本文主要是介绍数学模型:操作系统中FCFS、SJF、HRRN算法的平均周转时间比较 c语言,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘 要
研究目的:比较操作系统中进程调度FCFS、SJF、HRRN算法的平均周转时间和带权周转时间的大小关系。
研究方法:在建模分析时,分别举4个进程的例子,1个进程用两个字母分别表示到达时间和执行时间。分两种极端情况,一种是每个进程到达时cpu还在执行之前的进程,这种结果为T(FCFS)>T(HRRN)>T(SJF),W(FCFS)>W(HRRN)>W(SJF)。另一种是每个进程到达时cpu已经处理完之前的进程,这种结果为3种算法的执行都是相同的且T=W=1。而随机数据在两种极端之间。
在进行算法检验时,用c语言随机生成5000个进程,三个函数代表3中不同算法的求解结果。
研究结果与结论:T(FCFS)>=T(HRRN)>=T(SJF),W(FCFS)>=W(HRRN)>=W(SJF)
关键词:初等模型;操作系统进程调度;FCFS;SJF;HRRN
1. 问题重述
在多道批处理系统中,作业是用户提交给系统的一项相对独立的工作。作业调度的主要任务是根据jcb中的信息,检查系统中的资源能否满足作业对资源的需求,以及按照一定的调度算法,从外存的后备队列中选取某些作业调入内存,并为他们创建进程、分配必要的资源。
先来先服务调度算法(FCFS),系统按照作业到达后的先后次序来进行调度,后者说它是优先考虑在系统中等待时间最长的作业,而不管该作业所执行的时间长短。在进程调度中,每次调度是从就绪的进程队列中选择一个最先进入该队列的进程,为之分配处理机,使之投入运行,该进程一直运行到完成或发生某事件而阻塞后,进程调度程序才将处理机分配给其他进程。
短作业优先算法(SJF),以作业的长短来计算优先级,作业越短,其优先级越高。作业的长短是以作业所要求的运行时间来衡量的。所以需要预知作业的运行时间,但却很难准确估计作业的运行时间,如果估计过低,系统可能按估计的时间终止作业的运行,但此时作业并未完成,故一般估计时间都会偏长。
高相应比优先调度算法(HRRN),该算法即考虑了作业的等待时间,又考虑了作业运行时间的调度算法,因此既照顾了短作业,又不致使长作业的等待时间过长。每个作业都有一个动态优先级,优先级是可以改变的,令它随等待时间延长而而增加,这将使长作业在等待期间不断地增加,等到足够的时间后,必然会有机会获得处理机,该优先级的变化规律是
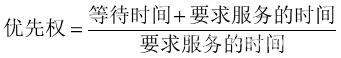 (1-1)
(1-1)
批处理系统的目标,平均周转时间短,它包括4部分时间:作业从外存后备队列上等待调度的时间,进程在就绪队列上等待进程调度的时间,进程在CPU上执行的时间,以及进程等待I/O操作完成的时间。平均周转时间短,不仅会有效的提高系统资源的利用率,而且还可以使大多数用户感到满意。平均周转时间
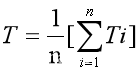 (1-2)
(1-2)
为了进一步反应调度的性能,更清晰的描述各进程在其周转时间中,等待和执行的具体分配情况,往往使用带权周转时间,即作业的周转时间T与系统的为它提供服务的时间Ts
之比,即W=T/Ts,平均带权周转时间可表示为:
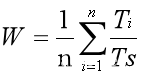 (1-3)
(1-3)
问题1:3种算法的平均周转时间有什么大小关系
问题2:3种算法的带权周转时间有什么大小关系
2. 问题分析
本题为3种算法的平均周转时间和带权周转时间的比较,可以列出几个进程进行具体的计算,然后再进行比较,在利用程序进行检验。在平均周转时间中分为4种:作业从外存后备队列上等待调度的时间,进程在就绪队列上等待进程调度的时间,进程在CPU上执行的时间,以及进程等待I/O操作完成的时间。在进行计算时只考虑进程在就绪队列上等待进程调度的时间和进程在CPU上执行的时间。在进行分析时,分两种极端情况,一种是每个进程到达时cpu还在执行之前的进程,一种是每个进程到达时cpu已经处理完之前的进程。
3. 模型假设
3.1忽略cpu执行进程时的切换时间。
3.2在计算平均周转时间和带权周转时间时只考虑进程在就绪队列上等待进程调度的时间和进程在CPU上执行的时间。
3.3每个进程的执行时间已经预知且精准。
3.4在分析每个进程到达时cpu还在执行之前的进程这种情况时,认为T1>T2>T3>T4,A<B<C<D。
4.符号说明
A:进程1的到达时间。T1:进程1的执行时间
B:进程2的到达时间。T2:进程2的执行时间
C:进程3的到达时间。T3:进程3的执行时间
D:进程4的到达时间。T4:进程4的执行时间
5.模型建立
模型一
先来先服务调度算法-每个进程到达时cpu还在执行之前的进程
| 进程 | 到达时间 | 执行时间 | 开始时间 | 结束时间 | 等待时间 |
| 1 | A | T1 | A | A+T1 | 0 |
| 2 | B | T2 | A+T1 | A+T1+T2 | T1-B |
| 3 | C | T3 | A+T1+T2 | A+T1+T2+T3 | T1+T2-C |
| 4 | D | T4 | A+T1+T2+T3 | A+T1+T2+T3+T4 | T1+T2+T3-D |
表1-1
短作业优先算法-每个进程到达时cpu还在执行之前的进程
| 进程 | 到达时间 | 执行时间 | 开始时间 | 结束时间 | 等待时间 |
| 1 | A | T1 | A | A+T1 | 0 |
| 4 | D | T4 | A+T1 | A+T1+T4 | T1-D |
| 3 | C | T3 | A+T1+T4 | A+T1+T4+T3 | T1+T4-B |
| 2 | B | T2 | A+T1+T4+T3 | A+T1+T2+T3+T4 | T1+T4+T3-C |
表1-2
高相应比优先调度算法-每个进程到达时cpu还在执行之前的进程
| 进程 | 到达时间 | 执行时间 | 开始时间 | 结束时间 | 等待时间 |
| 1 | A | T1 | A | A+T1 | 0 |
| 4 | D | T4 | A+T1 | A+T1+T4 | T1-D |
| 2 | B | T2 | A+T1+T4 | A+T1+T2+T4 | T1+T4-B |
| 3 | C | T3 | A+T1+T4+T2 | A+T1+T4+T3+T2 | T1+T4+T2-C |
表1-3
高相应比优先调度算法:再执行完进程3时进程2的优先级为(T1-B)/T2+1,
进程3的优先级为(T1-C)/T3+1,进程4的优先级为(T1-D)/T4+1。3个进程优先级比较大小,因为B>C>D,所以T1-B<T1-C<T1-D。又因为T2>T3>T4,所以无法比较,这里假设进程4的优先级最大,即T1T3-T3D>T1T4-T4C.再执行完进程2时,进程3与进程4的等待时间又变了,所以需要重新计算,进程3的优先级为(T1+T4-C)/T3+1,进程2的优先级为(T1+T4-B)/T2+1,T1+T4-C<T1+T3-D且T2>T3.无法比较,这里假设进程2的优先级大,即T2(T1+T4)-T2C<T3(T1+T4)-T3B,与上面假设不冲突
模型二
每个进程到达时cpu已经处理完之前的进程
| 进程 | 到达时间 | 执行时间 | 开始时间 | 结束时间 | 等待时间 |
| 1 | A | T1 | A | A+T1 | 0 |
| 2 | B | T2 | B | B+T2 | 0 |
| 3 | C | T3 | C | C+T3 | 0 |
| 4 | D | T4 | D | D+T4 | 0 |
表2-1
6. 模型求解
模型一
先来先服务调度算法:时间总和为4T1+3T2+2T3+T4,即T=(4T1+3T2+2T3+T4-B-C-D)/4。
W=(1+(T1+T2-B)/T2+(T1+T2+T3-C)/T3+(T1+T2+T3+T4-D)/T4)/4。
短作业优先算法:因为T2>T3>T4,并且假设3个进程到达之前T1还没有执行完,所以按照短作业优先算法时,进程4先执行,再执行进程3,最后在执行进程4。时间总和为4T1+3T4+2T3+T2,即
T=(4T1+3T4+2T3+T2-B-C-D)/4。
W=(1+(T1+T4-D)/T4+(T1+T4+T3-C)/T3+(T1+T4+T3+T2-B)/T2)/4
高相应比优先调度算法:T=(4T1+3T4+2T2+T3-B-C-D)/4。
W=(1+(T1+T4-D)/T4+(T1+T4+T2-B)/T2+(T1+T4+T3+T2-C)/T3)/4。
3种进行比较T(FCFS)>T(HRRN)>T(SJF),W(FCFS)>W(HRRN)>W(SJF)
模型二
因为每个进程到达时cpu已经处理完之前的进程,并且A<B<C<D,所以3种算法的执行都是相同的且T=W=1.
综上所述T(FCFS)>=T(HRRN)>=T(SJF),W(FCFS)>=W(HRRN)>=W(SJF)
7. 模型检验
用c语言随机生成5000个进程进行计算结果符合
c语言执行结果
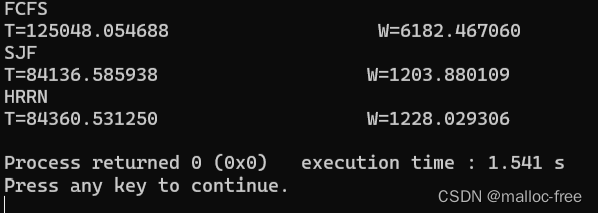
图1
c代码
#include <stdio.h>
#include <stdlib.h>
typedef struct
{int arrived;int serve;int priority;long wait;
}Hrrn;
typedef struct
{int arrived;int serve;long wait;
}Fcfs;
typedef struct
{int arrived;int serve;long wait;
}Sjf;void FCFS(Fcfs *fcfs,int n) //先来先服务算法
{long now = 0; //cpu从处理到现在所用的时间for (int i=0;i<n;i++){if(now >= fcfs[i].arrived) //如果有进程到达 直接加时间now+=fcfs[i].serve;else //如果没有进程到达 需要更新为到达时间now = fcfs[i].arrived+fcfs[i].serve;for(int j=i+1;j<n;j++) //更新等待时间{if(now > fcfs[j].arrived)fcfs[j].wait=now-fcfs[j].arrived;}}long total=0;double totalserve=0;for (int i=0;i<n;i++){total+=(fcfs[i].wait+fcfs[i].serve); //总的周转时间totalserve+=(fcfs[i].wait+fcfs[i].serve)/(double)fcfs[i].serve; //带权周转时间}printf("FCFS\nT=%f W=%f\n",total/(float)n,(totalserve/(double)n));
}
void SJF(Sjf *sjf,int n) //短作业优先算法
{Sjf *temp = malloc(sizeof(Sjf));for(int p=n/2;p>0;p/=2) // 希尔排序 按照作业长短排序 一样的按照先后{for (int i=p;i<n;i++){*temp=sjf[i];int j;for (j=i;j-p>=0 && sjf[j-p].serve >= temp->serve;j-=p){if (sjf[j-p].serve > temp->serve) //第一排序为执行时间sjf[j] = sjf[j-p];else{if(sjf[j-p].arrived > temp->arrived) //第二排序为到达时间sjf[j] = sjf[j-p];elsebreak;}}sjf[j] = *temp;}}free(temp);int flag[10000]={0}; //标志哪一个没有没有执行 因为排序中短作业可能后来到达int now=0,nowloc=0; //now记录cpu从处理到现在的时间 nowloc为将要执行的位置for (int i=0;i<n;i++){for (int j=0;j<n;j++){if (now>=sjf[j].arrived && !flag[j]) //找最短的进程且没有执行过的{nowloc = j; //找到后记录break;}if(now<sjf[j].arrived && j==n-1) //如果没有进程 等1秒{j=-1;now+=1;}}now+=sjf[nowloc].serve; //执行的总时间flag[nowloc] = 1;for(int j=0;j<n;j++) //修改等待时间{if(now > sjf[j].arrived && !flag[j])sjf[j].wait=now-sjf[j].arrived;}}long total=0;double totalserve=0; //计算T Wfor (int i=0;i<n;i++){total+= (sjf[i].wait+sjf[i].serve);totalserve+=(sjf[i].wait+sjf[i].serve)/(double)sjf[i].serve;}printf("SJF\nT=%f W=%f\n",total/(float)n,(totalserve/(double)n));
}
void HRRN(Hrrn *hrrn,int n)
{long now = 0,loc=0;Hrrn *temp = malloc(sizeof(Hrrn)); //loc为后面还没有到达进程的位置for(int i=0;i<n;i++){if(now>hrrn[i].arrived)now += hrrn[i].serve;elsenow = hrrn[i].arrived+hrrn[i].serve;for (int j = i+1;j<n;j++) //每执行一个进程都要更新优先级 和等待时间{if (now>=hrrn[j].arrived){hrrn[j].wait = now-hrrn[j].arrived;hrrn[j].priority = hrrn[j].wait/hrrn[j].serve;}else //如果没有后面的进程都没到达 那么记录位置并结束{loc=j;break;}}for(int p=(loc-i)/2;p>0;p/=2) // 希尔排序 按照优先级排序 一样的按照先后 优先级在变 所以需要每次都排序{for (int ii=p;ii<loc;ii++){*temp=hrrn[ii];int j;for (j=ii;j-p>=i+1 && hrrn[j-p].priority <= temp->priority;j-=p) //第一排序为优先级 第二为到达时间{if (hrrn[j-p].priority < temp->priority)hrrn[j] = hrrn[j-p];else{if(hrrn[j-p].arrived > temp->arrived)hrrn[j] = hrrn[j-p];elsebreak;}}hrrn[j] = *temp;}}}free(temp);long total=0;double totalserve=0; //计算T Wfor (int i=0;i<n;i++){total+= (hrrn[i].wait+hrrn[i].serve);totalserve+=(hrrn[i].wait+hrrn[i].serve)/(double)hrrn[i].serve;}printf("HRRN\nT=%f W=%f\n",total/(float)n,(totalserve/(double)n));
}int main()
{int n=5000;int a;Sjf *sjf = malloc(n*sizeof(Sjf));Hrrn *hrrn = malloc(n*sizeof(Hrrn));Fcfs *fcfs = malloc(n*sizeof(Fcfs));for(int i=0;i<n;i++) //按照到达时间先后进行存储 再进行fcfs时不需要再排序{a=rand() %100+1; //随机生成1~100的数 为每一个进程的服务时间sjf[i].arrived=i;sjf[i].wait = 0;sjf[i].serve = a;fcfs[i].arrived = i;fcfs[i].serve = a;fcfs[i].wait = 0;hrrn[i].serve = a;hrrn[i].wait = 0;hrrn[i].priority = 0;hrrn[i].arrived = i;}FCFS(fcfs,n);SJF(sjf,n);HRRN(hrrn,n);free(fcfs);free(hrrn);free(sjf);
/* for(int i=0;i<n;i++){printf("%d %d %d %d\n",hrrn[i].arrived,hrrn[i].serve,hrrn[i].wait,hrrn[i].priority);}*/
}
这篇关于数学模型:操作系统中FCFS、SJF、HRRN算法的平均周转时间比较 c语言的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


