,更新用户的 Flag 标签(0变为1)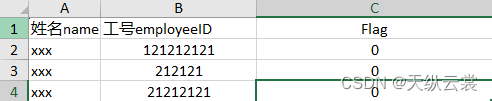
那么应该如何做呢?
继续编写代码
Controller层
@PostMapping("/importExcelUpdateFlag")public Map<String,Object> importExcelUpdateFlag(@RequestBody MultipartFile file) {Map<String,Object> response = new HashMap<>();response.put("code",0);response.put("data",":");//把前端发来的文件数据,传到本机指定的 uploadPath 目录之下String pathAndFileName = jdCloudService.uploadFile(file,uploadPath);if(pathAndFileName.equals("上传文件为空") || pathAndFileName.equals("文件上传失败")) {response.put("msg",pathAndFileName);return response;}String feedBackMsg = jdCloudService.enableFlagUpdate(pathAndFileName);response.put("msg",feedBackMsg);return response;}这里主要是 feedBackMsg,这个调用的 Service 层的代码是处理表格数据的主要内容,我们来看
Service层
@Overridepublic String enableFlagUpdate(String filename) {//获取 PersonSynData 类的 Class 对象。Class<PersonSynData> head = PersonSynData.class;List<PersonSynData> updateList = new ArrayList<>();ExcelReader excelReader = EasyExcel.read(filename, head, new AnalysisEventListener<PersonSynData>() {@Overridepublic void invoke(PersonSynData personSynData, AnalysisContext analysisContext) {updateList.add(personSynData);}@Overridepublic void doAfterAllAnalysed(AnalysisContext analysisContext) {System.out.println("Excel解析完成......");}}).build();//创建 sheet 对象,并且读取Excel的第一个sheet(下表从0开始),也可以根据 sheet 名称获取ReadSheet readSheet = EasyExcel.readSheet(0).build();//读取 sheet 表格数据,参数是可变参数,也可以读取多个sheet//这个操作会读取 excel 表格的数据excelReader.read(readSheet);//需要自己关闭流操作,在读取文件的时候会创建临时文件,如果不关闭的话,会损耗磁盘excelReader.finish();}代码解读:
1.首先获取到实体类的 class 对象,后续需要进行使用
2.updateList 是要存储 Excel 表格中的每一行,每一行都是一个 实体类对象
3. ExcelReader excelReader = EasyExcel.read(filename, head, new AnalysisEventListener<PersonSynData>() {...});是Alibaba提供的一个工厂方法,用于创建一个 ExcelReader 对象。
filename 是要解析的 Excel 文件的路径。
head 是前面获取的 PersonSynData 类的 Class 对象,用于告诉 EasyExcel 应该如何解析 Excel 数据。
new AnalysisEventListener<PersonSynData>() {...} 是一个匿名内部类,实现了 AnalysisEventListener 接口。这个监听器用于处理 Excel 数据的解析过程。4. invoke 是必须重写的方法
- 每解析到一行 Excel 数据,就会调用这个方法,并将解析后的
PersonSynData实例作为参数传递进来。- 在这个方法中,我们将解析出的
PersonSynData实例添加到updateList中。5. doAfterAllAnalysed也是必须重写的方法
- 这个方法是
AnalysisEventListener接口的doAfterAllAnalysed方法的实现。- 当 Excel 文件的所有数据都解析完成后,就会调用这个方法。
- 在这个方法中,我们打印了一条消息,表示 Excel 解析完成。
6.当代码执行到 excelReader.read(readSheet); 此时 updateList 中就有我们需要的数据了
注意!更新操作在下一篇博客: http://t.csdnimg.cn/RUZvM
四.为什么要缓存到本地?
缓存到本地和在内存中进行处理是两种不同的解决方案
在处理前端传来的Excel文件时,后端是否需要将其存储到本地再进行解析,确实存在几种不同的处理方式。
-
存储到本地后再解析:这种方式的优点是可以避免在内存中一次性加载整个Excel文件,从而减轻内存压力。同时,如果需要对文件进行多次处理,存储到本地后可以直接读取而无需重新上传,提高效率。缺点是需要占用服务器硬盘空间,并且需要额外的IO操作。
-
直接在内存中解析:这种方式可以省略存储到本地的步骤,直接从前端传来的数据流中进行解析。优点是减少了IO操作,提高了处理速度。缺点是需要一次性加载整个Excel文件到内存中,如果文件很大可能会造成内存溢出的风险。
综合来看,两种方式各有优缺点。具体采用哪种方式,需要根据实际业务需求、文件大小、服务器资源等因素进行权衡。如果Excel文件较小,且只需要处理一次,直接在内存中解析可能是更好的选择。而对于较大的Excel文件,或需要多次处理的场景,将其存储到本地可能会更合适。总之,在设计后端处理逻辑时,需要充分考虑各种因素,选择最佳的解决方案。
这篇关于Spring Boot + EasyExcel + SqlServer 进行批量处理数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





