本文主要是介绍MapReducer Reducer Class,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Reducer可以用作Combiner的情况:
满足 a.b=b.a或者a.(b.c)=(a.b).c
Combiner能用就用,不一定是用Reducer来替代。
设置Reducer为Combiner类的方法:
job.setCombinerClass(WCReducer.class);
Partitioner Class:决定把k-v数据块发给哪个Reducer
Reducer Class:和mapper里面的方法几乎一模一样,工作流程不再赘述。
1. setup方法 框架只调用一次
2、reduce方法
reduce(KEY key, Iterable<VALUE> values,Context context)
这个key呢,他可能来自不同的Mapper,他是一个集合。

就是简单一个对value求和
3.cleanup方法
4.run方法
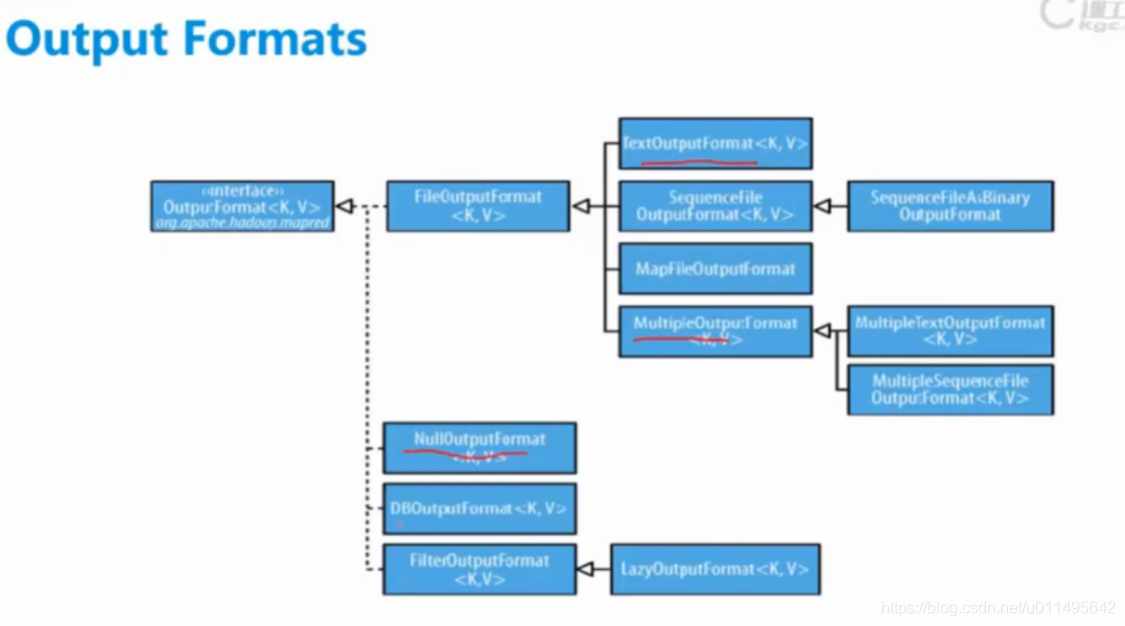
Reducer处理完之后key-value发给 output format,
它也有2个方法
第一个是写记录,把Reducer拿过来的Key-Value 记录按自己的读取方式写到目标文件上。
第二个方法是我check一下,目标目录如果存在了,我不会覆盖原来的文件。(具体的还不是很清楚)

这篇关于MapReducer Reducer Class的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




