本文主要是介绍【RAG入门教程01】Langchian框架 v0.2介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LangChain 是一个开源框架,旨在简化使用大型语言模型 (LLM) 创建应用程序的过程。可以将其想象成一套使用高级语言工具进行搭建的乐高积木。
它对于想要构建复杂的基于语言的应用程序而又不必管理直接与语言模型交互的复杂性的开发人员特别有用。它简化了将这些模型集成到应用程序中的过程,使开发人员能够更加专注于应用程序逻辑和用户体验。
LLMs
“LLM” 代表“大型语言模型”,这是一种旨在大规模理解、生成和与人类语言交互的人工智能模型。这些模型在大量文本数据上进行训练,可以执行各种与语言相关的任务。
这些模型最初通过识别和解释单词与更广泛概念之间的关系来建立基础理解。这一初始阶段为进一步的微调奠定了基础。微调过程涉及监督学习,其中使用有针对性的数据和特定反馈对模型进行微调。此步骤可提高模型在各种情况下的准确性和相关性。
Transformer
训练数据通过一种称为 Transformer 的专门神经网络架构进行处理。这是大型语言模型 (LLM) 开发的关键阶段。
从非常高层次的概述来看,编码器处理输入数据(例如一种语言的句子)并将信息压缩为上下文向量。然后解码器获取此上下文向量并生成输出(例如将句子翻译成另一种语言)。
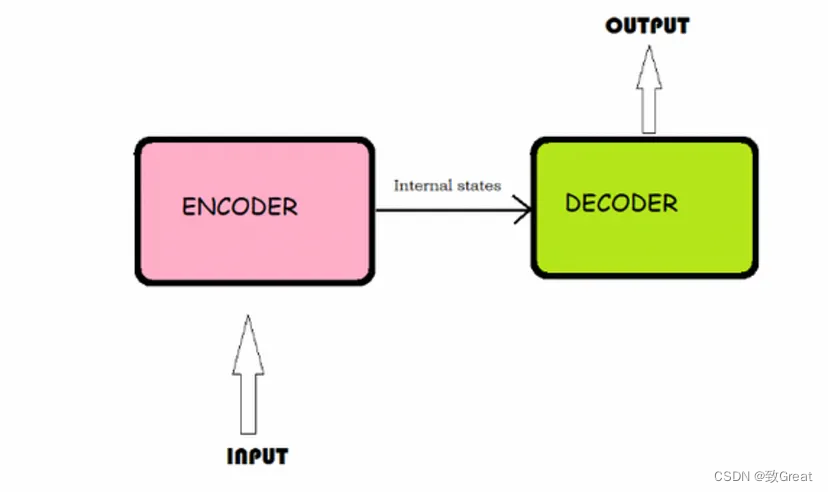
编码器和解码器具有“自注意力”机制,这使得模型可以对输入数据的不同部分的重要性赋予不同的权重。
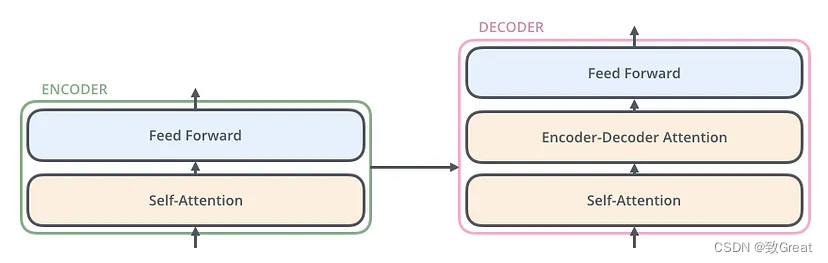
自注意力机制让模型在处理特定单词或短语时能够关注输入文本的不同部分。对于每个单词,模型会评估句子中所有其他单词与其的相关性,并为这些关系分配权重。这些权重有助于模型更全面地理解句子结构和含义,从而生成更准确、更符合语境的回复或翻译。
大模型(LLM)
- 专有模型:这些是由公司开发和控制的 AI 模型。它们通常提供高性能,并得到大量资源和研究的支持。然而,它们的使用成本可能很高,可能具有限制性许可证,并且其内部工作原理通常不透明(闭源)。
- 开源模型:相比之下,开源 AI 模型可供任何人免费使用、修改和分发。它们促进社区内的协作和创新,并提供更大的灵活性。然而,它们的性能可能并不总是与专有模型相匹配,而且它们可能缺乏大公司提供的广泛支持和资源。
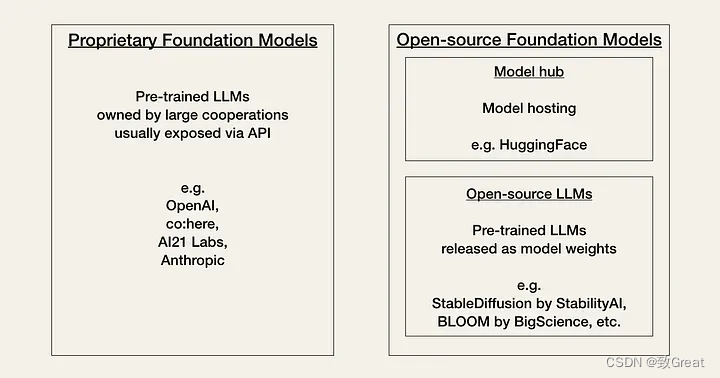
这些模型之间的选择涉及性能、成本、易用性和灵活性方面的权衡。开发人员必须决定是选择可能更强大但限制更多的专有模型,还是更灵活但可能不够完善的开源替代方案。这一选择反映了软件开发中早期的决策点,例如 Linux 所呈现的决策点,标志着 AI 技术及其可访问性发展的重要阶段。
Langchain
Langchain 有助于访问和合并来自各种来源(例如数据库、网站或其他外部存储库)的数据到使用 LLM 的应用程序中。
VectorStore向量存储
它将文档转换为向量存储。文档中的文本被转换为称为向量的数学表示,向量的表示称为嵌入。
当 Langchain 处理文档时,它会为文本内容生成嵌入。
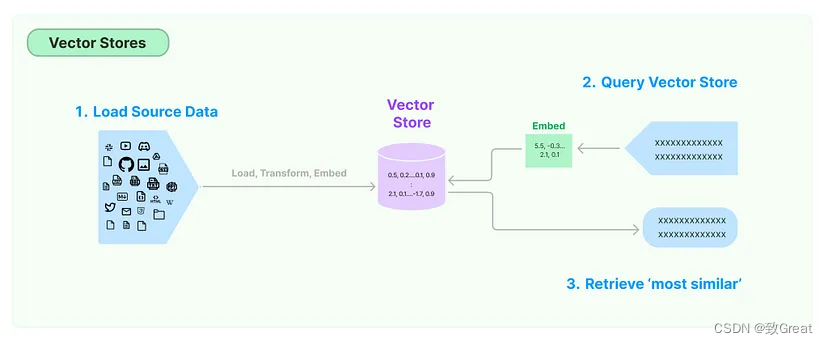
从文档创建的嵌入填充了 Vector Store。文档中的每段文本都表示为该存储中的一个向量(嵌入)。因此,Vector Store 成为这些嵌入的存储库,以数学和语义丰富的格式表示原始文档的内容。
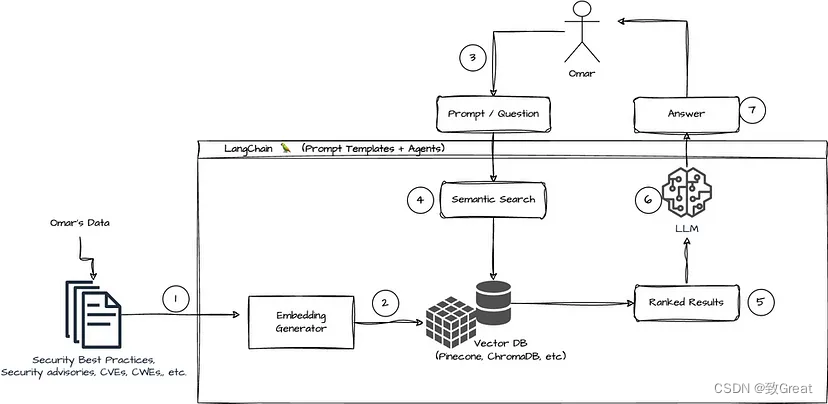
当您有“Transformer 是什么?”这样的问题时,大型语言模型 (LLM) 首先会将此问题转换为嵌入。这意味着 LLM 将问题转换为与存储在向量存储中的数据相同的向量格式。此转换可确保问题和存储的信息具有可比的格式。
现在问题已变成向量格式,LLM 可以有效地搜索向量存储。此查询过程的核心是相似性搜索。LLM 评估问题的向量与向量存储中的每个向量的相似程度。
进行相似性搜索后,LLM 会识别向量库中与问题向量最相似的向量。然后,这些向量会被重新翻译成文本形式,从而检索出与问题最相关、最相似的信息。
组件
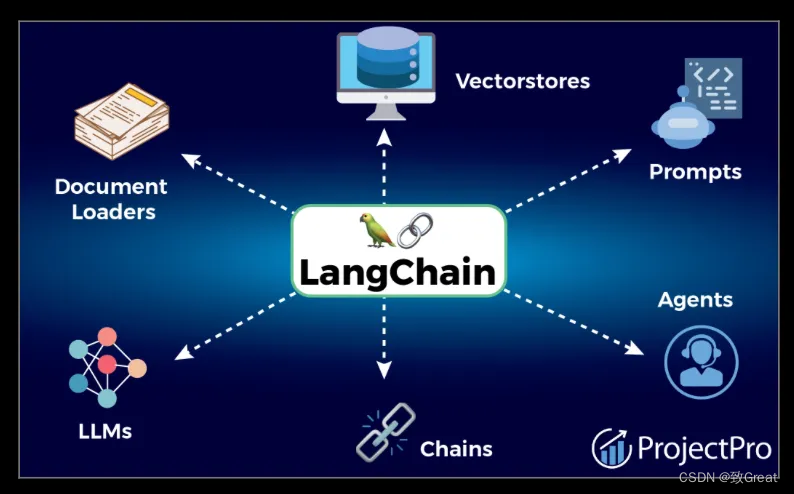
Langchain 提供各种组件,使得在不同应用环境中集成和管理模型变得更加容易。
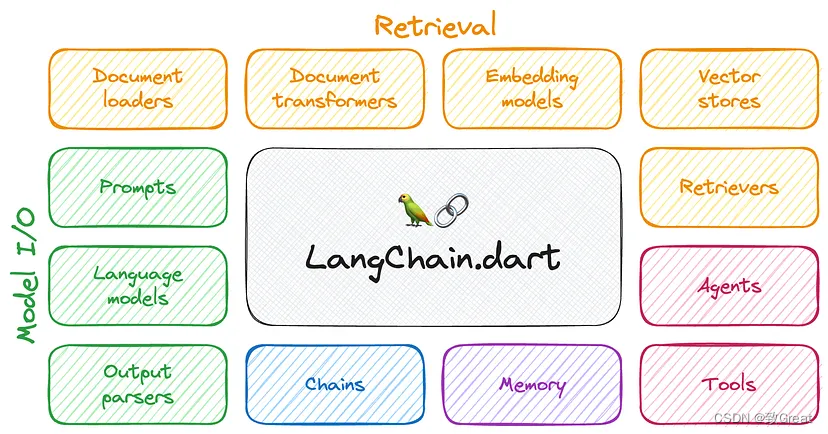
- 文档加载器是旨在简化从各种来源导入和处理文本数据的实用程序。
- 文档转换器对文本数据进行各种转换,使其格式更有利于大型语言模型 (LLM) 进行分析和处理。
- 文本嵌入模型专注于将文本数据转换为嵌入。
- 向量存储作为用于存储和管理嵌入的专用数据库。
- 检索器旨在根据给定的查询从向量存储中有效地检索相关信息。
- 工具执行特定任务和操作。例如,Bing 搜索工具是一个 API,用于将 Bing 搜索与 LLM 结合使用。
- 代理代表一种高级抽象,用于协调不同 Langchain 组件与最终用户之间的交互。它充当 LLM 和工具之间的中介,处理用户查询,使用 Langchain 中的适当模型和工具进行处理,然后将结果返回给用户。
- 记忆组件提供了一种记住和参考过去的交互或信息的机制。
- 链通过将 LLM 可以执行的各种任务链接在一起,有助于构建多步骤工作流或流程。此组件允许按顺序执行不同的语言任务,例如信息检索,然后是文本摘要或问答。通过创建这些任务链,Langchain 可以与 LLM 进行更复杂、更细致的交互和操作。
- Langchain 的LLM和聊天模型组件提供了一个框架,用于在应用程序内集成和管理各种大型语言模型(LLM),包括专门的聊天模型。
- 提示和解析器简化了模型的输入和输出。
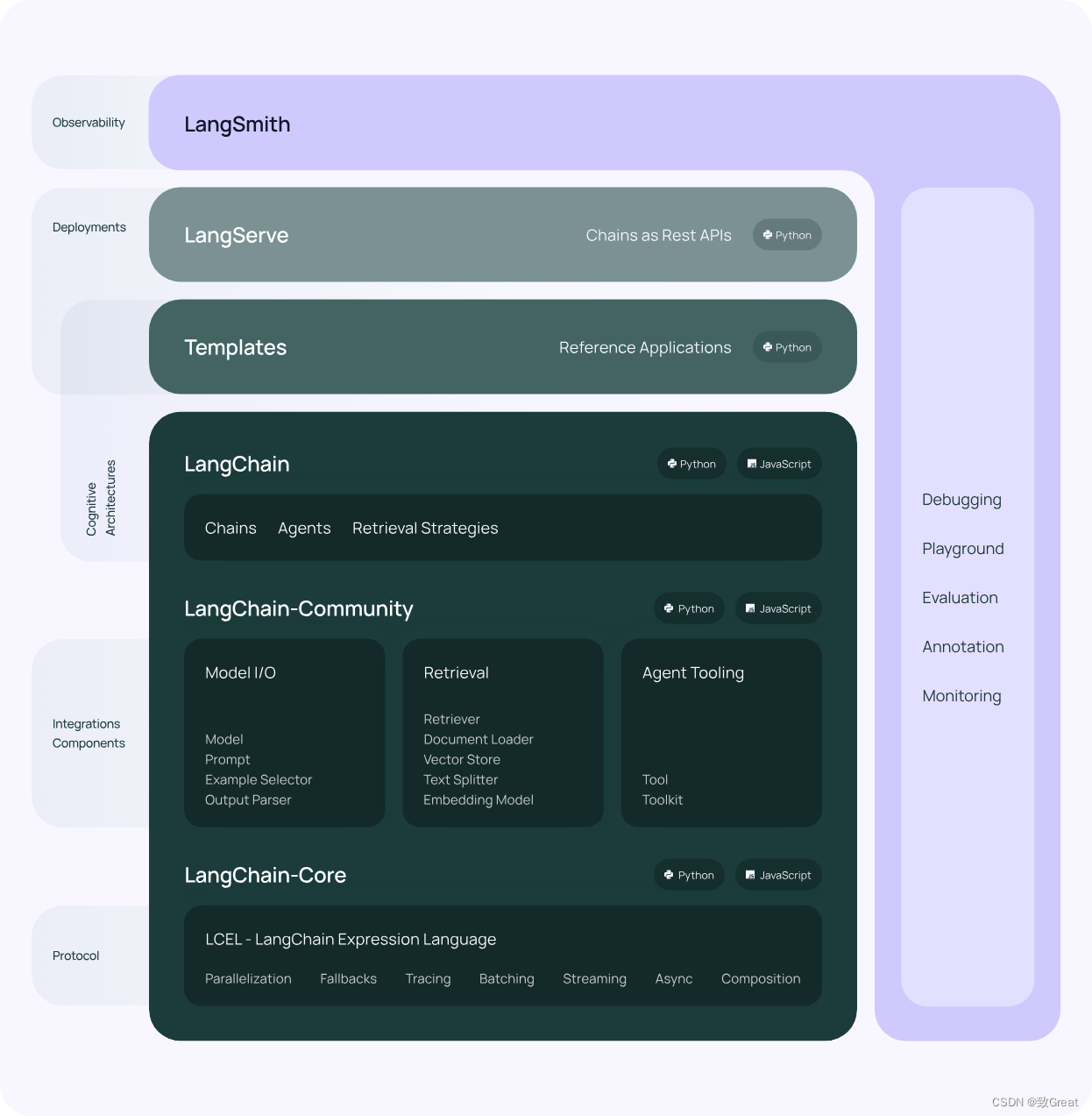
LangChain 的核心组件
- 模型 I/O 封装
- LLMs:大语言模型
- Chat Models:一般基于 LLMs,但按对话结构重新封装
- PromptTemple:提示词模板
- OutputParser:解析输出
- 数据连接封装
- Document Loaders:各种格式文件的加载器
- Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:文本向量化表示,用于检索等操作
- Verctorstores: (面向检索的)向量的存储,保存了向量索引以及文档信息
- Retrievers: 向量的检索
- 记忆封装
- Memory:这里不是物理内存,从文本的角度,可以理解为“上文”、“历史记录”或者说“记忆力”的管理
- 架构封装
- Chain:实现一个功能或者一系列顺序功能组合
- Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
- Callbacks
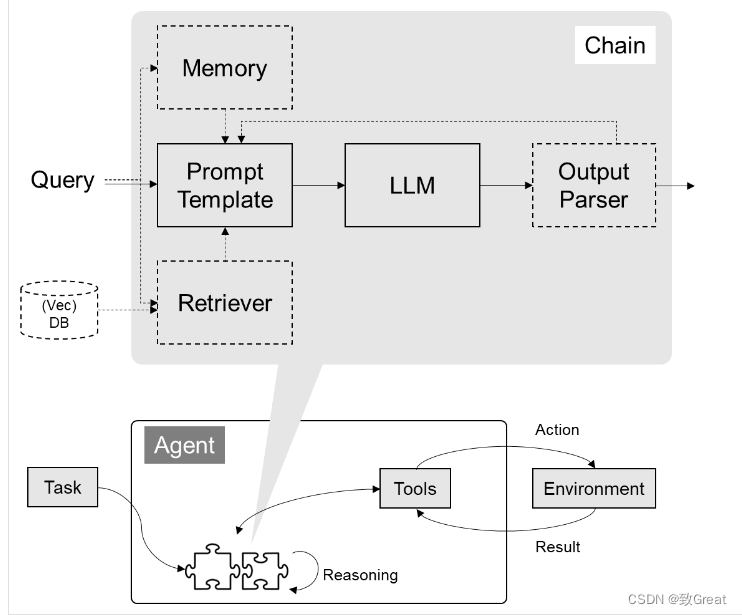
- 功能模块:https://python.langchain.com/docs/get_started/introduction
- API 文档:https://api.python.langchain.com/en/latest/langchain_api_reference.html
- 三方组件集成:https://python.langchain.com/docs/integrations/platforms/
- 官方应用案例:https://python.langchain.com/docs/use_cases
- 调试部署等指导:https://python.langchain.com/docs/guides/debuggin
langchain v0.2升级
langchain v0.2导入方式发生了变化,具体模块可以参考以下API文档
https://api.python.langchain.com/en/latest/langchain_api_reference.html
使用前用下面命令进行安装:
pip install langchain
pip install langchain-core
pip install langchain-text-splitters
pip install langchain-huggingface
pip install langchain_openai==0.1.8
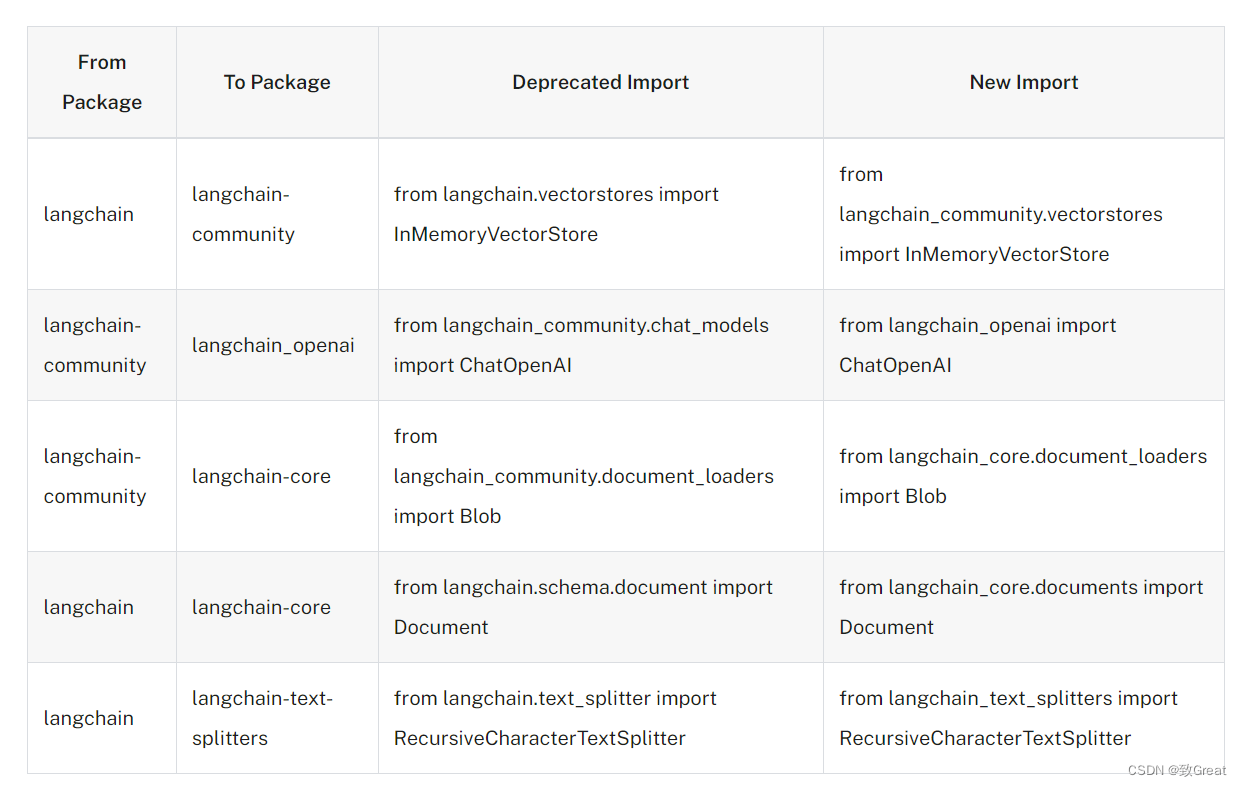
迁移文档:https://python.langchain.com/v0.2/docs/versions/v0_2/
参考资料
- LangChain框架介绍
- LangChain in Chains #1: A Closer Look
这篇关于【RAG入门教程01】Langchian框架 v0.2介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







