本文主要是介绍深度探索Hadoop分布式文件系统(HDFS)数据读取流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 开篇
Hadoop分布式文件系统(HDFS)是Hadoop大数据生态最底层的数据存储设施。因其具备了海量数据分布式存储能力,针对不同批处理业务的大吞吐数据计算承载力,使其综合复杂度要远远高于其他数据存储系统。
因此对Hadoop分布式文件系统(HDFS)的深入研究,了解其架构特征、读写流程、分区模式、高可用思想、数据存储规划等知识,对学习大数据技术大有裨益,尤其是面临开发生产环境时,能做到胸中有数。
本文重点从客户端读取HDFS数据的角度切入,通过Hadoop源代码跟踪手段,层层拨开,渐渐深入Hadoop机制内部,使其读取流程逐渐明朗化。
2. HDFS数据读取整体架构流程
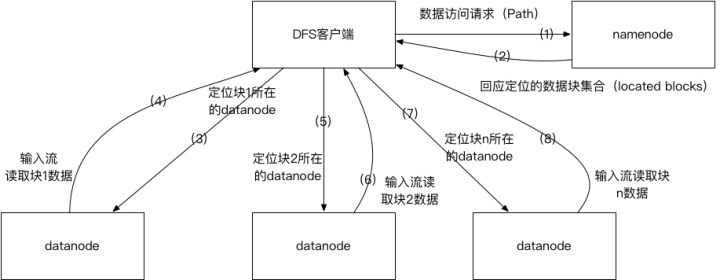
HDFS数据访问整体架构流程
如上图所示:描绘了客户端访问HDFS数据的简化后整体架构流程。
(1)客户端向hdfs namenode节点发送Path文件路径的数据访问的请求
(2)Namenode会根据文件路径收集所有数据块(block)的位置信息,并根据数据块在文件中的先后顺序,按次序组成数据块定位集合(located blocks),回应给客户端
(3)客户端拿到数据块定位集合后,创建HDFS输入流,定位第一个数据块所在的位置,并读取datanode的数据流。之后根据读取偏移量定位下一个datanode并创建新的数据块读取数据流,以此类推,完成对HDFS文件的整个读取。
3. Hadoop源代码分析
经过上述简单描述,我们对客户端读取HDFS文件数据有了一个整体上概念,那么这一节,我们开始从源代码跟踪的方向,深度去分析一下HDFS的数据访问内部机制。
(一) namenode代理类生成的源代码探索
为什么我们要先从namenode代理生成说起呢?原因就是先了解清楚客户端与namenode之间的来龙去脉,再看之后的数据获取过程就有头绪了。
(1) 首先我们先从一个hdfs-site.xml配置看起
<property><!-- namenode高可用代理类 --><name>dfs.client.failover.proxy.provider.fszx</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
配置中定义了namenode代理的提供者为ConfiguredFailoverProxyProvider。什么叫namenode代理?其实本质上就是连接namenode服务的客户端网络通讯对象,用于客户端和namenode服务端的交流。
(2) 接着我们看看ConfiguredFailoverProxyProvider的源代码继承关系结构
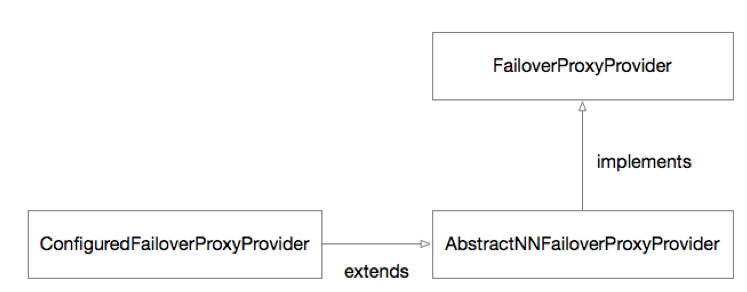
ConfiguredFailoverProxyProvider继承关系图
上图是ConfiguredFailoverProxyProvider的继承关系,顶端接口是FailoverProxyProvider,它包含了一段代码:
/*** Get the proxy object which should be used until the next failover event* occurs.* @return the proxy object to invoke methods upon*/public ProxyInfo<T> getProxy();这个方法返回的ProxyInfo就是namenode代理对象,当然客户端获取的ProxyInfo整个过程非常复杂,甚至还用到了动态代理,但本质上就是通过此接口拿到了namenode代理。
(3) 此时类关系演化成如下图所示:
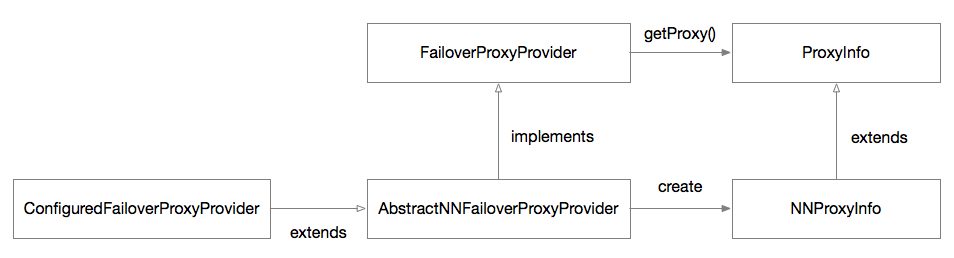
namonode创建过程类关系图
上图ProxyInfo就是namenode的代理类,继承的子类NNProxyInfo就是具体指定是高可用代理类。
(4) 那么费了这么大劲搞清楚的namenode代理,它的作用在哪里呢?
这就需要关注一个极为重要的对象DFSClient了,它是所有客户端向HDFS发起输入输出流的起点,如下图所示:
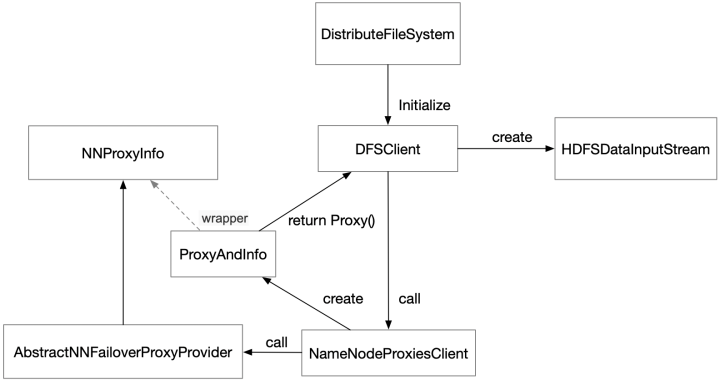
DFSClient初始化过程类关系图
上图实线代表了真实的调用过程,虚线代表了对象之间的间接关系。我们可以看到DFSClient是一个关键角色,它由分布式文件系统对象(DistributeFileSystem)初始化,并在初始化中调用NameNodeProxiesClient等一系列操作,实现了高可用NNproxyInfo对象创建,也就是namenode代理,并最终作为DFSClient对象的一个成员,在创建数据流等过程中使用。
(二) 读取文件流的深入源代码探索
(1) 首先方法一样,先找一个切入口。建立从HDFS下载文件到本地的一个简单场景,以下是代码片段:
……
//打开HDFS文件输入流
input = fileSystem.open(new Path(hdfs_file_path));
//创建本地文件输出流
output = new FileOutputStream(local_file_path);
//通过IOUtils工具实现数据流字节循环复制
IOUtils.copyBytes(input, output, 4096, true);
……咱们再看看IOUtils的一段文件流读写的方法代码:
/*** Copies from one stream to another.* * @param in InputStrem to read from* @param out OutputStream to write to* @param buffSize the size of the buffer */public static void copyBytes(InputStream in, OutputStream out, int buffSize) throws IOException {PrintStream ps = out instanceof PrintStream ? (PrintStream)out : null;byte buf[] = new byte[buffSize];int bytesRead = in.read(buf);while (bytesRead >= 0) {out.write(buf, 0, bytesRead);if ((ps != null) && ps.checkError()) {throw new IOException("Unable to write to output stream.");}bytesRead = in.read(buf);}}这段代码是个标准的循环读取HDFS InputStream数据流,然后向本地文件OutputStream输出流写数据的过程。我们的目标是深入到HDFS InputStream数据流的创建和使用过程。
(2) 接下来我们开始分析InputStream的产生过程,如下图所示:
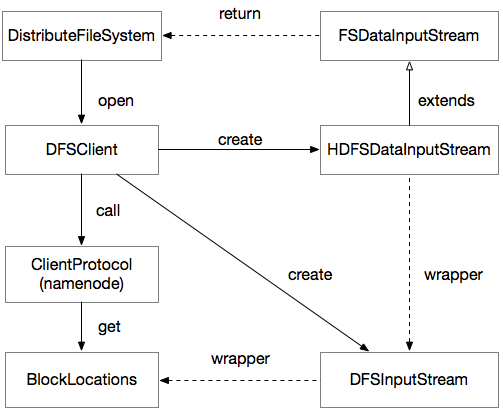
InputStream打开流程类关系图
上图实线代表了真实的调用过程,虚线代表了对象之间的间接关系。其代码内部结构极为复杂,我用此图用最简化的方式让我们能快速的理解清楚他的原理。
我来简单讲解一下这个过程:
第一步是DistributeFileSystem通过调用DFSClient对象的open方法,实现对DFSInputStream对象的创建,DFSInputStream对象是真正读取数据块(LocationBlock)以及与datanode交互的实现逻辑,是真正的核心类。
第二步,DFSClient在创建DFSInputStream的过程中,需要为其传入调用namenode代理而返回的数据块集合(LocationBlocks)。
第三步,DFSClient创建一个装饰器类HDFSDataInputStream,封装了DFSInputStream,由装饰器的父类FSDataInputStream最终返回给DistributeFileSystem,由客户端开发者使用。
(3) 最后我们再深入到数据块读取机制的源代码上看看,如下图所示:
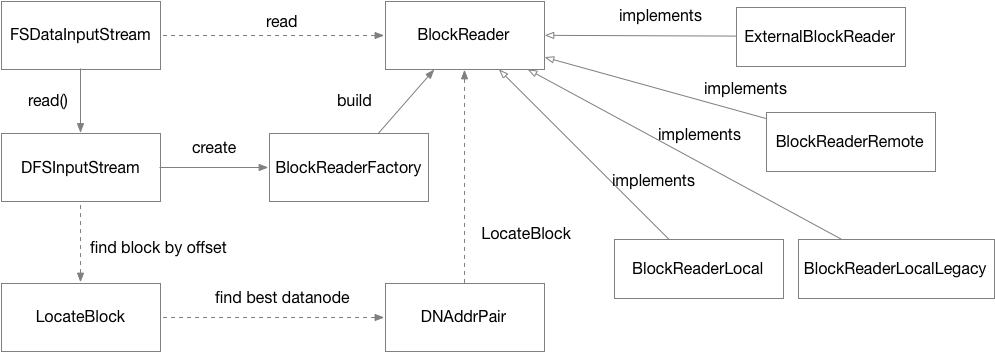
DFSInputStream数据读取流程类关系图
上图实线代表了真实的调用过程,虚线代表了对象之间的间接关系。实际的代码逻辑比较复杂,此图也是尽量简化展现,方便我们理解。
一样的,我来简单讲解一下这个过程:
第一步FSDataInputStream装饰器接受客户端的读取调用对DFSInputStream对象进行read(...)方法调用。
第二步 DFSInputStream会调用自身的blockSeekTo(long offset)方法,一方面根据offset数据偏移量,定位当前是否要读取新的数据块(LocationBlock),另一方面新的数据块从数据块集合(LocationBlocks)中找到后,寻找最佳的数据节点,也就是Hadoop所谓的就近原则,先看看本机数据节点有没有副本,再次根据网络距离着就近获取副本。
第三步通过FSDataInputStream副本上数据块(LocationBlock)构建BlockReader对象,它就是真正读取数据块的对象。BlockReader对象它有不同的实现,由BlockReaderFactory.build根据条件最优选择具体实现,BlockReaderLocal和BlockReaderLocalLegacy(based on HDFS-2246)是优选方案,也是short-circuit block readers方案,相当于直接从本地文件系统读数据了,若short-circuit因为安全等因素不可用,就会尝试UNIX domain sockets的优化方案,再不行才考虑BlockReaderRemote建立TCP sockets的连接方案了。BlockReader的细节原理也非常值得深入一探究竟,待下次我专门写一篇针对BlockReader原理机制文章。
4. 结束
非常感觉您能看完。下一篇我会对“Hadoop分布式文件系统(HDFS)数据写入流程”做一篇深度探索分析。期盼您的关注。
守护石 「技术创作」
关注领域:大数据技术、分布式架构 | 技术管理![]() http://www.readbyte.com/
http://www.readbyte.com/
这篇关于深度探索Hadoop分布式文件系统(HDFS)数据读取流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



