本文主要是介绍私有化AI搜索引擎FreeAskInternet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

什么是 FreeAskInternet
FreeAskInternet是一个完全免费、私有且本地运行的搜索聚合器,并使用LLM生成答案,无需GPU。用户可以提出问题,系统将使用searxng进行多引擎搜索,并将搜索结果合并到ChatGPT3.5 LLM中,并根据搜索结果生成答案。所有进程都在本地运行,不需要GPU或OpenAI或Google API密钥。
软件特点
- 🈚完全免费(不需要任何 API 密钥)
- 💻 完全本地(无需 GPU,任何计算机都可以运行)
- 🔐 完全私有(所有事情都在本地运行,使用自定义 llm)
- 👻 在没有 LLM 硬件的情况下运行(不需要 GPU!)
- 🤩 使用免费聊天GPT3.5,Qwen,Kimi,ZhipuAI(GLM)API(无需API密钥!Thx OpenAI)
- 🐵 自定义LLM(ollama,llama.cpp)支持,是的,我们喜欢ollama!
- 🚀 使用Docker Compose快速轻松地部署
- 🌐 网络和移动友好界面,专为网络搜索增强的人工智能聊天而设计,允许从任何设备轻松访问。
之所以不要 OpenAI 或 Google API 密钥,是因为借助了 freegpt35、kimi-free-api、glm-free-api、qwen-free-api 等项目的帮助
而之所以不需要 GPU,则是因为用的是白嫖的线上大模型
所以个人研究使用就好,不要放在公网上
前言
在折腾 SearXNG 时,老苏提到过 FreeAskInternet。因为 SearXNG 元搜索引擎受网络影响比较大,所以老苏当时是不打算写基于 SearXNG 的 AI 搜索应用的,比如:FreeAskInternet、Farfalle 等
文章传送门:互联网元搜索引擎SearXNG
但转念一想,爱折腾的人,一个科学的网络(稳不稳定先放一边),应该是基本的配置吧 🙂
老苏把折腾的过程写出来,折腾或者不折腾,大家自己量力而行
安装
在群晖上以 Docker 方式安装。
涉及到多个容器,所以采用 docker-compose 安装方式,老苏根据自己的需要,对官方给的 docker-compose.yml 做了比较大的调整
官方完整的
docker-compose.yml:https://github.com/nashsu/FreeAskInternet/blob/main/docker-compose.yaml
- 利用了已经安装的
kimi-free-api,而且是通过One-API进行管理的,这个好处是,只要更改模型名称就可以切换不同的模型
文章传送门:大模型接口管理和分发系统One API
- 去掉了
chatgpt-next-web,因为这个老苏也是单独安装的,如果你希望能通过chatgpt-next-web使用SearXNG搜索的结果,理论上可以将backend的端口暴露出来,但老苏没试过
文章传送门:跨平台私人ChatGPT应用ChatGPT-Next-Web
将下面的内容保存为 docker-compose.yml 文件
version: '3'services:backend:image: nashsu/free_ask_internet:latestcontainer_name: free_ask_internet_backendports:- "3132:8000"restart: on-failurefreeaskinternet-ui:image: nashsu/free_ask_internet_ui:latestcontainer_name: free_ask_internet_uiports:- "3133:80"environment:BACKEND_HOST: "backend:8000"depends_on:- backendrestart: alwayssearxng:image: searxng/searxng:latestcontainer_name: free_ask_internet_searxng# ports:# - "3135:8080"volumes:- ./searxng:/etc/searxng:rwenvironment:- SEARXNG_BASE_URL=https://${SEARXNG_HOSTNAME:-localhost}/cap_drop:- ALLcap_add:- CHOWN- SETGID- SETUIDlogging:driver: 'json-file'options:max-size: '1m'max-file: '1'restart: always
然后执行下面的命令
# 新建文件夹 freeaskinternet 和 子目录
mkdir -p /volume1/docker/freeaskinternet/searxng# 进入 freeaskinternet 目录
cd /volume1/docker/freeaskinternet# 将 docker-compose.yml 放入当前目录# 一键启动
docker-compose up -d

运行
在浏览器中输入 http://群晖IP:3133 就能看到主界面

第一当然是选择模型了,因为我们没有安装 freegpt35、kimi-free-api、glm-free-api、qwen-free-api,所以上面的不用管,直接勾选 使用自定义模型
URL部分,因为老苏用的是One API+kimi-free-api,所以这里填的是One API的地址model auth token:填的是One API的访问令牌model name:填的是渠道中的模型名称
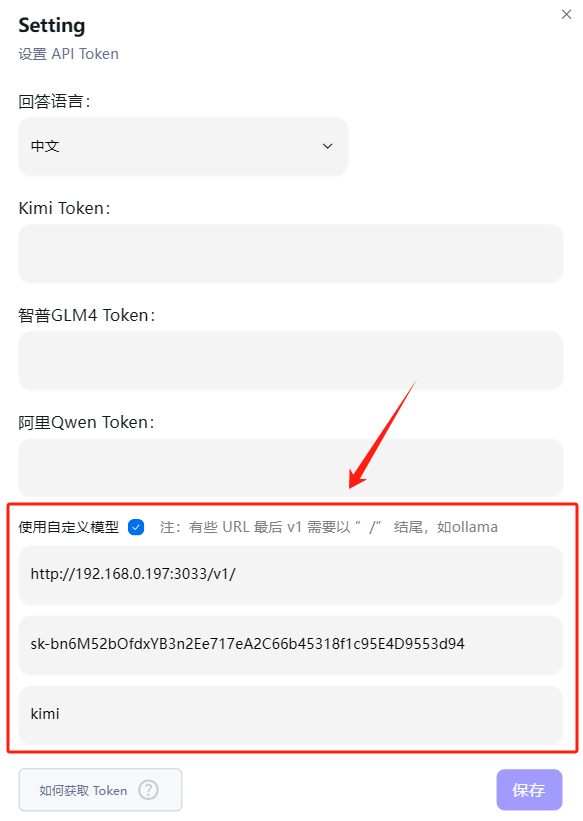
保存之后,模型就灰掉了

开始第一个问题,但是你会发现,一直卡在这个界面

一开始,老苏也以为是网络问题,但实际上并不是,不信的话,你可以打开 searxng 的端口,访问 http://群晖IP:3135 ,随便搜索一个试试
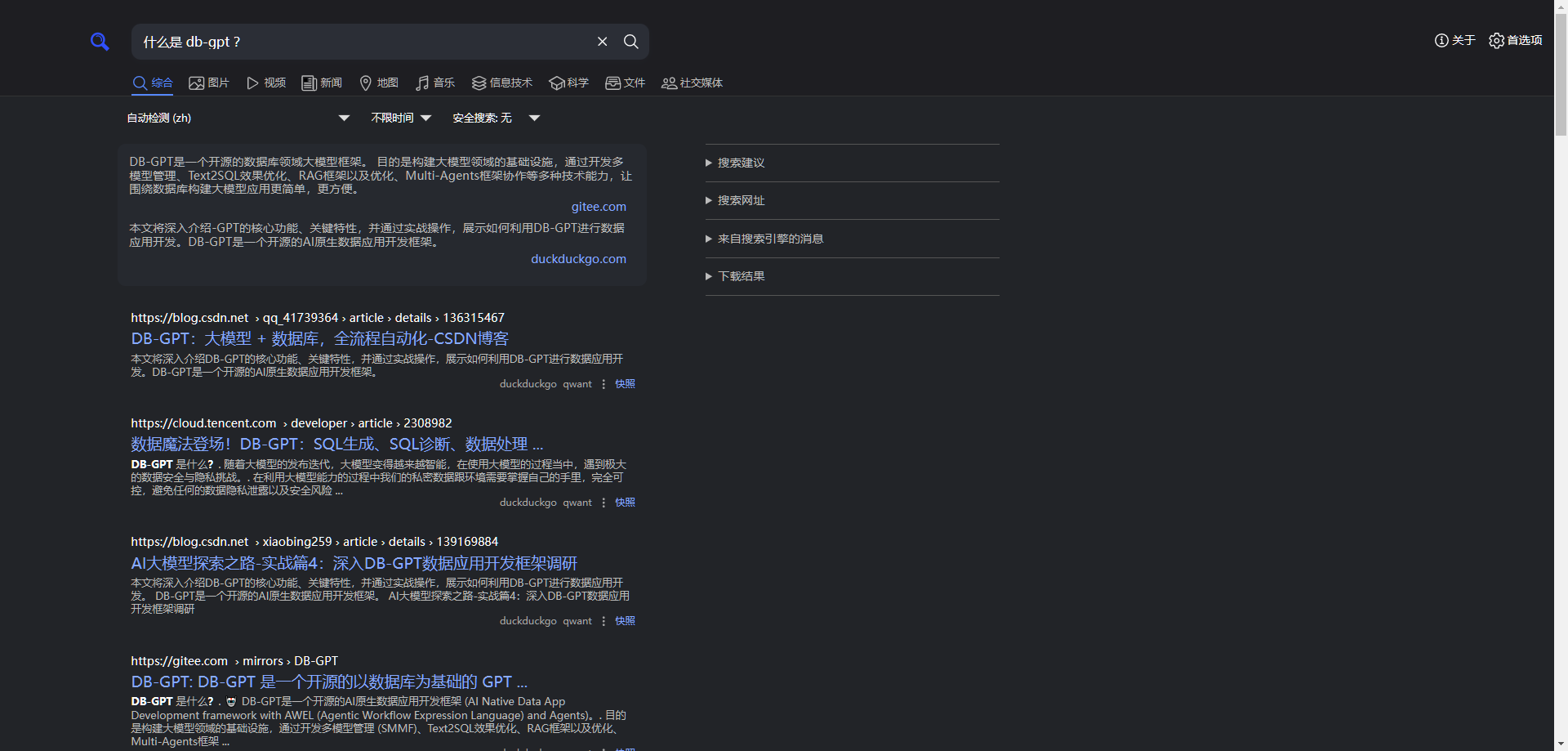
老苏仔细查看了 backend 的日志,发现了有这么一条
requests.exceptions.HTTPError: 403 Client Error: FORBIDDEN for url: http://searxng:8080/search?q=%3Aall+%21general+%E4%BB%80%E4%B9%88%E6%98%AF+FreeAskInternet&format=json
在浏览器中直接输入 http://群晖IP:3135/search?q=%3Aall+%21general+%E4%BB%80%E4%B9%88%E6%98%AF+FreeAskInternet&format=json
确实是没权限访问的,这才是导致界面卡住的根本原因

找到了问题,解决起来就容易多了,找到 searxng 目录下的 settings.yml 文件
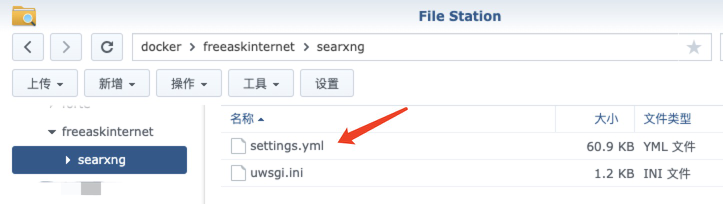
首先需要修改文件的权限,否则保存不了
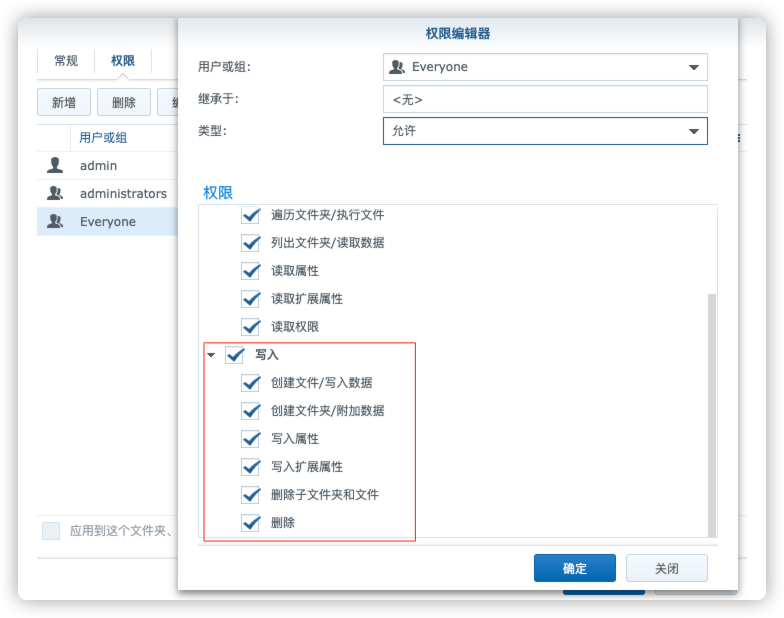
search:formats:- html- json
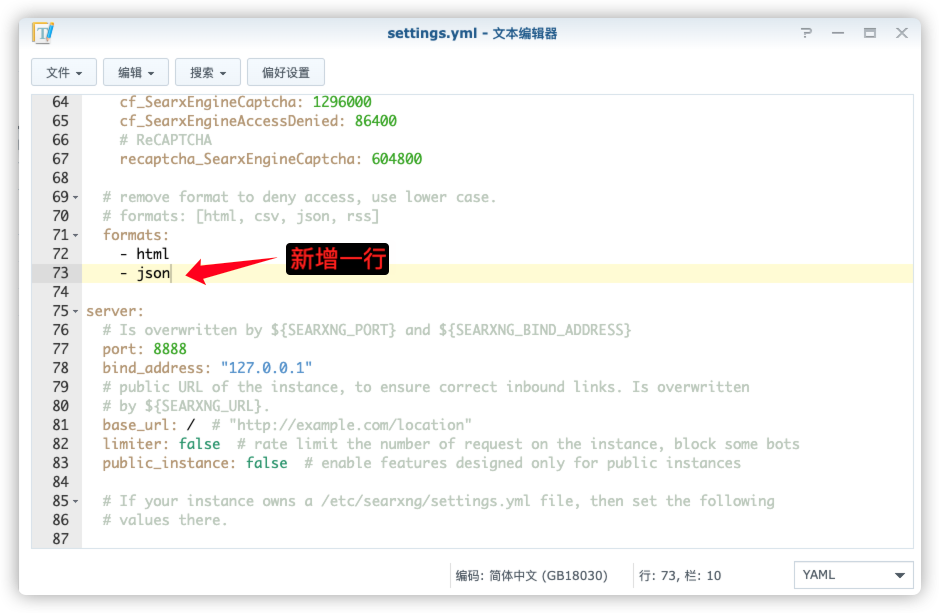
修改完成后,建议再打开看看,确认是否修改成功了,如果修改成了,可以单独重启一次容器 free_ask_internet_searxng

再次刷新页面,参考搜索结果有了,但是还是提示搜索失败

再看看日志,原来是超时了
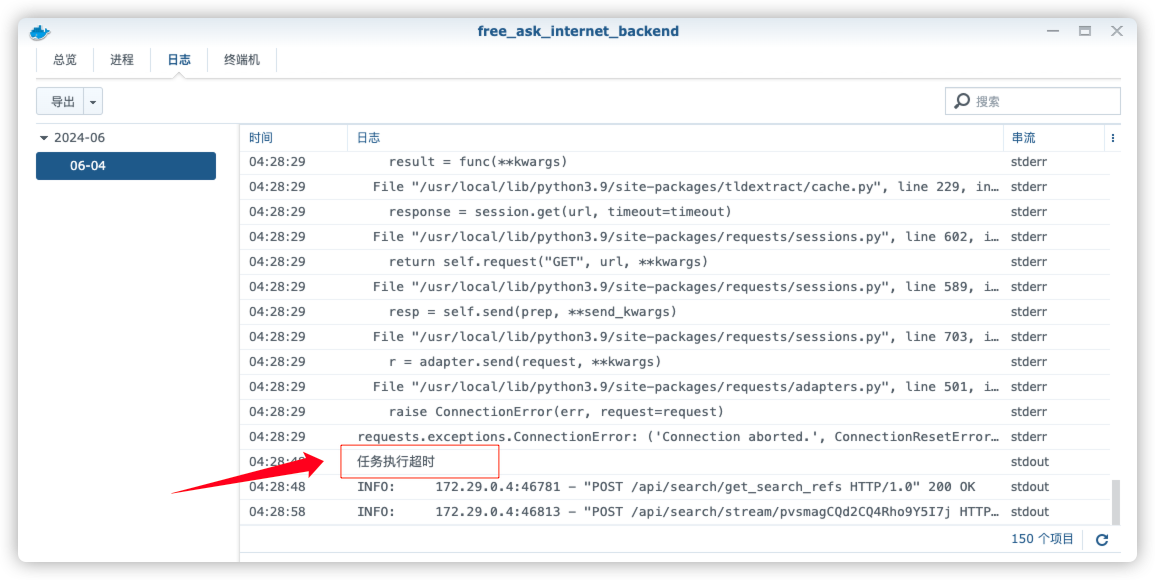
继续编辑 settings.yml 文件
outgoing:request_timeout: 5.0max_request_timeout: 10.0enable_http2: false
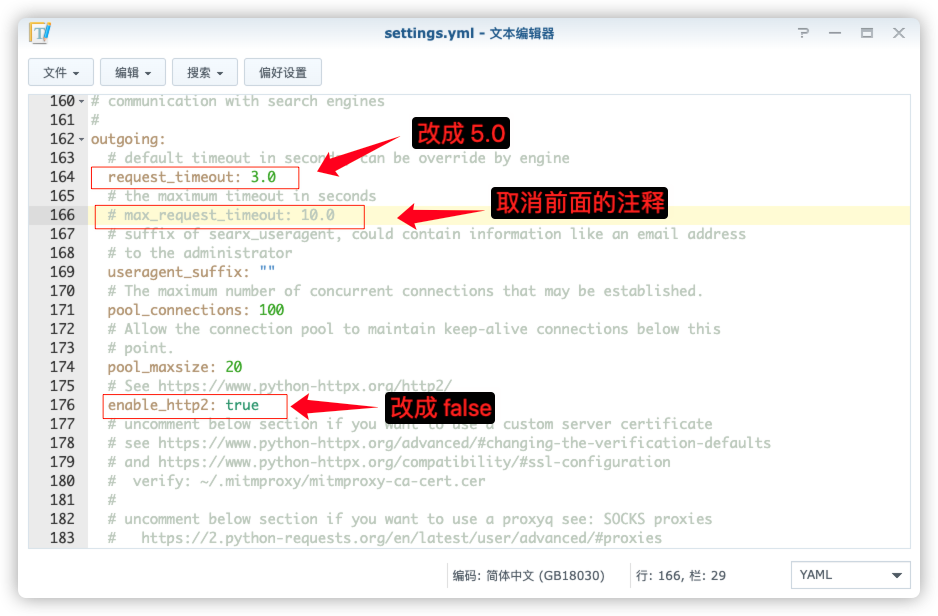
保存后

再次重启容器 free_ask_internet_searxng,搜索就没问题了

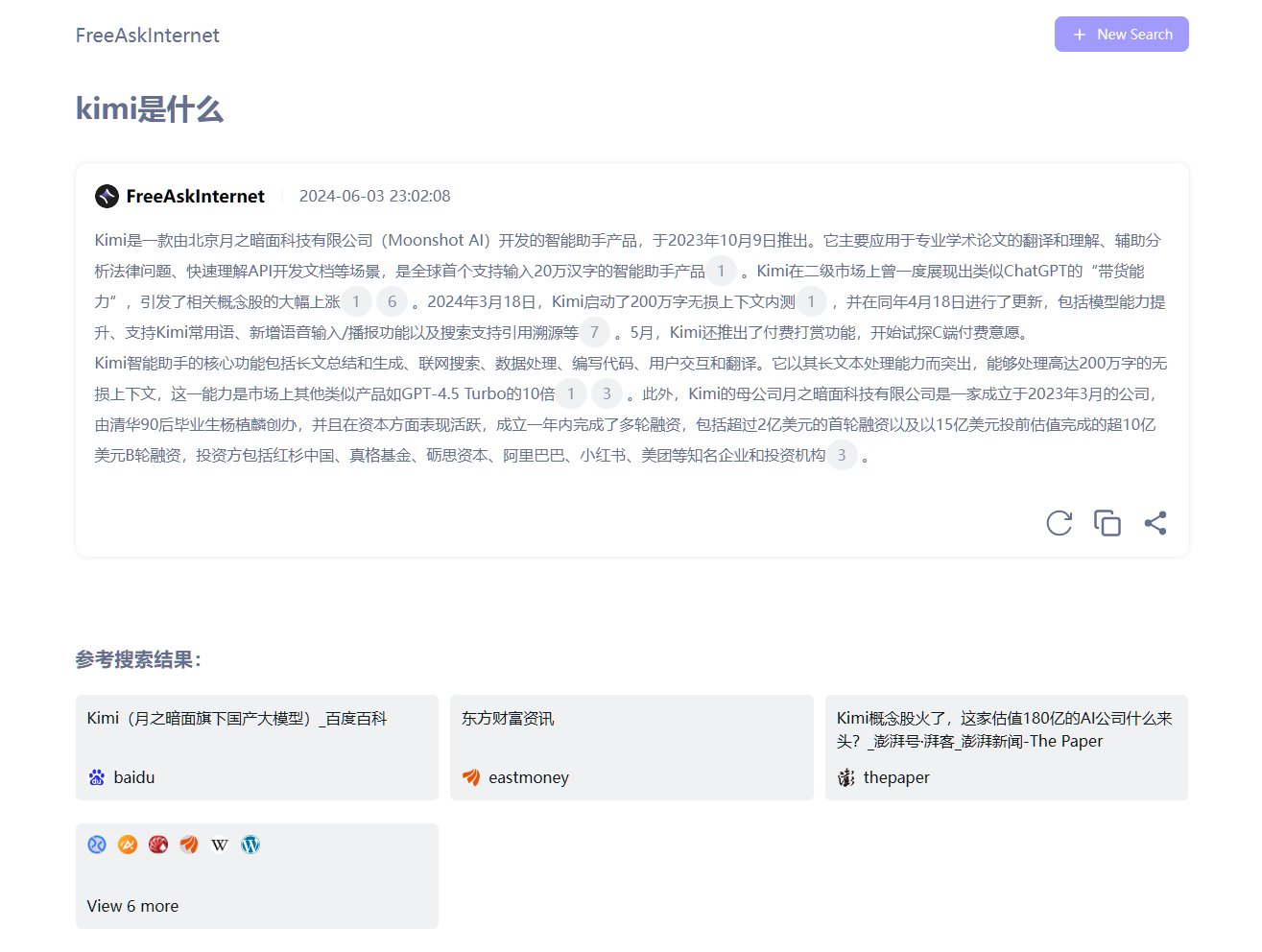
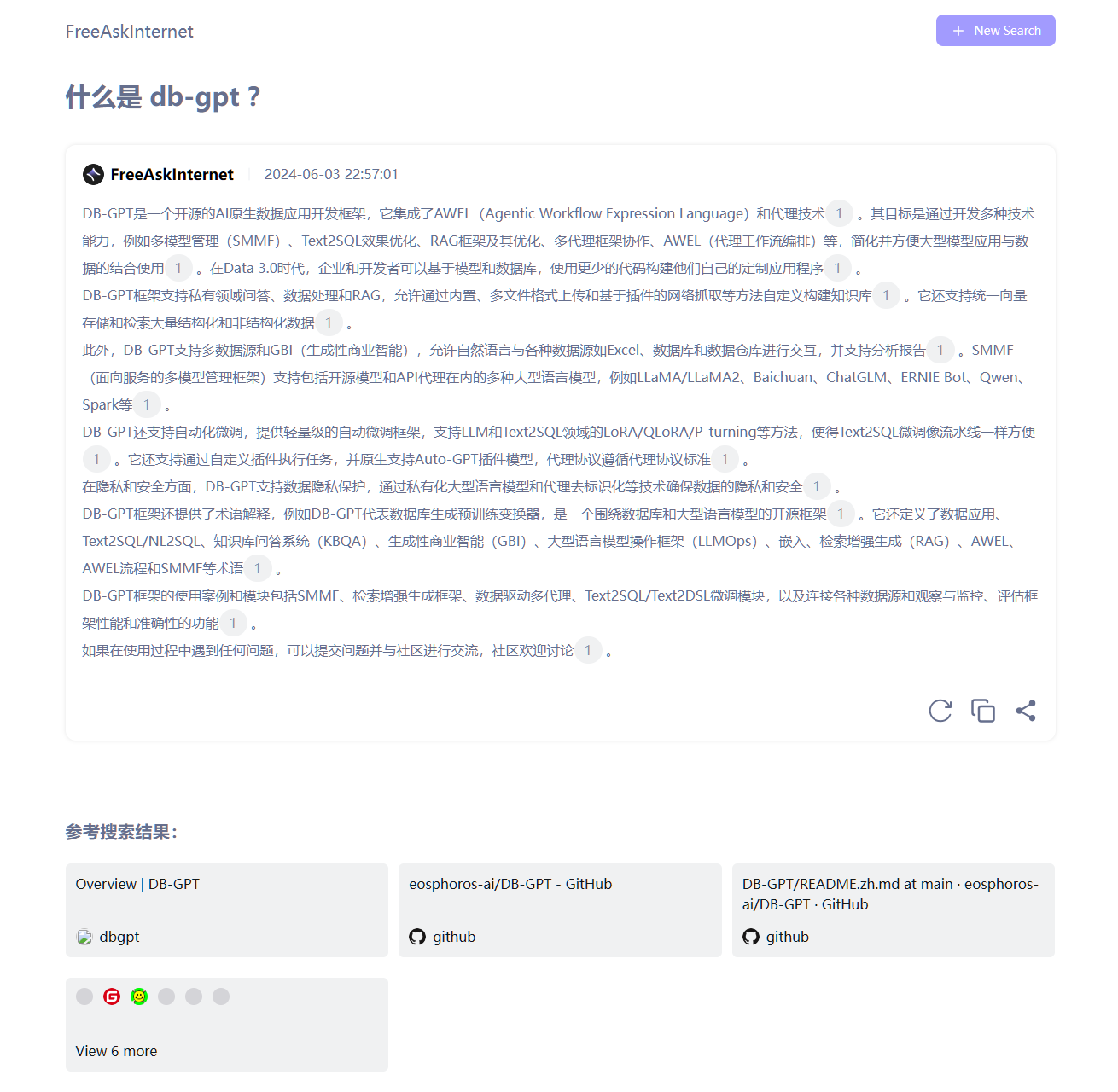

如果没有返回参考搜索结果的,但是告诉你搜索失败的,一般来说,应该是网络出问题了
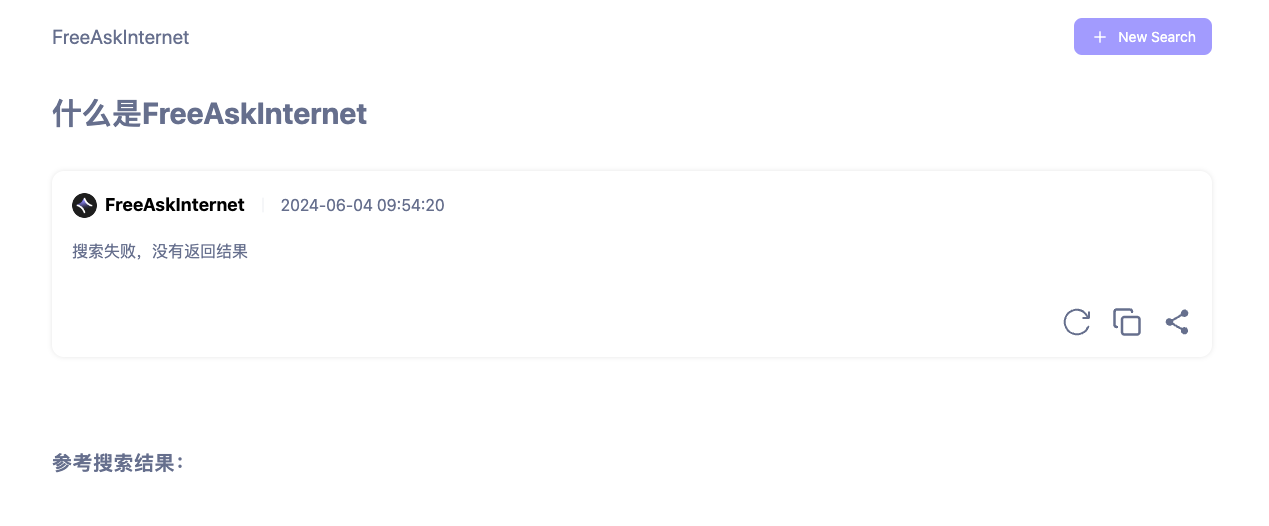
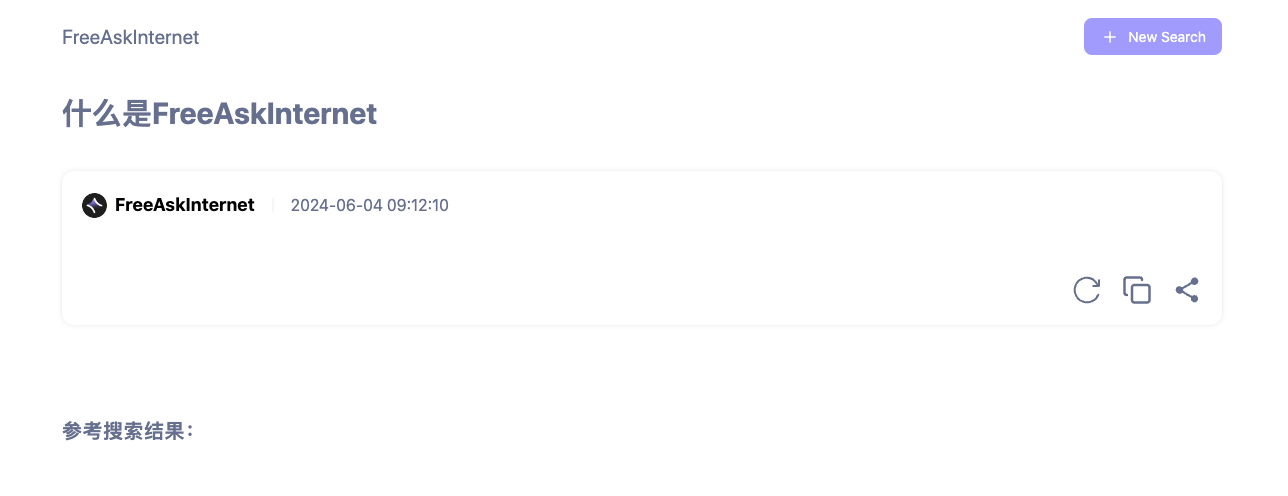
像下面这样一声不吭的,说明模型设置可能也是不正确的
参考文档
nashsu/FreeAskInternet: FreeAskInternet is a completely free, private and locally running search aggregator & answer generate using LLM, without GPU needed. The user can ask a question and the system will make a multi engine search and combine the search result to the ChatGPT3.5 LLM and generate the answer based on search results.
地址:https://github.com/nashsu/FreeAskInternet
python 3.x - LangChain search_tools ValueError: ('Searx API returned an error: ', ‘Too Many Requests’) - Stack Overflow
地址:https://stackoverflow.com/questions/77253870/langchain-search-tools-valueerror-searx-api-returned-an-error-too-many-r
SearXNG | 中文 | Dify
地址:https://docs.dify.ai/v/zh-hans/guides/gong-ju/tool-configuration/searxng
Bug: all engine · Issue #334 · searxng/searxng
地址:https://github.com/searxng/searxng/issues/334
这篇关于私有化AI搜索引擎FreeAskInternet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








