本文主要是介绍数据结构与算法系列之一:八大排序之希尔排序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 转载请注明作者和出处:http://blog.csdn.net/u011475210
- 个人博客:https://wordzzzz.github.io/ && https://wordzzzz.gitee.io/
- 代码地址:https://github.com/WordZzzz/Note/tree/master/DS-A
- 博客作者:WordZzzz,一只热爱技术的文艺青年
-
- 希尔排序
- 前言
- 简介
- 步骤
- 演示
- 代码
- 算法复杂度
- 分析
- 希尔排序
希尔排序
前言
建议先看排序综述,传送门:数据结构与算法系列之一:八大排序综述。
简介
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
步骤
原始的算法实现在最坏的情况下需要进行 O(n2) 的比较和交换。V. Pratt的书对算法进行了少量修改,可以使得性能提升至 O(nlog2n) 。这比最好的比较算法的 O(nlogn) 要差一些。
希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
假设有一个很小的数据在一个已按升序排好序的数组的末端。如果用复杂度为O(n2)的排序(冒泡排序或插入排序),可能会进行n次的比较和交换才能将该数据移至正确位置。而希尔排序会用较大的步长移动数据,所以小数据只需进行少数比较和交换即可到正确位置。
一个更好理解的希尔排序实现:将数组列在一个表中并对列排序(用插入排序)。重复这过程,不过每次用更长的列来进行。最后整个表就只有一列了。将数组转换至表是为了更好地理解这算法,算法本身仅仅对原数组进行排序(通过增加索引的步长,例如是用i += step_size而不是i++)。
例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45排序之后变为:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94最后以1步长进行排序(此时就是简单的插入排序了)。
演示
wikipedia的大数据规模演示:
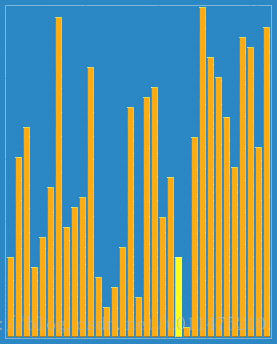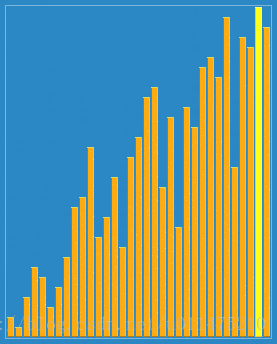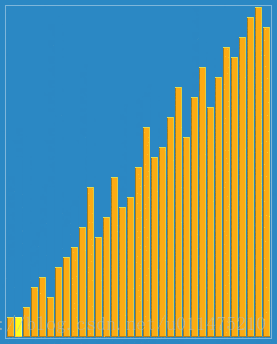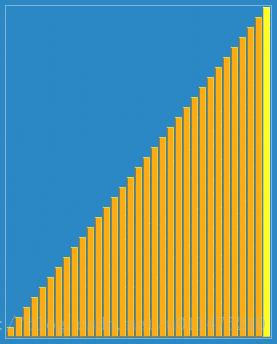
代码
/** 希尔排序*/template <typename T>
void ShellSort(T *array, const int length) {if (array == NULL)throw invalid_argument("Array must not be empty");if (length <= 0)return;for (int gap = length >> 1; gap > 0; gap >>= 1){ //gap是设置的步长T tmp;for (int i = gap; i < length; ++i){tmp = array[i];int j = i; //后面要用到j,所以在for循环的外面初始化while (j >= gap && tmp < array[j - gap]){array[j] = array[j - gap];j -= gap;}array[j] = tmp;}}
}算法复杂度
- 数据结构 数组
- 最坏时间复杂度 根据步长序列的不同而不同。已知最好的: O(nlog2n)
- 最优时间复杂度 O(n)
- 平均时间复杂度 根据步长序列的不同而不同。
- 空间复杂度 O(n)
分析
步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell最初建议步长选择为 n2 并且对步长取半直到步长达到1。虽然这样取可以比 O(n2) 类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。
| 步长序列 | 最坏情况下复杂度 |
|---|---|
| n/2i | O(n2) |
| 2k−1 | O(n3/2) |
| 2i3j | O(nlog2n) |
已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,…),该序列的项来自 9×4i−9×2i+1 和 2i+2×(2i+2−3)+1 这两个算式。这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序要快,甚至在小数组中比快速排序和堆排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
另一个在大数组中表现优异的步长序列是(斐波那契数列除去0和1将剩余的数以黄金分区比的两倍的幂进行运算得到的数列):(1, 9, 34, 182, 836, 4025, 19001, 90358, 428481, 2034035, 9651787, 45806244, 217378076, 1031612713,…)
系列教程持续发布中,欢迎订阅、关注、收藏、评论、点赞哦~~( ̄▽ ̄~)~
完的汪(∪。∪)。。。zzz
这篇关于数据结构与算法系列之一:八大排序之希尔排序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








