本文主要是介绍Redis Cluster迁移目标节点宕机下填坑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自 听滴滴大神讲解redis cluster数据迁移遇到的坑
问题背景
应@冬洪兄邀请,让我把最近在处理Redis Cluster中遇到的坑分享下,由于个人时间问题,大致整理了一个比较大,比较坑的问题,它可能会导致集群部分slot不可用,甚至需要重建集群。如果对redis cluster不了解的可以查看redis原理分享。
架构图如下 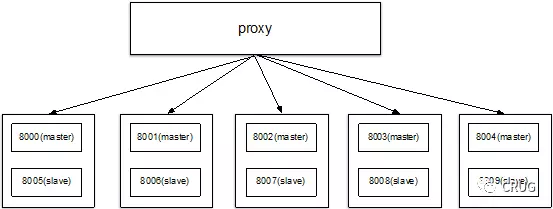

1. 迁移8000实例的数据到8001实例
2.此时kill掉8001实例模拟目标节点宕机

3.连接8000实例查看cluster nodes发现8001实例已经fail,但是还负责槽166-234
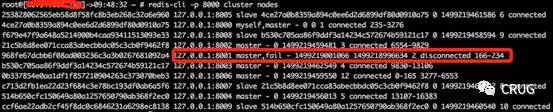
4.连接8002端口查看cluster nodes发现8001实例已经fail,但是还负责槽166-234

5.连接8003端口查看cluster nodes发现8001实例已经fail,但是还负责槽166-234
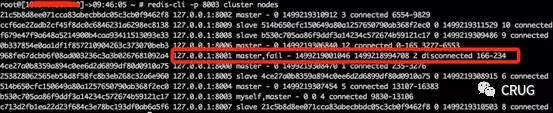
6. 连接8004端口查看cluster nodes发现8001实例已经fail,但是还负责槽166-234
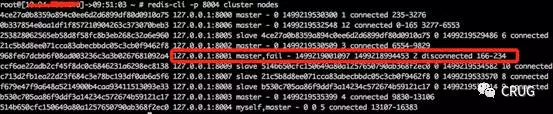
7. 连接8006端口(8001的slave升级为master)cluster nodes发现8001实例已经fail,但是槽166-234,在8000实例(源节点上)
问题-
8000实例迁移数据到8001实例
-
kill掉8001实例(目标节点)
-
发现8001机器从ok->fail, 但是仍然负责一部分槽号166-234
-
新的slave(8006)正常升级为master
-
8000实例:认为槽166-234在8001实例上
-
8002实例:认为槽166-234在8001实例上
-
8003实例:认为槽166-234在8001实例上
-
8004实例:认为槽166-234在8001实例上
-
8005实例:认为槽166-234在8001实例上
-
8006实例:认为槽166-234在8000实例上
说明:
只有宕机的8001实例的slave8006升级为master之后,认为槽166-234在(8000实例)源节点上,其他的master节点均认为该槽166-234在(8001实例)目标节点上。
修复步骤1.此时通过redis-trib.rbfix 127.0.0.1:8002,不成功,报错如下

2.在8001实例(源节点)上强制把166-234指向自己,并且让大家强制同意
cluster setslot 166 node4ce27a0b8359a894c0ee6d2d6899df80d0910a75
cluster setslot 234 node4ce27a0b8359a894c0ee6d2d6899df80d0910a75
cluster bumpepoch
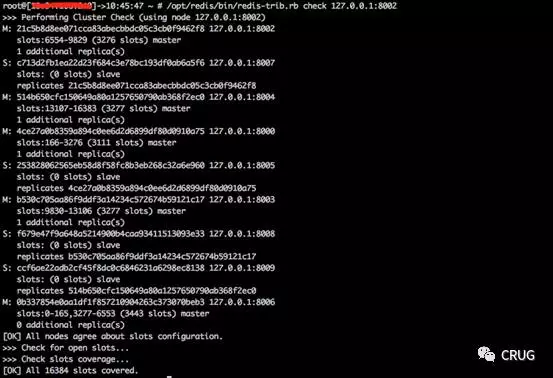
3.redis-trib.rb check集群
1. 植入日志打印slot->nodeid信息cluster.c clusterUpdateSlotsConfWith函数

2.查询部署的clusternodes(此时,已经模拟完迁移的时候,目标节点宕机)
3.分析8000实例日志信息142槽
4.分析8002实例日志信息142槽
5.分析8003实例日志信息142槽
6.分析8004实例日志信息142槽
7.分析8005实例日志信息142槽
8.分析8006实例日志信息142槽
9.分析8007实例日志信息142槽
10.分析8008实例 日志信息142槽
11.分析8009实例 日志信息142槽
说明:
迁移完的槽142, 除了8006实例(8001实例的slave升级为master的实例),其他所有的master节点都认为8001实例目标节点。
所有的slave节点和新的master实例8006都认为槽142在8000实例源节点。
总结由于迁移速度比较快,虽然迁移完毕了,但是也需要一段时间同步给其他节点。而这个信息靠新的owner来同步,此时还没来得及gossip消息传播。有可能迁移结束了, 但是这个槽信息同步到了除了slave的所有节点上面。总体来说redis cluster问题还是不少的。
在扩容的时候也遇到过脑裂的请情况,投票各自占一半的情况,最后也是通过手动强制指定slot来修复的。还有更多小问题就不细说了。
这篇关于Redis Cluster迁移目标节点宕机下填坑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






