mapreducer专题

Hadoop运行中NameNode闪退和运行mapreducer时卡在Running job.....
开始安装Hadoop时 第一次成功启动 包括MapReducer程序也能成功运行。后来不知道什么原因 进入了Safe mode 即使退出了安全模式照样不能对HDFS进行任何修改操作,索性hdfs namenode -format格式化一下,连启动都无法启动了,修改NameNode和DataNode的clusterID一致后 虽然修改HDFS问题解决了,但是运行任务时总是卡在了Running jo

MapReducer程序调试技巧(搭建伪分布式集群)
写过程序分布式代码的人都知道,分布式的程序是比较难以调试的,但是也不是不可以调试,对于Hadoop分布式集群来说,在其上面运行的是mapreduce程序,因此,有时候写好了mapreduce程序之后,执行结果发现跟自己想要的结果不一样,但是有没有报错,此时就很难发现问题,查找问题的方法之一就是对程序进行调试,跟踪代码的执行,找出问题的所在。那么对于Hadoop的Mapreduce是如何进行调试的
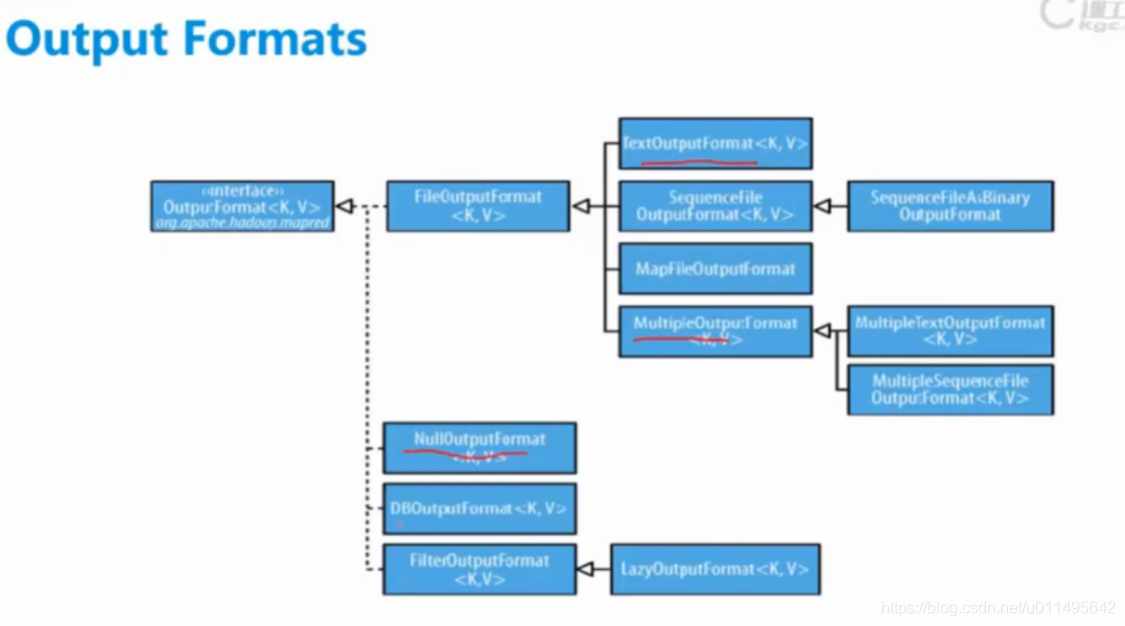
MapReducer Reducer Class
Reducer可以用作Combiner的情况: 满足 a.b=b.a或者a.(b.c)=(a.b).c Combiner能用就用,不一定是用Reducer来替代。 设置Reducer为Combiner类的方法: job.setCombinerClass(WCReducer.class); Partitioner Class:决定把k-v数据块发给哪个Reducer R
MapReducer 取前五的案列Top n
1.业务需求,统计单词个数取前五Top 5 2.数据 Chief Justice Roberts, Vice President Harris, Speaker Pelosi, Leader Schumer, Leader McConnell, Vice President Pence, my distinguished guests, [and] my fellow Americans.T
![[Hadoop]MapReducer工作过程](https://img-blog.csdn.net/20161230102726615?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvU3VubnlZb29uYQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[Hadoop]MapReducer工作过程
1. 从输入到输出 一个MapReducer作业经过了input,map,combine,reduce,output五个阶段,其中combine阶段并不一定发生,map输出的中间结果被分到reduce的过程成为shuffle(数据清洗)。 在shuffle阶段还会发生copy(复制)和sort(排序)。 在MapReduce的过程中,一个作业被分成Map和Reducer两个计算阶段,它们