本文主要是介绍GPT-4o仅排第二!北大港大等6所高校联手,发布权威多模态大模型榜单!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多模态大模型视频分析能力榜单出炉:
Gemini 1.5 Pro最强,GPT-4o仅排第二? 曾经红极一时的GPT-4V屈居第三。
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
最近,北大港大等6所高校联手,发布首个专为视频分析设计的多模态大模型评估基准——Video-MME。在该基准中,冠军Gemini 1.5 Pro甩开第二名GPT-4o近10分,第三名GPT-4V近15分。
而在开源模型中,最高分为LLaVA-NeXT-Video,但总体准确率只有52.5%,远远不及商业模型,还有较大提升空间。
论文标题:
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
论文链接:
https://arxiv.org/pdf/2405.21075
Video-MME是首个专为视频分析设计的多模态大模型评估基准,包含900段视频,并为每段视频设计了2,700个高质量的多选题,如下图例子所示:


Video-MME涵盖6大视觉领域,包括知识、电影与电视、体育竞赛、艺术表演、生活记录和多语言,并进一步细分为天文学、科技、纪录片等30个类别,视频长度从11秒到1小时不等。此外,Video-MME还整合字幕和音频轨道,增强了对视频理解的多模态输入分析。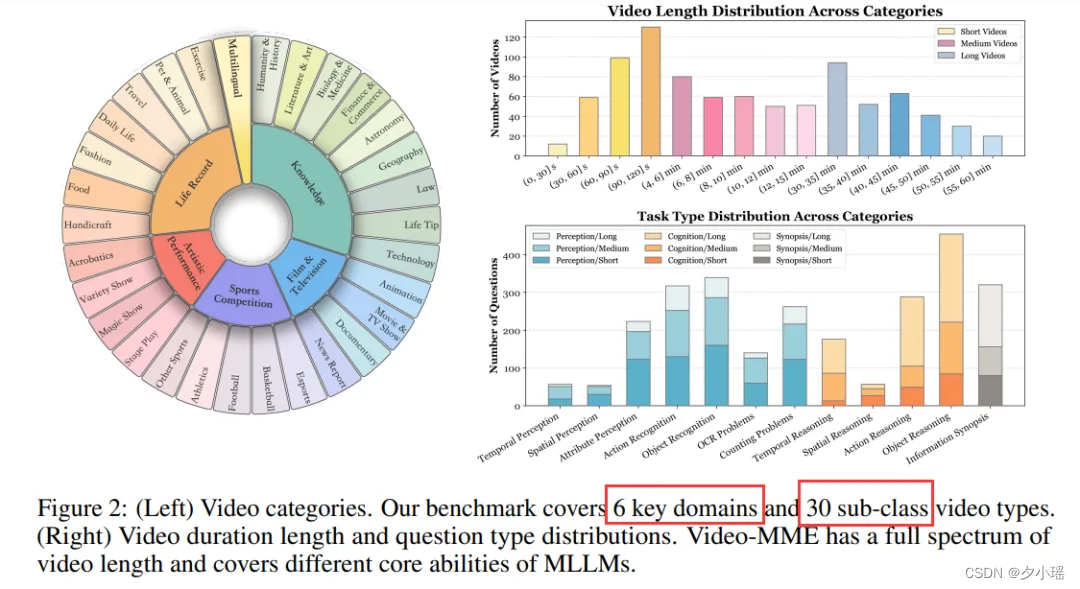
更难能可贵的是,Video-MME中所有数据,包括问答、视频、字幕和音频,都是手工收集和整理的,确保了该基准的高质量。数据集详细信息可在官方链接中获取:
https://video-mme.github.io/
Video-MME构建过程
Video-MME数据集的构建过程分为三个步骤:
-
视频收集:作者根据YouTube的流行趋势定义了6个关键领域:知识、电影与电视、体育竞赛、生活记录和多语言。每个领域又进一步细分为详细的标签,例如体育竞赛中的足球和篮球,总共得到30个精细分类的视频类别。然后从YouTube中收集不同长度的视频,包括短(少于2分钟)、中(4-15分钟)和长(30-60分钟)视频,同时还获取了视频的字幕与音频。
-
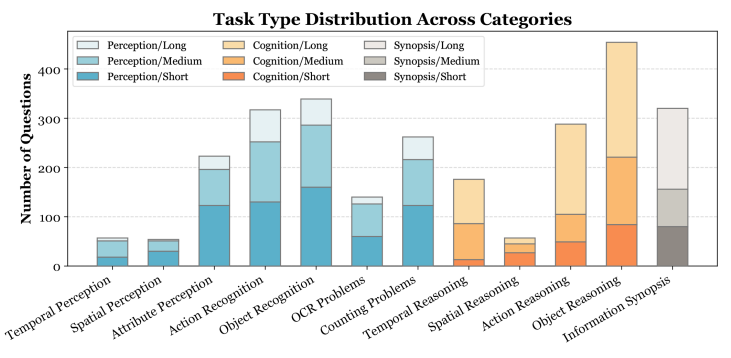
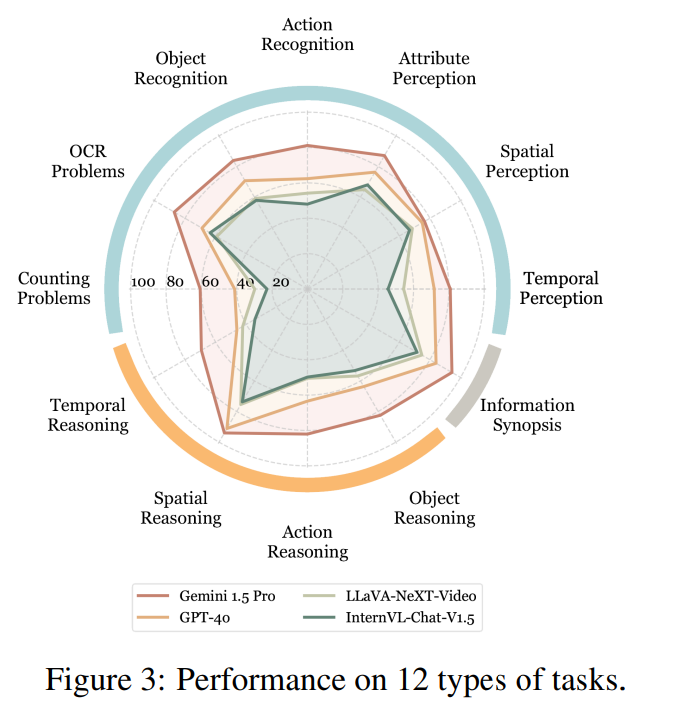
问题-答案标注:为方便评估,该基准采用选择题格式,由本文的所有作者人工标注。所有的标注人员首先观看整个视频内容,然后通过反复观看视频,为每个视频生成3个相关问题,每个问题有4个备选答案,总计获得2,700个QA对。问题类型共有12种如下图所示,包括感知、推理和信息概要等。
-
质量审查:不同的标注人员每个QA对交叉审核,确保语言表达准确、问题可答且答案合理。另外为增强问题挑战性,使用Gemini 1.5 Pro过滤需要视频辅助才能回答的QA对。也就是说将纯文本问题输入Gemini 1.5 Pro,如“2022年阿根廷的十大成就是什么?”这类不需要视频也能回答的问题将被过滤。Gemini 1.5 Pro在纯文本问题下的准确率低于15%。
最终Video-MME包含总共900个视频、713个字幕和869个音频文件,大多数视频都配有字幕和音频,为研究外部信息对视频理解性能的影响提供了宝贵的资源。
Video-MME统计分析
QA对质量分析
经过统计,Video-MME中QA对的风格相对统一、答案分布均匀,确保了评价的公平。如下表所示,问题、选项和答案的单词数在不同视频长度之间表现出明显的一致性。四个答案选项(A/B/C/D)的分布较为接近,分别为25.2%/27.2%/25.2%/22.3%。另一方面,字幕的单词数随着视频长度的增加而显著增加,例如,短视频的平均单词数为200.9,而长视频子集的单词数可达6,500。随着字幕的增加量表明较长的视频包含更多信息。
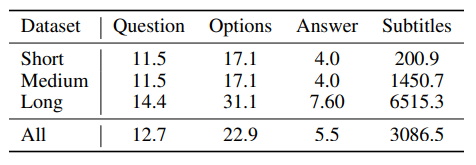
▲Video-MME-S/M/L表示短/中/长部分
Video-MME挑战性分析
在视频分析领域,确定一个QA对是否有难度,可采用“Certificate Length Analysis(证书长度分析)”的方法[1]。证书长度计算为识别出的子片段的总时长之和。从下表中可以看到,对于短、中、长视频,其证书长度的中位数分别为26.0秒、167.3秒和890.7秒。与EgoSchema的证书长度相比,Video-MME的中长视频子集需要更长的视频内容理解才能回答问题,也就是说更具挑战性。
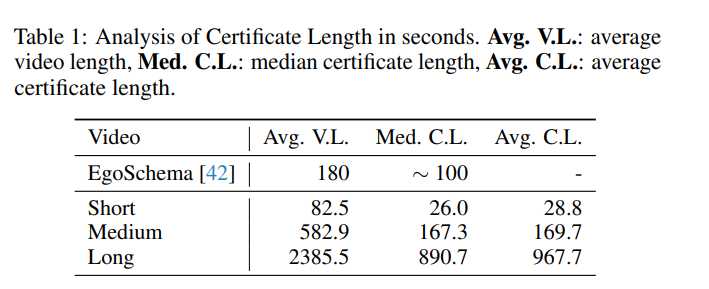
Video-MME VS. 其他基准
传统视频基准如MSRVTT-QA、MSVD-QA等多聚焦于电视视频等特定领域,缺乏层次结构,不适用于全面诊断MLLMs的局限性。尽管有一些基准如TempCompass和MVBench涉及开放领域和多级评估,但视频时长较短。
Video-MME作为首个涵盖开放领域、时长从11秒至1小时的手动标注的基准,评估了多层次视频理解能力,并包含字幕、音频等元信息,可全面推动为MLLMs的评估与开发。
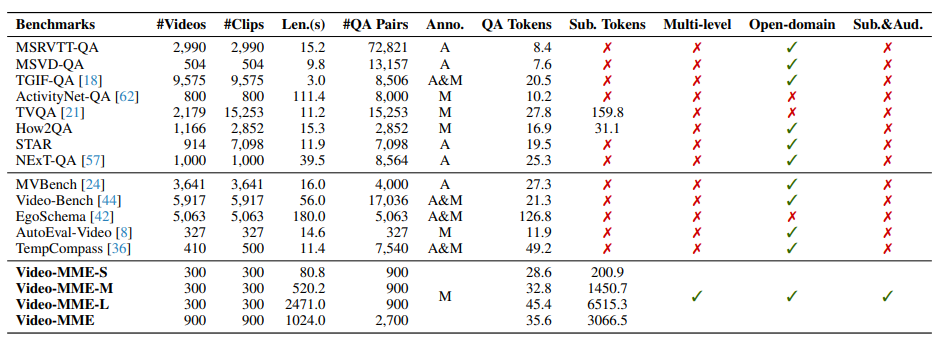
详细分析MLLMs在Video-MME上的表现
评估采用“整段视频帧+完整字幕(可选)+带有提示的问题”的格式。默认模型的原有的提示,如果没有则使用如下常见的提示:

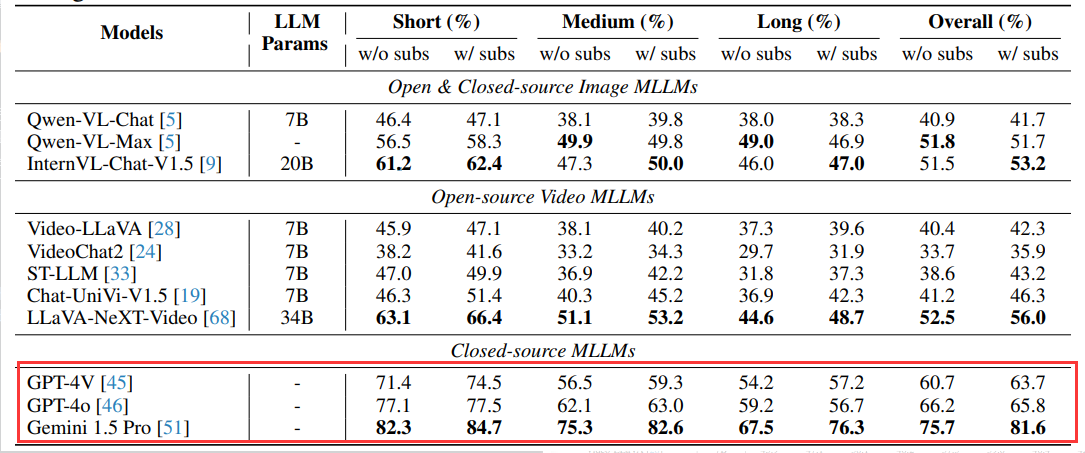
正如前文提到,在3个商业模型以及5个开源视频多模态语言模型,还有3个先进的图像多模态语言模型的横向对比中,Gemini 1.5 Pro大获全胜。

Gemini 1.5 Pro表现突出
另外,如下图所示,Gemini 1.5 Pro在六大视频类别中,电影与电视识别准确率最高(79.1%),体育竞赛最低(71.1%)。随着视频时长增长,其性能下降14.8%,凸显了模型在捕捉长时序关系方面的不足。尽管如此,Gemini 1.5 Pro在长视频上的表现仍超越所有开源模型在短视频上的性能。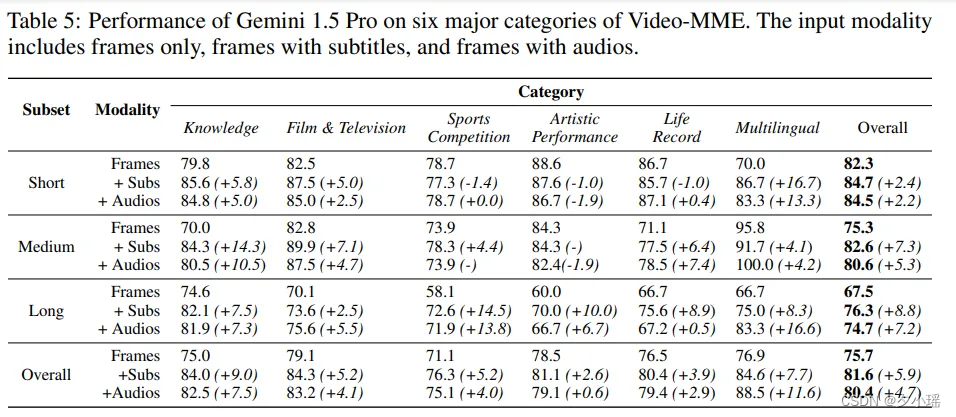
除视觉帧外,Gemini 1.5 Pro还支持字幕和音频输入,**在融合了音频后,长视频中准确率提高了7.2%,特别是多语言类别提高了16.6%**。这表明,字幕和音频对于提升模型的视频理解能力有所帮助。
开源模型仍存在显著差距
在不同类的任务中,开源模型如LLaVA-NeXT-Video和InterVL-Chat-V1.5离商业模型还有很大的差距,特别是在计数问题、动作识别和时间感知方面,差距明显。
Video-MME也可用于评估图像MMLMs
除了视频多模态模型,Video-MME也可用于评估图像MMLMs。据下表所示,基于图像的Qwen-VL-Max和InterVL-Chat-V1.5模型在性能上与LLaVA-NeXT-Video相当,这一发现充分展示了图像MMLMs在序列数据处理上的出色泛化能力。同时,这也进一步强调了图像理解作为视频理解基础的重要地位。
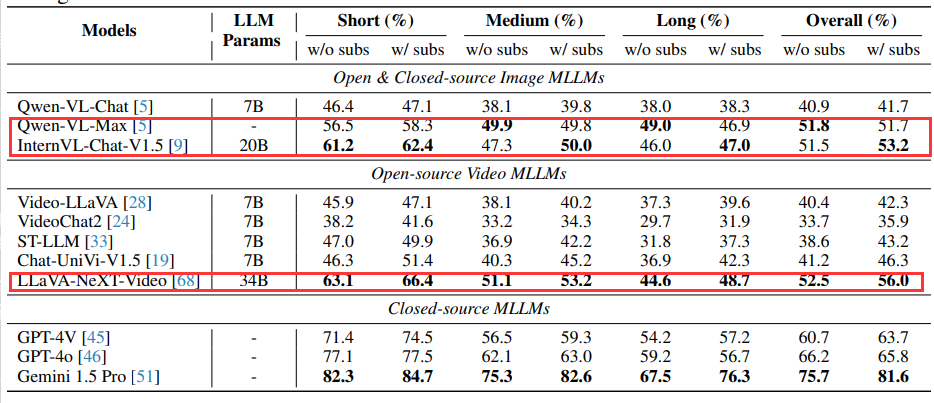
除此之外,本文还做了额外的分析,探索哪些因素会影响模型视频理解的性能。
影响视频理解性能的因素有哪些
额外的模态是否能提升性能
大多数评估仅使用视频帧作为输入,要求模型仅依赖视觉上下文来回答问题。然而,许多视频本质上包含来自其他模态的额外信息,如字幕和音频。
视频本身就是一个多模态集合体,除了视觉帧外,还包含字幕、音频等其他模态,这些模态对视频理解是否有帮助?答案是肯定的。
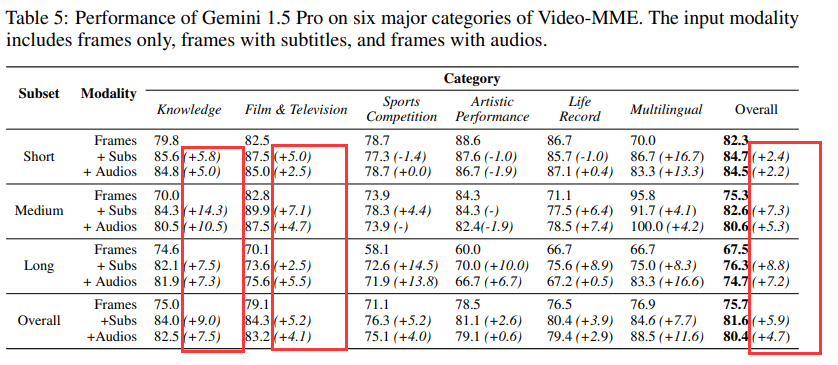
作者发现:
-
引入字幕和音频能显著提升模型性能。 例如,Gemini 1.5 Pro在添加音频后,长视频准确率提高了16.6%,额外的模态为回答问题提供了关键信息。
-
对于长视频,字幕和音频的作用尤为明显。在短视频中,字幕仅带来2.4%的提升,但在长视频中提升至8.8%,这可能是因为长视频包含更多需要推理的难题,需要模型利用更多模态信息。
-
在多模态模型中,字幕比音频更有效。字幕主要捕捉语音内容,而音频则包含更多环境声音。在实验中,字幕通常带来更高的性能提升。特别在多语言任务中字幕质量对效果的影响很大。
MLLMs如何应对不同视频时长的挑战?
通过对比不同模型在短、中、长视频上的性能,作者发现随着视频时长增加,无论是开源还是商业模型,性能均出现显著下滑。
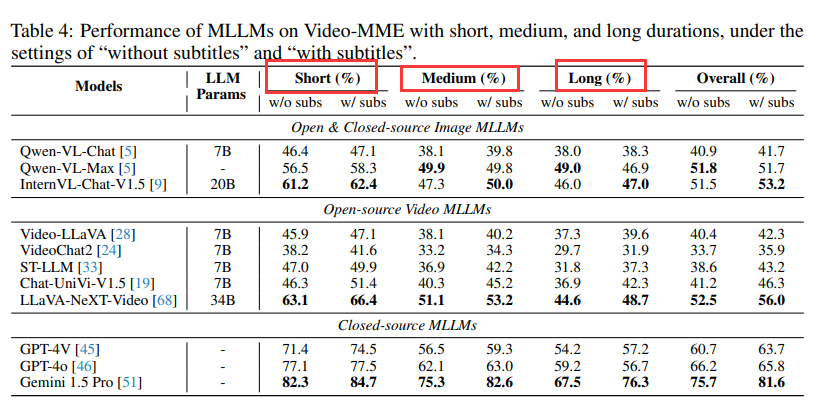
LLaVA-NeXT-Video的准确率从短视频到中视频减少了12%,从短视频到长视频更是减少了18.5%;而Gemini 1.5 Pro的准确率也分别下降了7%和14.8%。
性能下降的原因本文主要总结了三点:
-
一是长视频中困难任务比例增加,尤其是推理问题增多,对模型构成更大挑战;
-
二是帧采样稀疏,导致输入信息减少,许多模型固定输入帧数,如8帧,这在长视频中造成信息密度过低,影响模型预测;
-
三是长文本理解难度增大,即使Gemini 1.5 Pro增加了帧采样数,长上下文理解仍是一个挑战。
虽然引入额外模态如字幕,可以有效补充缺失信息,提升模型性能。但部分开源MLLMs仅支持有限的输入帧难以理解长序列任务,因此需要创新的架构来扩展上下文。在未来提升多模态大模型的长序列理解能力将成为一大研究趋势。
结语
数据集是大模型领域技术进步的基石,相比文本和图像数据集来说,目前视频数据集仍然不足,特别是涉及长视频的复杂高质量数据集更是凤毛麟角。本文提出的首个全面的视频分析多模态基准——Video-MME正好弥补了这一不足。其涵盖了各种类型的视频、不同的时长和多种数据模态,所有内容都配以高质量、专家标注的问答对,对于现有的开源模型来说极具挑战性,相信其能激发MLLMs的进一步发展的需求。


参考资料
[1]K. Mangalam, R. Akshulakov, and J. Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. In NeurIPS, 2024.
这篇关于GPT-4o仅排第二!北大港大等6所高校联手,发布权威多模态大模型榜单!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








