本文主要是介绍InfluxDB存储数据是否需要水平拆分表?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
业务场景是这样:8000个点,每秒存一次,存3个月,大约600亿条记录。
如果保存策略RP的保留是90天,那么分片shard的时长在一天就比较合理,那么一天的量就是:8,000×3,600×24=691,200,000,大概每天近7亿条数据。这个量对于influxdb单机来说是够用了,除非每条记录量的确很大,那么可以考虑采购商业版本做成分布式来提升磁盘I/O性能。
无需你再去做所谓的表水平切分,毫无意义。水平分表针对的都是按行存储与索引的传统关系型数据库,水平分表的逻辑还是按key或者时间进行行集的范围划分,加快定位,减少扫描。对于influxdb,其底层存储设计理念完全不同于传统关系表数据库,它的TSM数据模型源自于nosql常用的LSM-Tree数据模型设计,又远胜于此模型,是基于时序TS数据的特定优化,
至于按时间范围查询会不会很慢?这个问题,其实这种忧虑是多余的,这就需要理解其分片存放和TSM结构:
按照这种保留策略,每隔一天就会形成一个分片目录,存放一天的TSM数据,那么无论是600亿还是6000亿,按照时间范围查询一定是先根据目录索引。如果你是influxdb集群,例如:8个节点,2个副本,相当于对一天的数据又切成了四分,也就是一个节点的某个分片目录只对应了1.7亿的数据,集群的分布这会让读写更快。
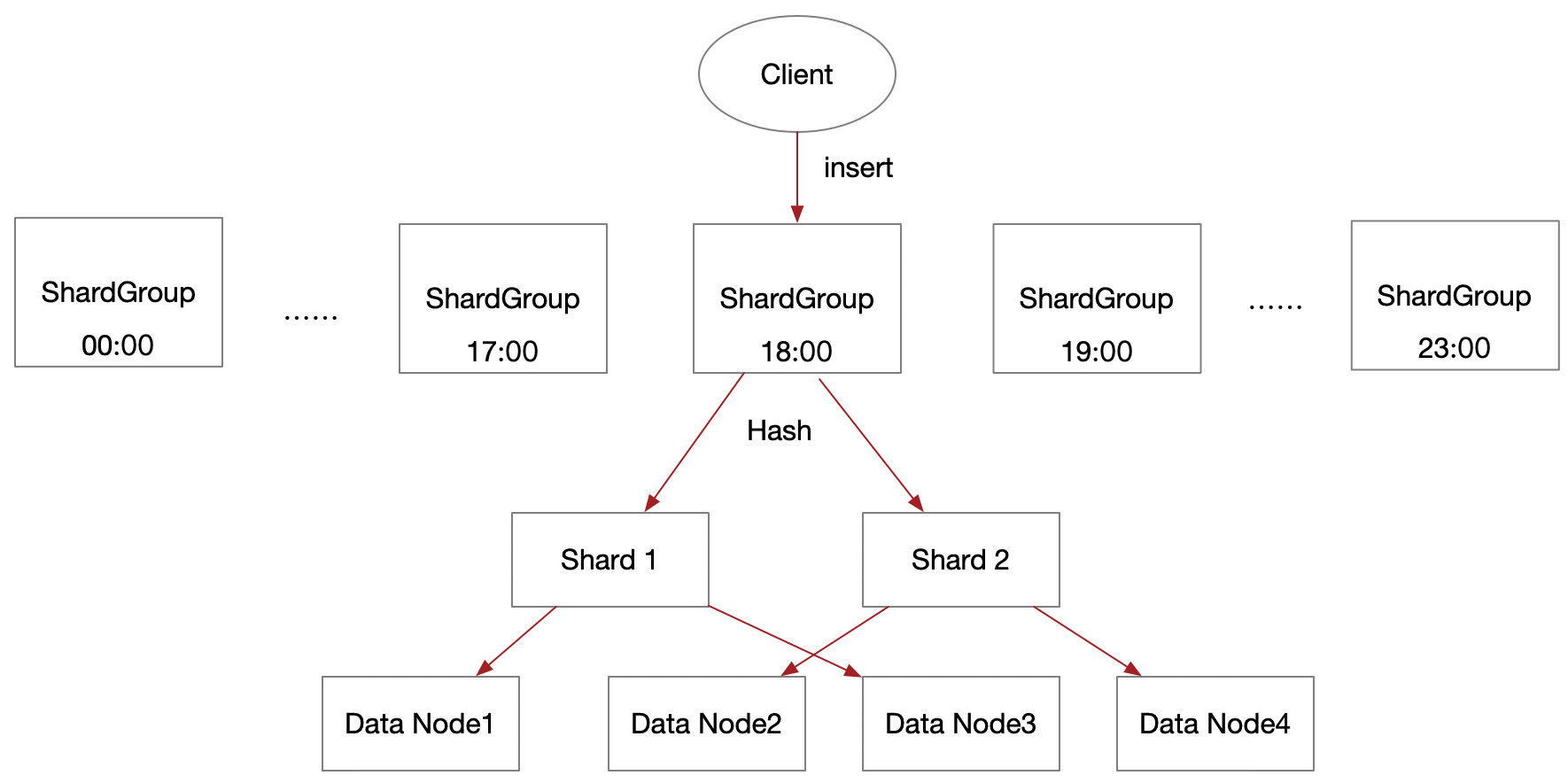
我们在细究到influxdb时间查询问题的内部,influxdb为什么用时间范围查就一定很快,上面聊的是分片的文件目录优化带来的查询性能提升,其实tsm文件本身就分成了数据块集合和索引块集合两部分,一个数据块就是由时间戳(timestamps)的集合与值(values)的集合组成。索引块由N个索引实体组成,每个索引实体提供了数据块最小时间和最大时间的偏移量,这个时间范围就定位到了要取的数据块,因此查询的时候,Series + field作为主键定位一个索引块,然后用时间范围在索引块中去定位匹配的一组索引实体,也就很快定位到了匹配的数据块集合。
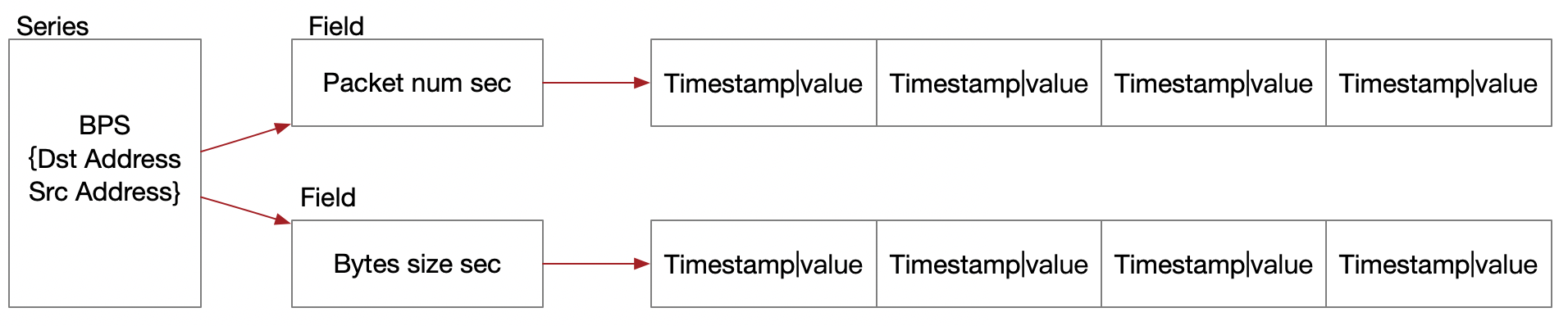
我们在细究到它的内部结构原理上,influxdb的存储是按照Series+field的方式存储时间戳与数据块集合,内存中还原后类似Series+field={timestamp1:value1,timestamp2:value2,..}这种结构,典型的列式结构,查询时按照series作为行键进行fields列的排序成行,输出结果,这又类似于列簇的结构,明显看出要比常见的按k/v单元存储之上增强了V的按时间线的聚合性。这就完美地匹配了时序数据的特征,数据块中时间戳的聚合排列以及fields值的聚合排列,带来了惊人的压缩效率,同样按照时间范围的查询效率更为惊人!
因此我们可以看到,influxdb就是玩时间线存储的高手,这也是为什么几个亿的记录让它用时间范围去匹配,很轻松达到秒级以内别速度。
守护石 「技术创作」
关注领域:大数据技术、分布式架构 | 技术管理![]() http://www.readbyte.com/
http://www.readbyte.com/
这篇关于InfluxDB存储数据是否需要水平拆分表?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





