本文主要是介绍【Redis】什么是Redis缓存 雪崩、穿透、击穿?(一篇文章就够了),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
什么是Redis?
Redis的正常存储流程?
什么是Redis缓存雪崩?
缓存雪崩
缓存预热
缓存失效时间的随机性
什么是Redis缓存穿透?
缓存穿透
缓存空对象
BloomFilter(布隆过滤器)
什么是Redis缓存击穿?
缓存击穿
互斥锁
逻辑过期时间
什么是Redis?
Redis:是一种高性能开源的基于内存的,采用键值对存储的非关系型数据库,不保证数据的ACID特性【事务一旦提交,都不会进行回滚】
采用键值对存储数据在内存或磁盘中,可以对关系型数据库起到补充作用,同时支持持久化[可以将数据保存在可掉电设备中],可以将数据同步保存到磁盘。
说Redis很快是相对于关系型数据库如mysql来说的,主要有以下因素
第一,数据结构简单,所以速度快【采用键值对的方式】;
第二,基于内存进行存储,不需要存储数据库,所以速度快;
第三,采用多路IO复用模型,减少网络IO的时间消耗,避免大量的无用操作,所以速度快;
第四,单线程避免了线程切换和上下文切换产生的消耗,所以速度快;
Redis的正常存储流程?
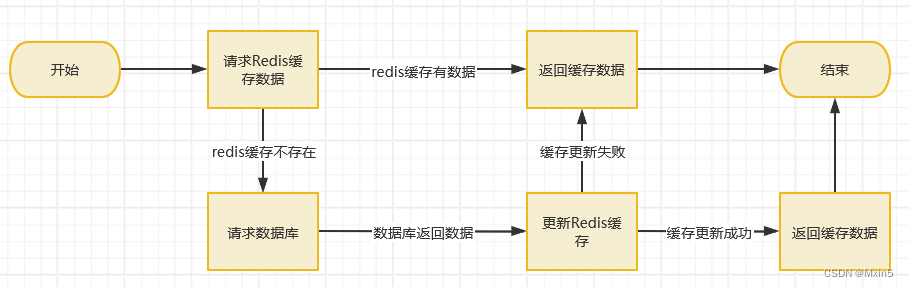
正常流程:当用户访问服务端时,服务端会去访问Redis缓存中是否有该数据的缓存,如果有,就直接返回;如果没有,就去数据库进行查询;查询到结果过后直接返回给客户端,并且将查询的结果数据同步到redis缓存当中。
什么是Redis缓存雪崩?
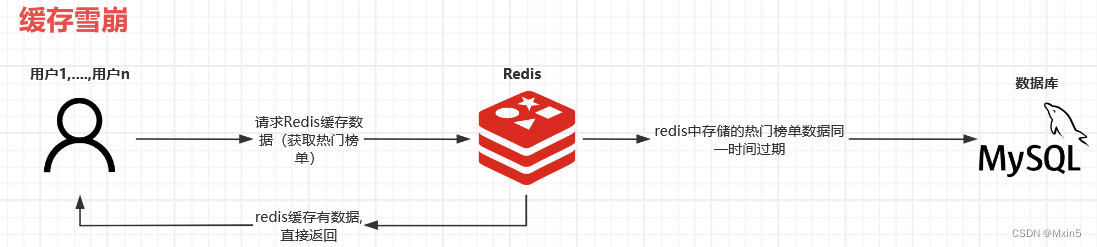
缓存雪崩
是指在某一时刻,缓存中的存储的数据同时大量地失效,而且这些数据都是经常被访问的数据(比如热点文章,热门商品等),这样就会导致大量的请求都会落到数据库上,造成数据库的压力瞬间增大,从而导致服务器宕机,形成一种“雪崩”效应。
简单来说,就是大量的redis同一时间大面积的失效,大量的请求直接打到数据库上(导致数据库压力飙升),这种现象就是缓存雪崩。
解决缓存雪崩的方法有很多,其中一种比较常见的方法是采用“缓存预热”和“缓存失效时间的随机性”两种手段来解决。
缓存预热
是指系统上线后,将相关的缓存数据直接加载到缓存中,这样一来,第一个请求过来的时候,就可以直接在缓存中获取到数据,而不需要去数据库中查询。
缓存失效时间的随机性
是指在设置缓存的失效时间时,不能够将所有缓存的失效时间都设置为相同的值,而是要在一个合理的时间范围内进行随机,这样可以避免缓存在某一时刻大量失效的情况。
下面是一个采用了缓存预热和缓存失效时间的随机性的Java代码:
public class UserService {private static final Random RANDOM = new Random();private RedisTemplate<String, User> redisTemplate;//可以将所有的初始化需要执行的代码放在一个单独的类中,使用@Scheduled或quartz或xxl-job定时控制执行public UserService(RedisTemplate<String, User> redisTemplate) {this.redisTemplate = redisTemplate;// 缓存预热,将所有用户数据加载到缓存中List<User> users = getUsersFromDB();for (User user : users) {redisTemplate.opsForValue().set(user.getId(), user, getExpireTime());}}public User getUser(String userId) {// 先从缓存中获取数据User user = redisTemplate.opsForValue().get(userId);if (user != null) {return user;}// 缓存中没有数据,则从数据库中查询user = getUserFromDB(userId);if (user != null) {// 将数据放入缓存,并且设置一个随机的失效时间redisTemplate.opsForValue().set(userId, user, getExpireTime());}return user;}private List<User> getUsersFromDB() {// 从数据库中查询所有用户数据// ...}private User getUserFromDB(String userId) {// 从数据库中查询用户数据// ...}private long getExpireTime() {// 在30分钟到1小时之间随机一个时间作为缓存的失效时间return 1800 + RANDOM.nextInt(1800);}}
什么是Redis缓存穿透?
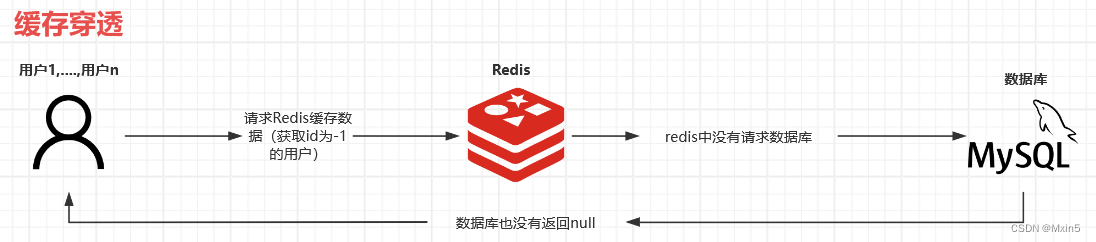
缓存穿透
是指恶意的请求,会故意查询数据库不存在的数据,而这些数据在Redis缓存中也不存在,这样就会导致大量的请求都会落到数据库上,造成数据库的压力瞬间增大,从而导致服务器宕机。
解决缓存穿透的方法有很多,其中一种比较常见的方法是采用“缓存空对象”和“BloomFilter(布隆过滤器)”两种手段来解决。
缓存空对象
是指在查询数据库时,如果发现查询的数据不存在,那么就将这个空对象也缓存起来,这样一来,下次再查询这个不存在的数据时,就可以直接在缓存中获取到空对象,而不需要去数据库中查询。
BloomFilter(布隆过滤器)
【Redis】布隆过滤器_布隆过滤器需要保存-CSDN博客
是一种概率性数据结构,可以用于判断一个元素是否存在于一个集合中,它的优势在于空间复杂度低、查询速度快。
下面是一个采用了缓存空对象和BloomFilter的Java代码:
public class UserService {private RedisTemplate<String, User> redisTemplate;private BloomFilter<String> bloomFilter;public UserService(RedisTemplate<String, User> redisTemplate, BloomFilter<String> bloomFilter) {this.redisTemplate = redisTemplate;this.bloomFilter = bloomFilter;// 将所有用户的ID都放入BloomFilter中List<User> users = getUsersFromDB();for (User user : users) {bloomFilter.add(user.getId());}}public User getUser(String userId) {// 先判断BloomFilter中是否存在该IDif (!bloomFilter.mightContain(userId)) {return null;}// 再从缓存中获取数据User user = redisTemplate.opsForValue().get(userId);if (user != null) {return user;}// 缓存中没有数据,则从数据库中查询user = getUserFromDB(userId);if (user != null) {// 将数据放入缓存redisTemplate.opsForValue().set(userId, user, 3600);} else {// 将空对象放入缓存redisTemplate.opsForValue().set(userId, null, 300);}return user;}private List<User> getUsersFromDB() {// 从数据库中查询所有用户数据// ...}private User getUserFromDB(String userId) {// 从数据库中查询用户数据// ...}}
``
什么是Redis缓存击穿?
缓存击穿
是指某个热点数据在缓存中失效了,而且这个数据也是经常被访问的数据,这样就会导致大量的请求都会落到数据库上,造成数据库的压力瞬间增大,从而导致服务器宕机。
解决缓存击穿的方法有很多,其中一种比较常见的方法是采用“互斥锁”和“逻辑过期时间”两种手段来解决。
互斥锁
是指在查询数据库时,如果发现缓存中的数据已经失效,那么就先获取一个互斥锁,然后再去查询数据库,这样一来,只有一个线程去访问数据库,将查询到的数据同步到缓存当中,其他线程就直接从缓存中获取了,就可以避免大量的请求都会落到数据库上。
逻辑过期时间
是指在查询数据库时,如果发现缓存中的数据已经失效,那么就先将数据库中的数据缓存起来,但是不将这个数据的过期时间设置为实际的过期时间,而是将过期时间设置为一个较短的时间,这样一来,就可以避免缓存中的数据一直都是“冷”数据。
下面是一个采用了互斥锁和逻辑过期时间的Java代码:
public class UserService {private RedisTemplate<String, User> redisTemplate;private RedissonClient redissonClient;public UserService(RedisTemplate<String, User> redisTemplate, RedissonClient redissonClient) {this.redisTemplate = redisTemplate;this.redissonClient = redissonClient;}public User getUser(String userId) {// 先从缓存中获取数据User user = redisTemplate.opsForValue().get(userId);if (user != null && !user.isExpired()) {return user;}// 获取互斥锁RLock lock = redissonClient.getLock("user:" + userId);try {if (lock.tryLock(10, 5, TimeUnit.SECONDS)) {// 再次从缓存中获取数据user = redisTemplate.opsForValue().get(userId);if (user != null && !user.isExpired()) {return user;}// 从数据库中查询数据user = getUserFromDB(userId);if (user != null) {// 将数据放入缓存,并且设置一个逻辑过期时间redisTemplate.opsForValue().set(userId, user, 3600);user.setExpireTime(System.currentTimeMillis() + 300000);}}} finally {// 释放互斥锁if (lock != null && lock.isHeldByCurrentThread()) {lock.unlock();}}return user;}private User getUserFromDB(String userId) {// 从数据库中查询用户数据// ...}}public class User {private String id;private String name;private long expireTime;public User(String id, String name) {this.id = id;this.name = name;this.expireTime = System.currentTimeMillis() + 300000;}public String getId() {return id;}public String getName() {return name;}public boolean isExpired() {return System.currentTimeMillis() > expireTime;}}
这篇关于【Redis】什么是Redis缓存 雪崩、穿透、击穿?(一篇文章就够了)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





