本文主要是介绍AMD在行动:揭示应用程序跟踪和性能分析的力量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AMD in Action: Unveiling the Power of Application Tracing and Profiling — ROCm Blogs
导言
Rocprof是一款强大的工具,设计用于分析和优化基于AMD ROCm平台上运行的HIP程序的性能,帮助开发者找出并解决性能瓶颈。Rocprof提供了多种性能数据,包括性能计数器、硬件追踪和运行时API/活动追踪等。
Rocprof是一个命令行界面(CLI)分析器,可以用于在支持ROCm的GPU上运行的应用程序,无需对应用程序代码进行任何修改。Rocprof CLI允许用户通过ROCm提供的API(如HIP或HSA)跟踪整个GPU启用应用程序的执行。
Rocprof是ROCm软件堆栈的一部分。它默认包含在基础ROCm安装包中。目前有两个版本的Rocprof:ROCProfilerV1和ROCProfilerV2(beta版本,可能会变化)。在这篇博客中我们考虑的是ROCProfilerV1,因为它是第一个也是当前用于HIP应用程序的分析工具版本。
要了解有关Rocprof及其版本的更多信息,可以访问以下链接:
• ROCProfiler (Rocprof) 文档 ROCProfiler documentation — rocprofiler 2.0.0 Documentation
• Rocprof:官方AMD GitHub库 GitHub - ROCm/rocprofiler: ROC profiler library. Profiling with perf-counters and derived metrics.
你可以在下面的GitHub文件夹中找到与这篇博客文章相关的文件:rocm-blogs/blogs/software-tools-optimization/roc-profiling at release · ROCm/rocm-blogs · GitHub
操作系统、硬件和软件需求
• AMD GPU:支持的操作系统和硬件列表在ROCm文档页面上 System requirements (Linux) — ROCm installation (Linux)
• ROCm 6.0:本博客是在ROCm 6.0下创建的。有关ROCm安装说明,可参考 ROCm installation for Linux — ROCm installation (Linux)
• Docker:用于Ubuntu的Docker引擎
前言
让我们将这个博客的代码库克隆到本地系统:
git clone https://github.com/ROCm/rocm-blogs.git然后移动到以下位置:
cd ./rocm-blogs/blogs/software-tools-optimization/roc-profiling我们还将使用官方AMD Docker镜像:
rocm6.0.2_ubuntu22.04_py3.10_pytorch_2.1.2 https://hub.docker.com/r/rocm/pytorch/tags 在容器中执行性能分析任务。在克隆仓库的相同目录中,执行以下命令启动容器:
docker run -it --rm --name=my_rocprof --cap-add=SYS_PTRACE --cap-add=CAP_SYS_ADMIN --security-opt seccomp=unconfined --device=/dev/kfd --device=/dev/dri --group-add video --ipc=host --shm-size 8G -v $(pwd):/workdir -w /workdir rocm/pytorch:latest以下是启动容器时应用的一些设置的定义:
• -it:这种`-i`和`-t`的组合允许通过终端与容器互动。
• --cap-add=SYS_PTRACE 和 --cap-add=CAP_SYS_ADMIN:分别授予容器追踪系统调用和系统监控的能力。
• --device=/dev/kfd --device=/dev/dri:这些选项允许访问主机上特定的设备。`--device=/dev/kfd`与AMD GPU设备相关联,`--device=/dev/dri`与直接访问图形硬件的设备相关联。
• --group-add video:这个选项允许容器有必要的权限直接访问视频硬件。
• -v $(pwd):/workdir -w /workdir:这将主机上的卷挂载到容器中。它将主机上的当前目录`$(pwd)`映射到容器内的`/workdir`中,并设置它(`-w /workdir`)为工作目录。Rocprof的输出结果将保留在本地供稍后使用和探索。
• rocm/pytorch:这是镜像的名称。
此外,我们将使用以下PyTorch脚本,在AMD GPU上执行两个1-D张量的加法。我们的计划是通过收集HIP、HSA和系统跟踪来对加法操作执行性能分析,以说明如何在AMD硬件上进行应用程序跟踪和性能分析。以下名为`vector_addition.py`的脚本存在于克隆仓库的`src`文件夹中。
import torchdef vector_addition():A = torch.tensor([1,2,3], device='cuda:0')B = torch.tensor([1,2,3], device='cuda:0')C = torch.add(A,B)return Cif __name__=="__main__":print(vector_addition())应用程序跟踪与Rocprof
让我们开始使用Rocprof进行应用程序跟踪吧。跟踪输出通常是一份应用程序执行期间发生事件的时间顺序记录(跟踪)。应用程序跟踪通过收集API调用和GPU命令(如内核执行和异步内存复制)的执行时间数据,提供程序执行的全景视图。这些信息可作为分析流程的第一步,回答诸如“在内存复制上花费了多少时间百分比”以及“哪个内核执行时间最长”等问题。
让我们探索使用Rocprof可以完成的三种不同类型的跟踪:HIP跟踪、HSA跟踪和系统跟踪。
HIP跟踪
HIP(Heterogeneous-Compute Interface for Portability)是AMD开发的一种编程模型,通过C++ API和内核语言,创建可在AMD和NVIDIA GPU上移植的应用程序。
HIP跟踪指的是Rocprof应用程序选项,专门用于跟踪和分析GPU上的HIP应用程序性能。它可以收集关于HIP应用程序与GPU交互的详细信息,包括API调用、内存交易和内核执行。HIP跟踪对于优化HIP应用程序的性能至关重要,有助于识别瓶颈,并提升GPU利用率的整体效率。
示例:在GPU上加两个PyTorch张量时收集HIP跟踪
收集HIP跟踪
让我们在运行的docker容器中使用之前定义的脚本来收集HIP跟踪。首先在容器内创建一个新目录,用于存储跟踪输出:
mkdir HIP_trace && cd ./HIP_trace接下来运行Rocprof:
rocprof --tool-version 1 --basenames on --hip-trace python ../src/vector_addition.py终端的输出将类似于:
RPL: on '240228_201148' from '/opt/rocm-6.0.0' in '/workdir/HIP_trace'
RPL: profiling '"python" "../vector_addition.py"'
RPL: input file ''
RPL: output dir '/tmp/rpl_data_240228_201148_496'
RPL: result dir '/tmp/rpl_data_240228_201148_496/input_results_240228_201148'
ROCtracer (517):HIP-trace(*)
tensor([2, 4, 6], device='cuda:0')
...完成后,你将在`HIP_trace`文件夹中找到多个文件,如:
-rw-r--r-- 1 root root 161 Feb 28 20:11 results.copy_stats.csv
-rw-r--r-- 1 root root 69632 Feb 28 20:11 results.db
-rw-r--r-- 1 root root 848 Feb 28 20:11 results.hip_stats.csv
-rw-r--r-- 1 root root 107598 Feb 28 20:11 results.json
-rw-r--r-- 1 root root 97 Feb 28 20:11 results.stats.csv
-rw-r--r-- 1 root root 53543 Feb 28 20:11 results.sysinfo.txt在分析输出文件之前,让我们快速描述执行`rocprof`命令时的选项:
• --tool-version 1:显式设置为rocprofv1(默认为rocprofv1)。
• --basenames on:设置为开启,截断内核函数的完整名称。
• --hip-trace:用于跟踪HIP,生成API执行统计和JSON文件。
• python ../scr/vector_addition.py:这是我们想要分析的应用程序。
让我们回到分析`rocprof`输出,尤其是`results.json`文件。
可视化HIP跟踪
我们可以可视化刚刚创建的`results.json`文件中的HIP跟踪。或者,你也可以在克隆的仓库目录`$(pwd)/HIP_trace`中探索`tracing_output_examples`目录下的跟踪示例。
让我们打开本地的 Chrome 浏览器 并访问 chrome://tracing/。这将打开 Chrome 浏览器内置的工具,该工具旨在记录和分析性能数据。让我们加载 results.json 文件(位于克隆仓库目录 $(pwd)/HIP_trace 中):
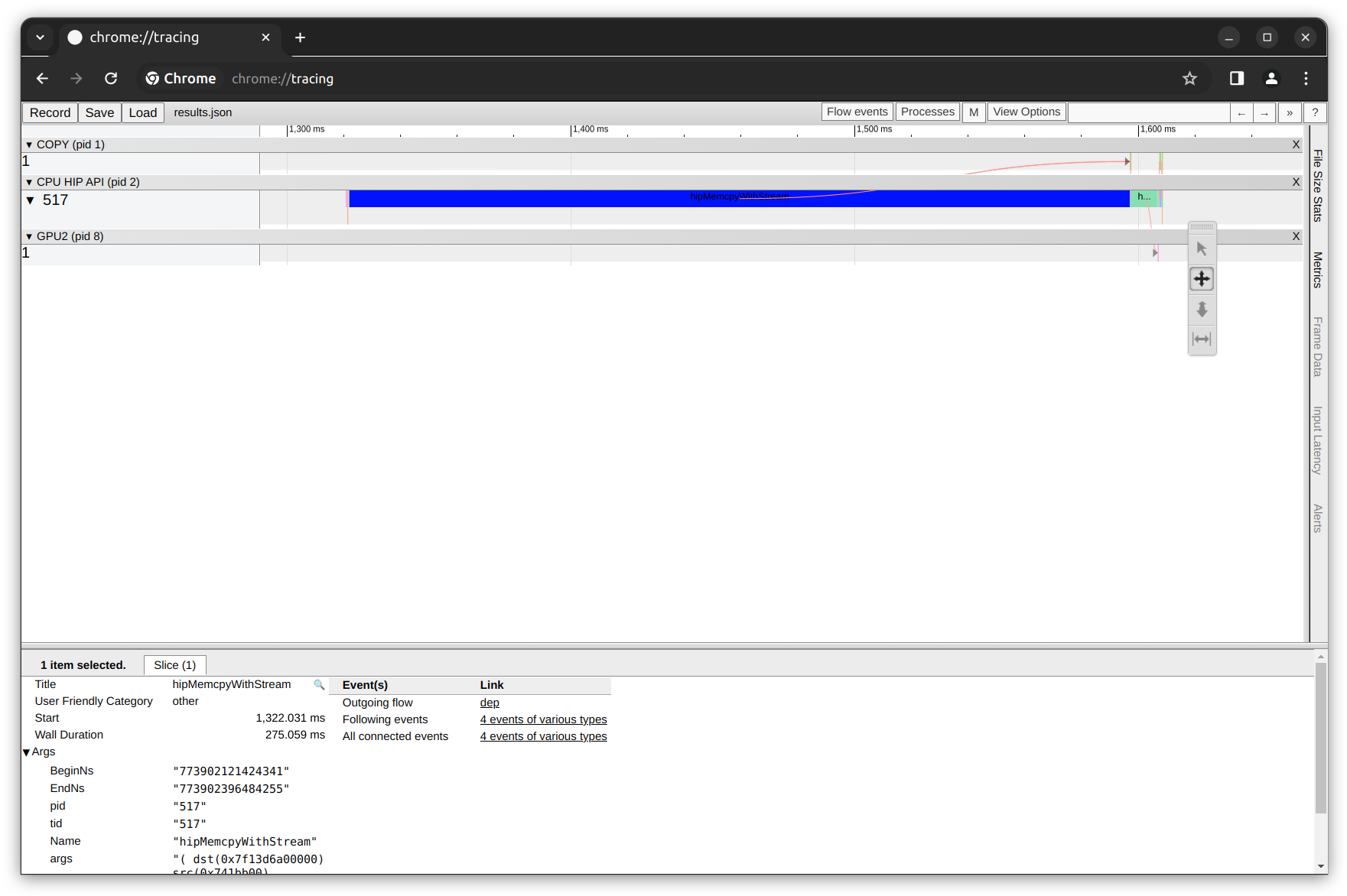
在上图中,可以看到顶部的时间轴,时间轴下方是显示每个任务持续时间的甘特图样式框。有三行任务由黑色行分隔,上面标明了它们的类别:
• 第一行标题为“COPY”,显示了由复制引擎完成的任务。
• 第二行是“CPU HIP API”,列出了每个API跟踪的执行时间。
• 第三行显示了“GPU”任务。
通过放大并专注于GPU任务(使用`W` S A D键盘键),我们可以观察到`elementwise_kernel`执行的持续时间。记住,我们的Python脚本接受两个PyTorch张量,并在GPU上执行逐元素加法操作。
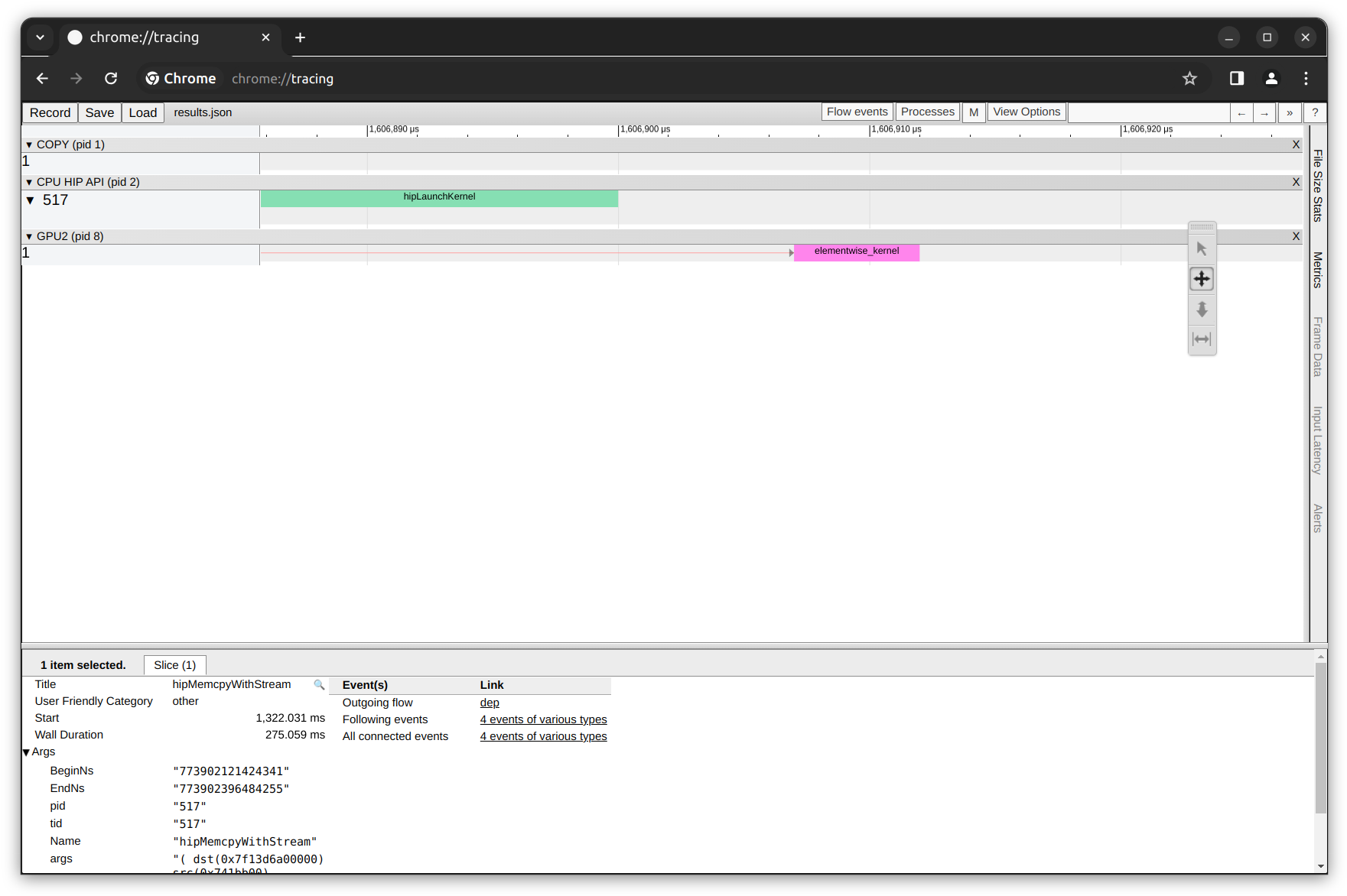
HIP轨迹数据库和基本统计
Chrome跟踪允许我们可视化`results.json`文件内的轨迹。其他输出文件的内容如下:
• results.hip_stats.csv:包含每个HIP API调用使用的时间的基本统计信息(`TotalDurationNs`、`AverageNs`、`Percentage`)。
• results.stats.csv:包含每个内核函数调用使用的时间的基本统计信息(`TotalDurationNs`、`AverageNs`、`Percentage`)。在我们的例子中,我们只有一个调用`elementwise_kernel`的情况。
• results.copy_stats.csv:包含`CopyDeviceToHost`和`CopyHostToDevice`任务使用的时间的基本统计信息(`TotalDurationNs`、`AverageNs`、`Percentage`)。
• results.sysinfo.txt:包含工具`rocminfo`报告的rocm系统信息
• results.db:包含与`results.json`相同的结果,但以数据库文件格式存储。
例如,在`results.hip_stats.csv`文件中有以下统计信息:
| Name | Calls | TotalDurationNs | AverageNs | Percentage |
|---|---|---|---|---|
| hipMemcpyWithStream | 6 | 276004952 | 46000825 | 96.61022910354737 |
| hipLaunchKernel | 1 | 9406206 | 9406206 | 3.2924616390765404 |
| hipMalloc | 1 | 143338 | 143338 | 0.05017271218830984 |
| hipModuleLoad | 24 | 82438 | 3434 | 0.02885583758235699 |
| hipGetDevicePropertiesR0600 | 8 | 16118 | 2014 | 0.005641796139552512 |
| hipGetDevice | 48 | 9109 | 189 | 0.0031884303905685466 |
| hipDevicePrimaryCtxGetState | 24 | 6140 | 255 | 0.002149188999680632 |
| hipStreamIsCapturing | 1 | 5950 | 5950 | 0.002082683151156313 |
| hipDeviceGetStreamPriorityRange | 1 | 5880 | 5880 | 0.0020581809964368264 |
| hipSetDevice | 12 | 3849 | 320 | 0.0013472684787900248 |
| hipGetDeviceCount | 5 | 2720 | 544 | 0.0009520837262428858 |
| __hipPushCallConfiguration | 1 | 1230 | 1230 | 0.00043053786149954026 |
| hipGetLastError | 2 | 710 | 355 | 0.0002485218550119298 |
| __hipPopCallConfiguration | 1 | 520 | 520 | 0.0001820160064876105 |
我们可以观察到,大部分的消耗时间发生在内存复制操作期间。
尽管这是一个小例子,其中两个向量在GPU上相加,但在更复杂的例程中,可以通过在GPU上完成大部分工作来优化内存复制操作,以避免多次在CPU和GPU之间来回传输数据。另一个选择是在任何计算之前就在GPU内准备好数据,这样当需要使用数据时就不必等待数据的移动。
最后,由于我们可以访问`results.db`数据库中的所有轨迹数据,我们可以使用SQL来计算`results.hip_stats.csv`中的统计信息和其他统计数据,取决于我们正在尝试进行的分析类型。
HSA跟踪
HSA(异构系统架构)是一套针对将CPU和GPU(以及其他处理器)集成到单一统一架构中的处理器的规范和设计。它便于直接访问CPU和GPU的计算能力,并具有共享的虚拟内存。
HSA跟踪涉及收集利用HSA架构的应用程序的运行时信息。这可能包括HSA内核的执行细节、CPU和GPU之间的数据传输以及与HSA运行时的交互。HSA轨迹包含了HSA运行时API调用的开始/结束时间及其异步活动。
示例:在GPU上添加两个PyTorch张量时收集HSA轨迹
收集HSA轨迹
根据前面的讨论,现在让我们使用前面定义的相同脚本,用Rocprof收集HSA轨迹。再次在运行的docker容器中,让我们返回到原始目录:
cd ..并创建一个新目录以包含跟踪输出:
mkdir HSA_trace && cd ./HSA_trace然后以HSA跟踪模式运行Rocprof:
rocprof --tool-version 1 --basenames on --hsa-trace python ../src/vector_addition.py终端的输出会类似于:
RPL: 在'/workdir/HSA_trace' 中从 '/opt/rocm-6.0.0' 的 '240229_171038' 开始
RPL: 正在对'"python" "../vector_addition.py"'进行分析
RPL: 输入文件 ''
RPL: 输出目录 '/tmp/rpl_data_240229_171038_12'
RPL: 结果目录 '/tmp/rpl_data_240229_171038_12/input_results_240229_171038'
ROCtracer (33):
ROCProfiler: 从 "/tmp/rpl_data_240229_171038_12/input.xml" 输入0个度量HSA-trace(*)HSA-activity-trace()
tensor([2, 4, 6], device='cuda:0')
...这将为您提供相应的HSA跟踪输出:
-rw-r--r-- 1 root root 90 2月 29 17:10 results.copy_stats.csv
-rw-r--r-- 1 root root 354 2月 29 17:10 results.csv
-rw-r--r-- 1 root root 5423104 2月 29 17:10 results.db
-rw-r--r-- 1 root root 2258 2月 29 17:10 results.hsa_stats.csv
-rw-r--r-- 1 root root 14611378 2月 29 17:10 results.json
-rw-r--r-- 1 root root 97 2月 29 17:10 results.stats.csv
-rw-r--r-- 1 root root 53543 2月 29 17:10 results.sysinfo.txt让我们快速浏览Chrome跟踪中相应的HSA-Trace results.json 文件:

在上面的图中,您可以看到HSA跟踪行。在这个特定的案例中,它由单个线程组成,线程ID为33,其中每个彩色段展示了线程中每个内核执行的持绑。我们还观察到与HIP API调用相比,有更多的HSA API调用,因为HSA提供了更直接的访问CPU、GPU和其他处理器的底层硬件特性。
最后,现在您可以按照探索和分析HIP轨迹的相同步骤,进行剩余的HSA轮迹输出文件的分析。
系统跟踪
如果我们想同时生成并收集HIP追踪和HSA追踪怎么办?Rocprof工具也可以使用sys-trace选项同时生成HIP和HSA追踪,不过付出的代价是追踪收集时间更长。
总的来说,你可以按照上面HIP和HSA追踪相同的步骤进行追踪分析。生成系统追踪的相应命令是:
cd ..
mkdir SYS_trace && cd ./SYS_trace
rocprof --tool-version 1 --basenames on --sys-trace python ../src/vector_addition.py追踪可视化的替代方法
一个替代`chrome://tracing/`用于追踪可视化和分析的工具是Perfetto。Perfetto是一个开源的性能追踪和分析工具。它允许用户可视化和探索追踪和性能数据。Perfetto提供用于记录和分析系统级和应用级追踪的服务和库。它还支持从多样的系统接口可视化性能数据,包括内核事件、进程范围和系统范围的CPU和内存计数器。
例如,使用Perfetto将`results.json`文件中的HIP追踪可视化可能看起来如下:
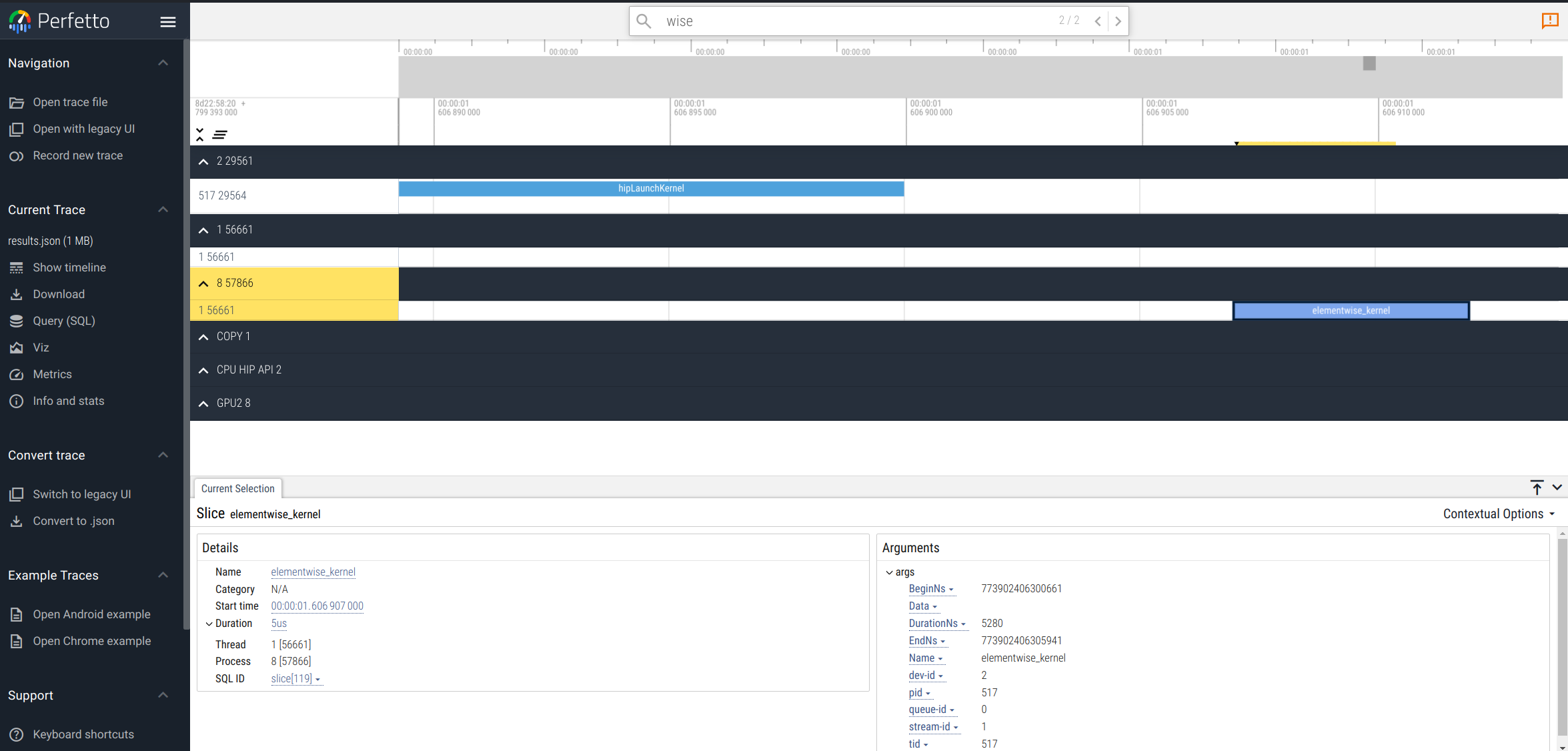
有关Perfetto的更多信息,你可以查看官方文档。
使用Rocprof进行应用程序分析
应用程序分析旨在测量和分析性能指标,以识别GPU内核集中存在的瓶颈和优化机会。这与应用程序追踪形成对比,其目的是理解应用程序执行流程和操作及内核执行的时间。
性能计数器收集
如上节所述,应用程序追踪模式仅限于提供程序执行概览,并不能洞察内核执行。为了解决性能问题,可以使用Rocprof的计数器和度量收集功能,在内核执行期间报告硬件组件性能指标。
检查支持计数器和度量收集的AMD GPU列表。
性能计数器和派生度量
AMD GPU配备了可以在内核执行期间用来测量特定值的硬件性能计数器。这些性能计数器根据GPU而异。建议在运行配置文件之前检查可以在GPU上收集的硬件基础计数器和派生度量的列表。
要获取支持的基础计数器列表,我们可以使用:
rocprof --list-basicAMD Instinct MI210 GPU的一些基础计数器包括:
• *GRBM_COUNT*:图形寄存器总线管理器计数器,测量自由运行的GPU周期数。
• *SQ_WAIT_INST_LDS*:等待LDS指令发出的波形周期数。以4个周期的单位。(每个simd,不确定性)
• *GRBM_CP_BUSY*:命令处理器(CPG/CPC/CPF)任何一个模块都处于繁忙状态。
同样地,派生度量是通过使用数学表达式来从基础计数器计算得出的。要列出支持的派生度量及其数学表达式,使用:
rocprof --list-derived"AMD Instinct MI210 GPU"的一些派生度量包括:
• *MemUnitStalled*:内存单元处于停滞状态的GPUTime百分比。值范围:0%(最佳)至100%(差)。
• MemUnitStalled = 100*max(TCP_TCP_TA_DATA_STALL_CYCLES,16)/GRBM_GUI_ACTIVE/SE_NUM
• *MeanOccupancyPerActiveCU*:每个活动计算单元的平均占用率。
• MeanOccupancyPerActiveCU = SQ_LEVEL_WAVES*0+SQ_ACCUM_PREV_HIRES*4/SQ_BUSY_CYCLES/CU_NUM
• *TA_TA_BUSY_sum*:TA模块忙碌。性能窗口ing不支持此计数器。TA实例的总和。
• TA_TA_BUSY_sum = sum(TA_TA_BUSY,16)
性能计数器和派生度量的命名反映了GPU的不同硬件特性和执行模型。用户预期需要了解硬件特性和细节,以便能够使用它们来识别优化机会。例如,在上面的例子中,“TA”代表“纹理寻址器”,负责接收内存请求,知道它忙碌是一个迹象表明内核正在发出许多请求,这反过来可能表明GPU内存带宽被有效使用。
例子:GPU应用程序中的内核性能分析
让我们继续进行GPU内核的性能分析,首先定义性能分析的范围。为此,我们需要提供一个输入文本文件,该文件用于向Rocprof提供哪些基础计数器和派生度量需要收集的信息。它包括四个部分:
• 要使用的基础计数器/派生度量
• 要分析的GPU
• 要被分析的内核名称
• 要分析的内核范围。如果我们感兴趣的内核执行了多次,每次执行都是一个内核派发。在这种特殊情况下,我们对分析第一次执行感兴趣。
就我们的PyTorch张量加法的特定案例而言,我们的`input.txt`文件如下所示:
# 性能计数器组 1
pmc: GRBM_COUNT, MemUnitStalled
gpu: 0
kernel: elementwise_kernel
range: 0:1让我们开始对执行PyTorch张量加法操作时我们知道正在执行的`elementwise_kernel`进行性能分析:
rocprof --tool-version 1 --basenames on -o output.csv -i input.txt python ../src/vector_addition.py控制台输出将类似于:
RPL: 在'/workdir/counters_metrics'下的'/opt/rocm-6.0.0'上的'240229_204656'
RPL: 正在对'"python" "../vector_addition.py"'进行分析
RPL: 输入文件'../input.txt'
RPL: 输出目录'/tmp/rpl_data_240229_204656_28'
RPL: 结果目录'/tmp/rpl_data_240229_204656_28/input0_results_240229_204656'
tensor([2, 4, 6], device='cuda:0')
ROCProfiler: 输入来自"/tmp/rpl_data_240229_204656_28/input0.xml"gpu_index = 0kernel = range = 2个度量GRBM_COUNT, MemUnitStalledROCPRofiler: 收集了1个上下文,输出目录/tmp/rpl_data_240229_204656_28/input0_results_240229_204656
文件'/workdir/counters_metrics/output.csv'正在生成output.csv文件内容的一些列内容是如下所示:

| Index | KernelName | gpu-id | queue-id | queue-index | pid | tid | grd | wgr | lds | scr | arch_vgpr | accum_vgpr | sgpr | wave_size | sig | obj | GRBM_COUNT | MemUnitStalled |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | “elementwise_kernel” | 2 | 0 | 0 | 158 | 158 | 256 | 256 | 0 | 0 | 28 | 4 | 32 | 64 | 0x0 | 0x7fd615a43240 | 11656 | 0.1479924502 |
在上面的输出中,我们可以观實到`output.csv`文件的最后两列对应于`input.txt`文件中定义的`GRBM_COUNT`计数器和`MemUnitStalled`度量值。
最后,`output.csv`文件的每一行都是内核执行的一个实例。`output.csv`中一些列的描述包括:
• 索引 - 内核派发顺序索引
• 内核名称 - 内核名称
• gpu-id - 提交内核的GPU ID
• 队列-id - 提交内核的ROCm队列唯一id
• 队列索引 - 提交AQL数据包的ROCm队列写入索引
• pid - 进程id
• tid - 提交内核的系统应用程序线程id
• grd - 内核的网格大小
• wgr - 内核的工作组大小
• lds - 内核的LDS(本地数据共享)内存大小
• scr - 内核的刮痕内存大小
• vgpr - 内核的VGPR(向量通用目的寄存器)大小
• sgpr - 冨核的SGPR(标量通用目的寄存器)大小
• wave_size - 波大小
• sig - 内核的完成信号
总结
深入探索AMD硬件上应用程序追踪和分析的复杂性,为我们提供了对张量操作性能和效率以及AMD工具提供的洞察数据的独特视角。这种探索不仅强调了理解硬件在计算中的作用的重要性,也突出了AMD在提供优化洞察数据方面的能力。
这篇关于AMD在行动:揭示应用程序跟踪和性能分析的力量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





