本文主要是介绍RocketMQ查询出重复数据,两条MessageID一样的解决办法如下,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题描述
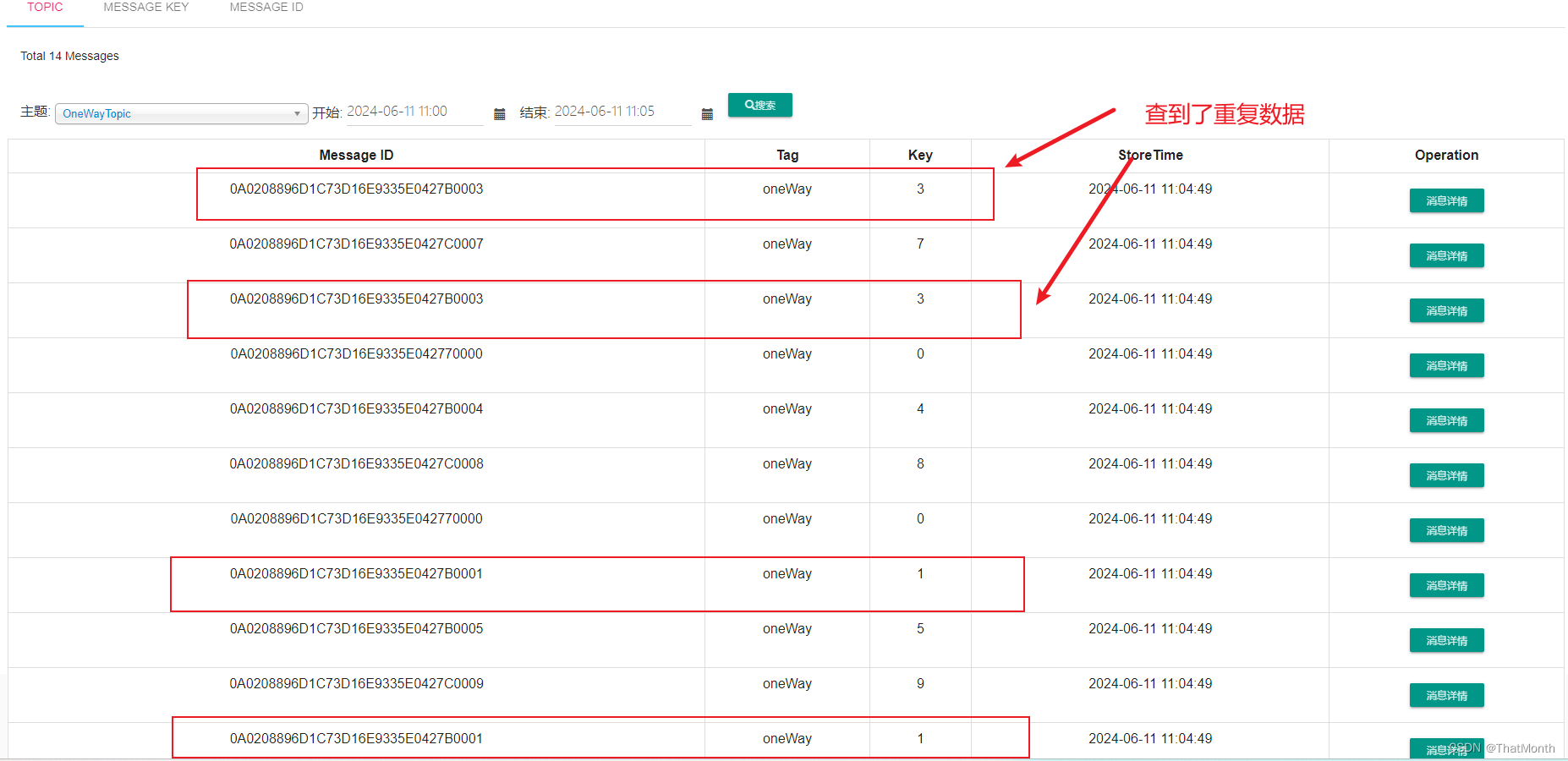
在使用RocketMQ的可视化工具dashboard-1.0.0时,首先生产了10条数据,但是查询时却查出来了14条,有四条数据重复,重复数据MessageID和key相同,但是通过key单独查询却只能查出一条
测试代码
package com.fdw.rocketmq.producer;import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.remoting.exception.RemotingException;public class OneWayProducer {public static void main(String[] args) throws MQClientException, RemotingException, InterruptedException {int messageCount = 10;DefaultMQProducer producer = new DefaultMQProducer("pg");producer.setNamesrvAddr("127.0.0.1:9876");// 设置发送超时时限为5s,默认3sproducer.setSendMsgTimeout(5000);
这篇关于RocketMQ查询出重复数据,两条MessageID一样的解决办法如下的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







