本文主要是介绍华为端云一体化开发 初始化云db表结构和表数据(实践2.0)(HarmonyOS学习第七课),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实例介绍:黑马鸿蒙刷题学习过程

1. 静态页面准备
借用黑马完成的页面,已经提供给大家一套写好的基本模板,大家直接将这套模板覆盖原有entry/src/main目录就可以
📎main.zip![]() https://www.yuque.com/attachments/yuque/0/2024/zip/8435673/1715414172346-8f97897d-729f-4de7-ac9c-52914c3e920d.zip
https://www.yuque.com/attachments/yuque/0/2024/zip/8435673/1715414172346-8f97897d-729f-4de7-ac9c-52914c3e920d.zip
页面中包含了基本的页面渲染和路由跳转还有一些弹窗的交互
解压后,覆盖项目中的 main文件夹 打开模拟器或者预览器
2. 初始化云db表结构和表数据
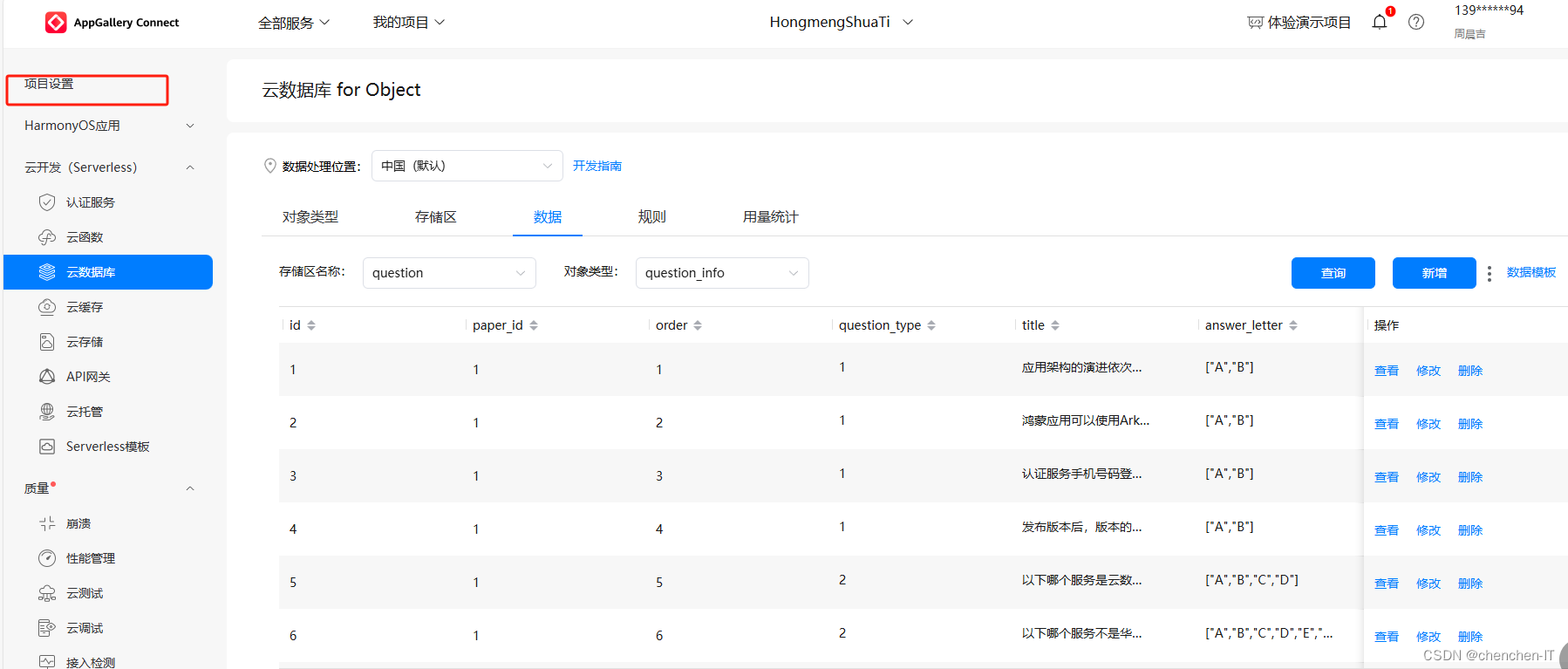
登录我们的AGC账号,打开云数据库存储
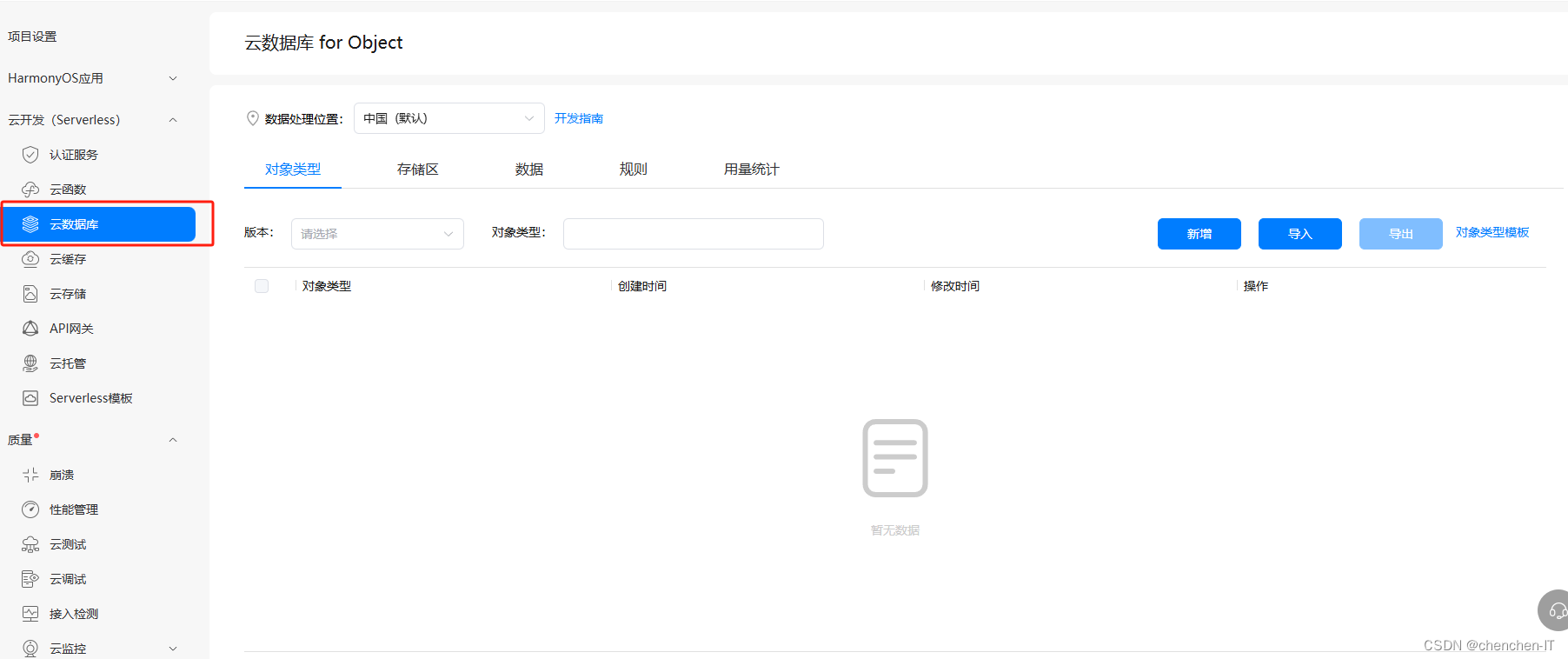 在这里可以新增你的表结构和数据类型,同时可以对数据进行增删改
在这里可以新增你的表结构和数据类型,同时可以对数据进行增删改
将自己所需要的数据和类型进行添加
类型如下:
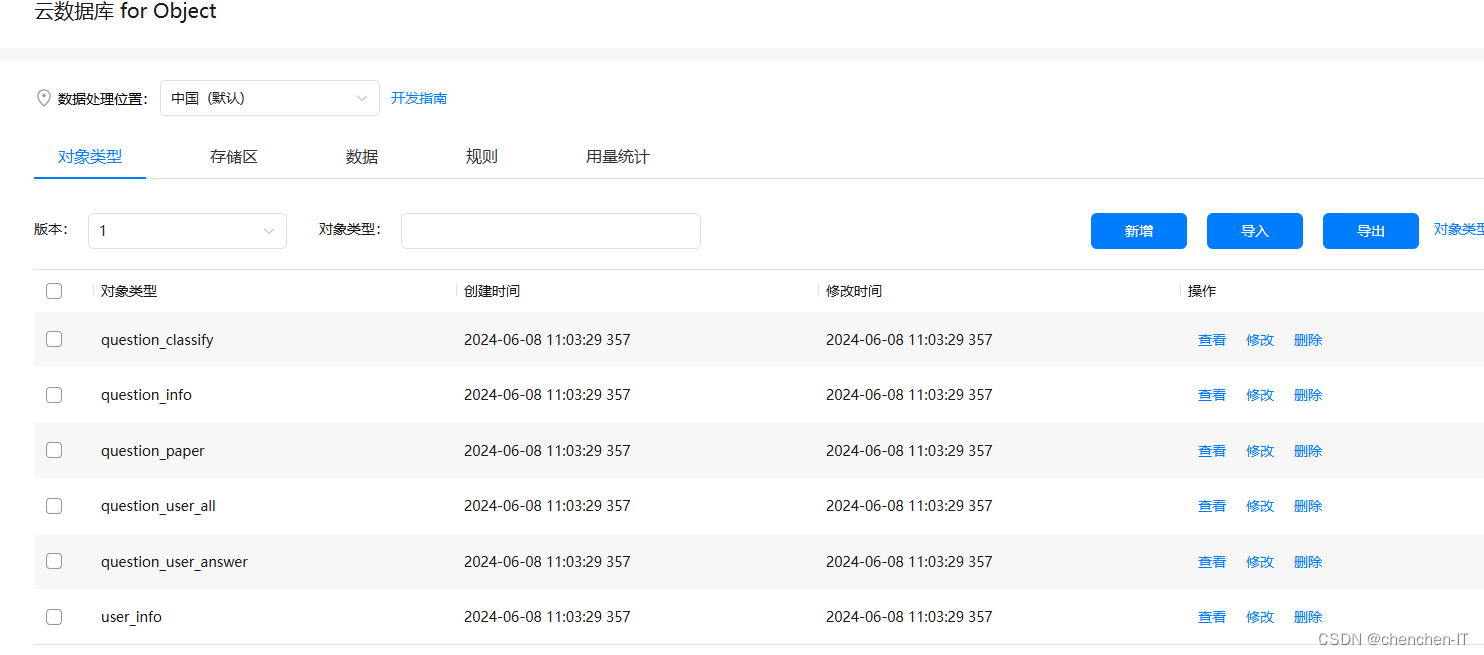
我们只是在这里进行了数据的添加,但是项目当中并没有我们添加的表结构
所以我们需要将表结构导出到我们的项目当中去
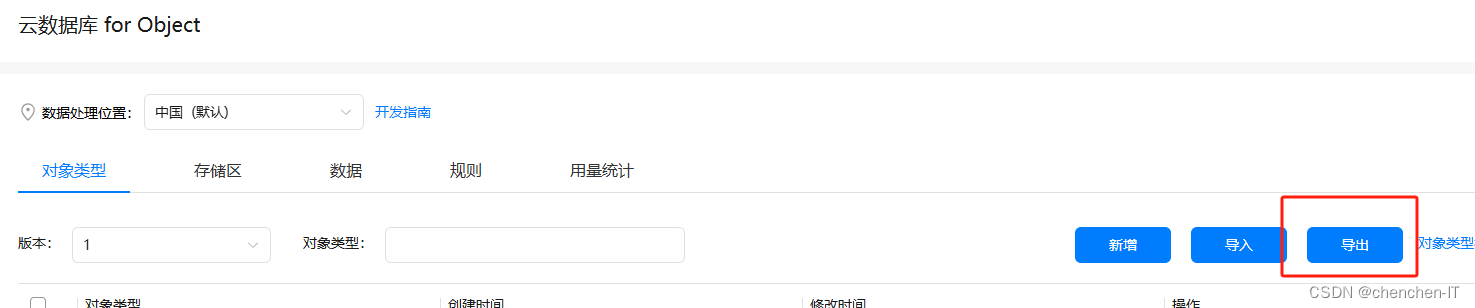
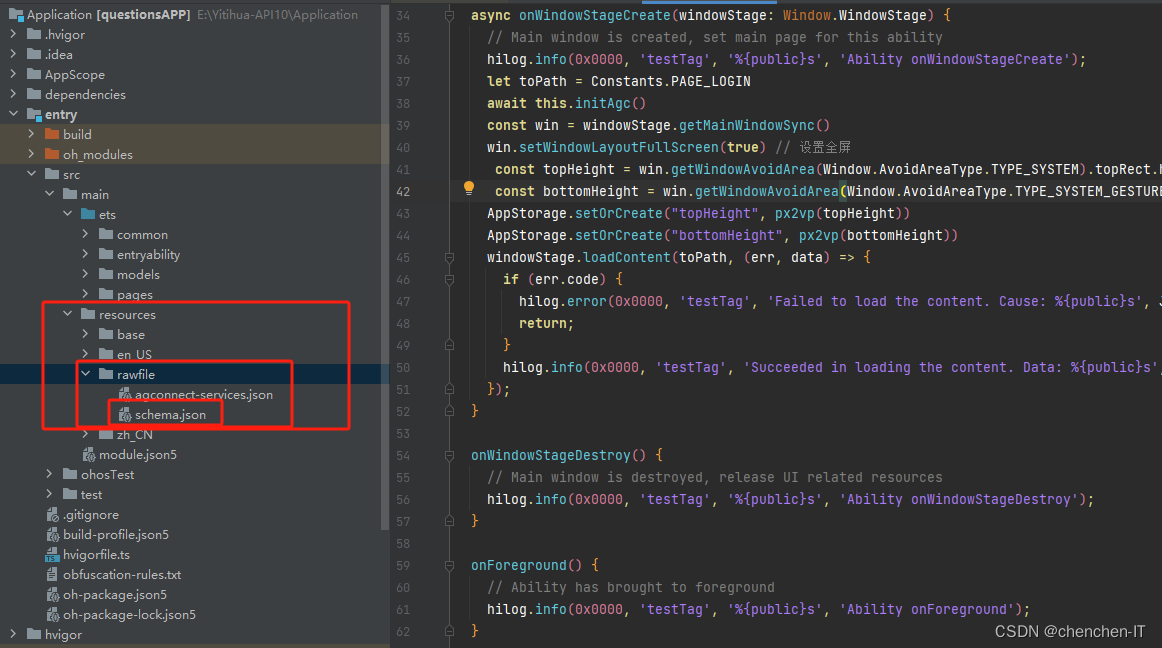
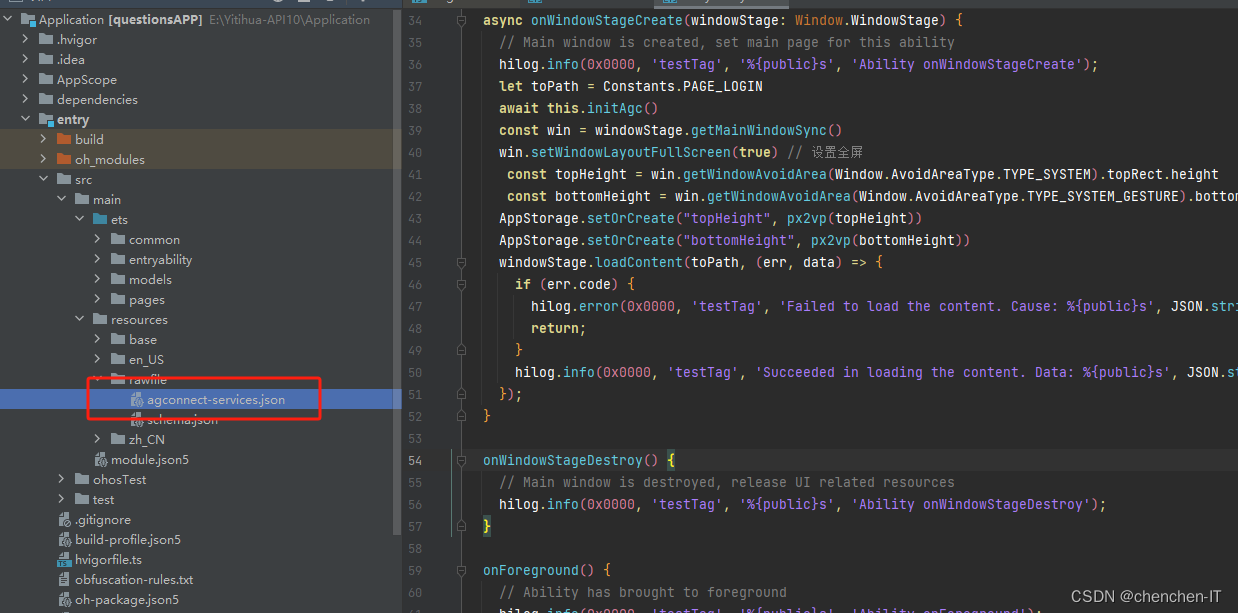
将导出的文件改名为schema.json放入到resources/rawfile目录下
3.新增question存储区
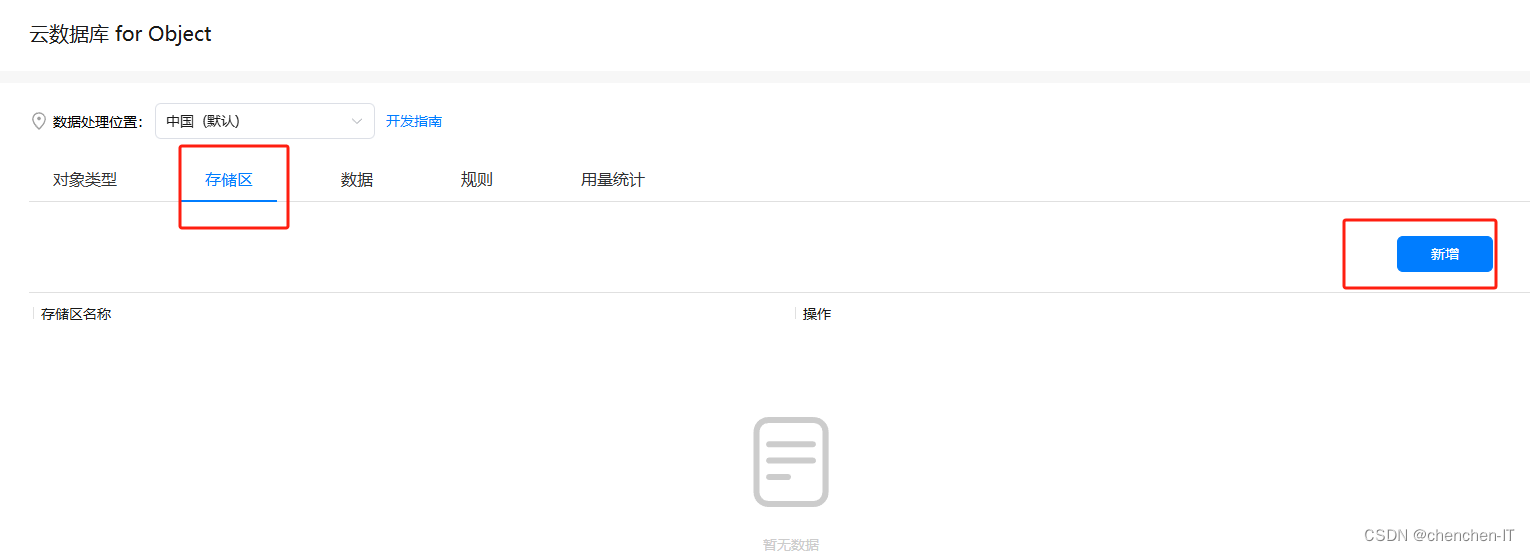
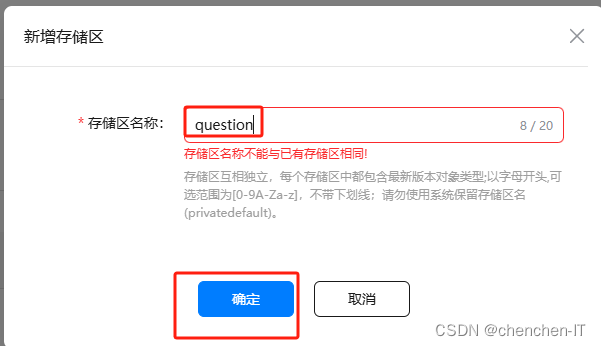
这里因为我本来就有这个所以会报错,正常添加即可
4.导入数据库数据
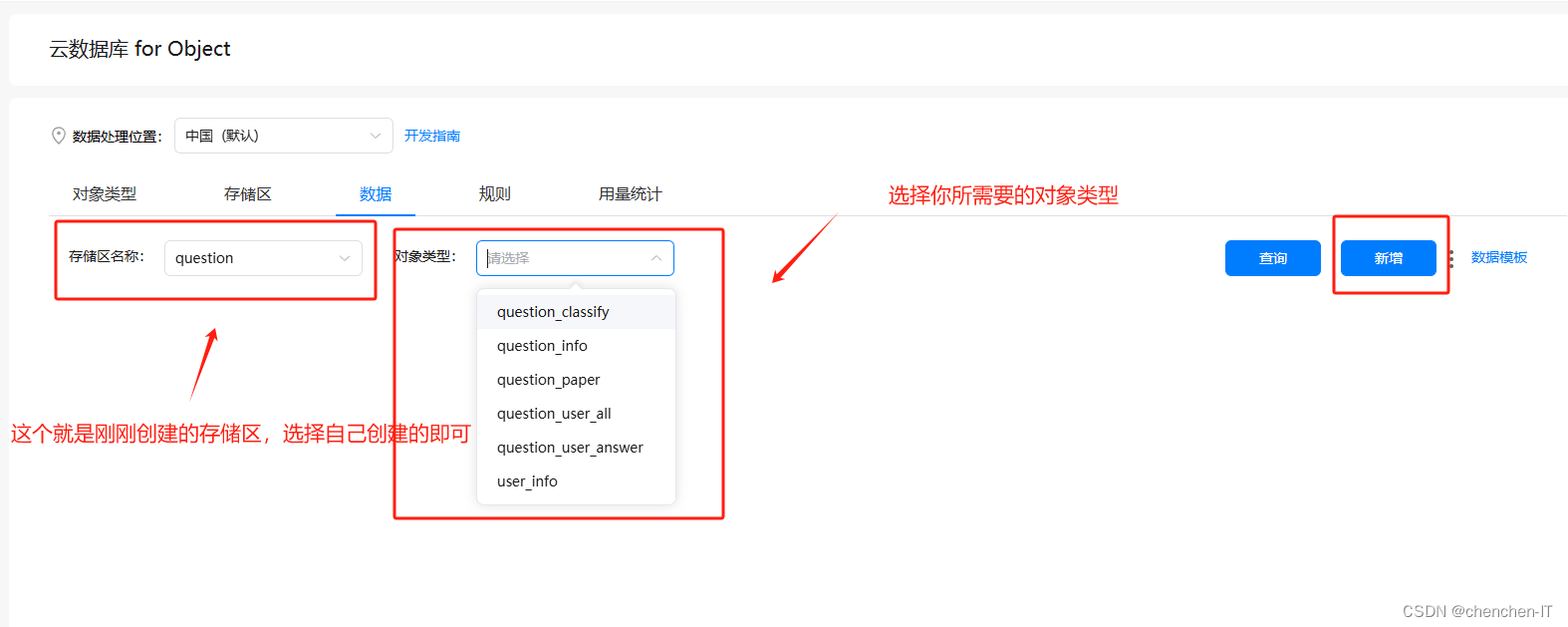
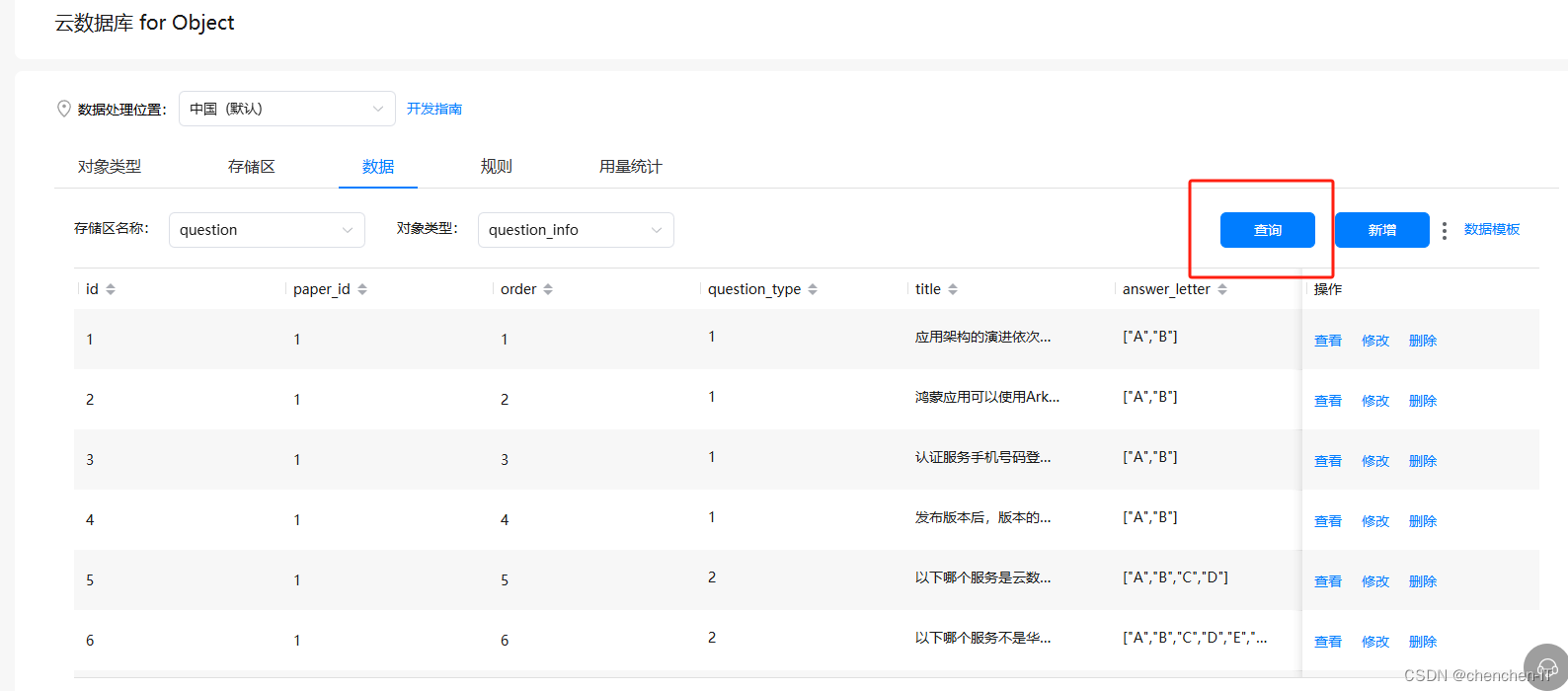
添加之后点击查询就可以看到我们添加的数据了
 5.下载对应的云端json到项目
5.下载对应的云端json到项目
点击项目设置
下载配置文件

给我们的项目配置我们云端的配置文件
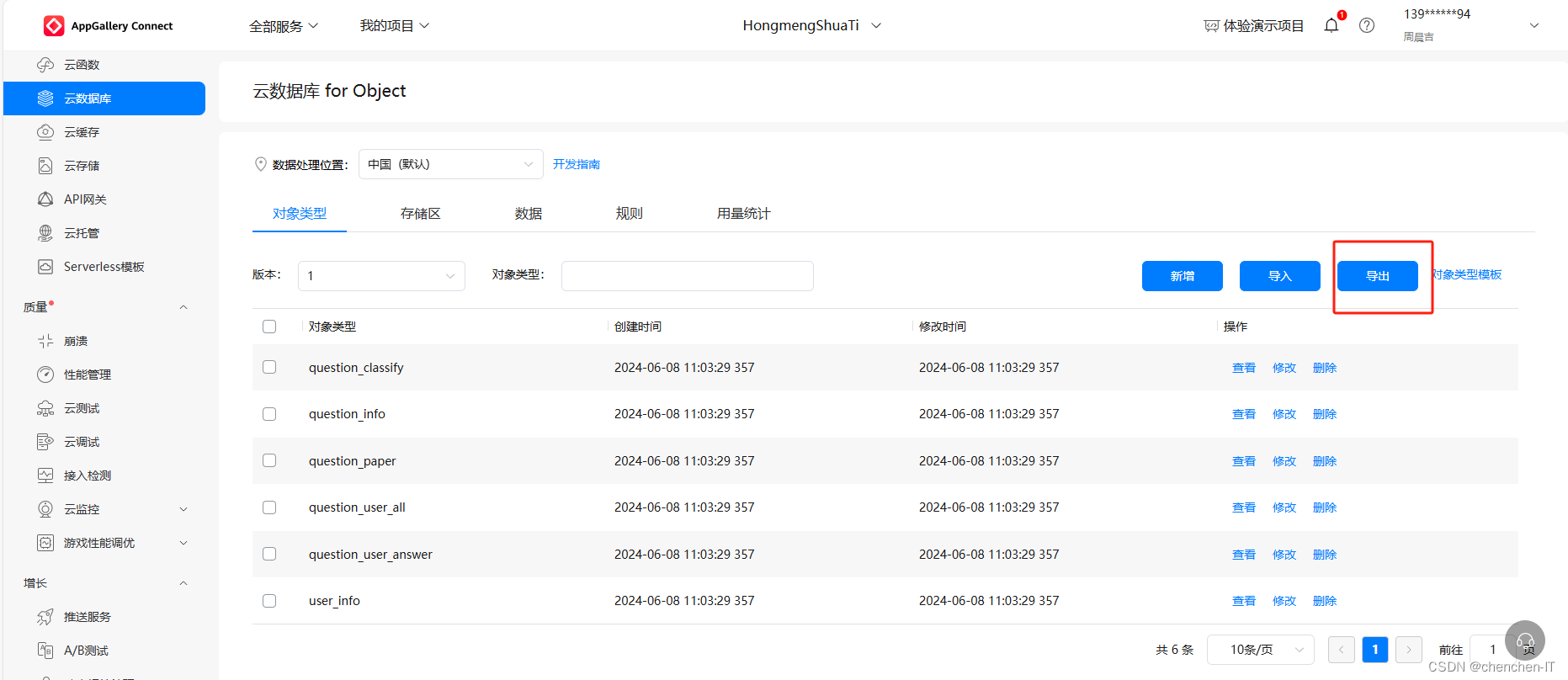
 6. 准备表的类型文件
6. 准备表的类型文件
有两种方法:
第一种:
 选择js格式进行导出
选择js格式进行导出
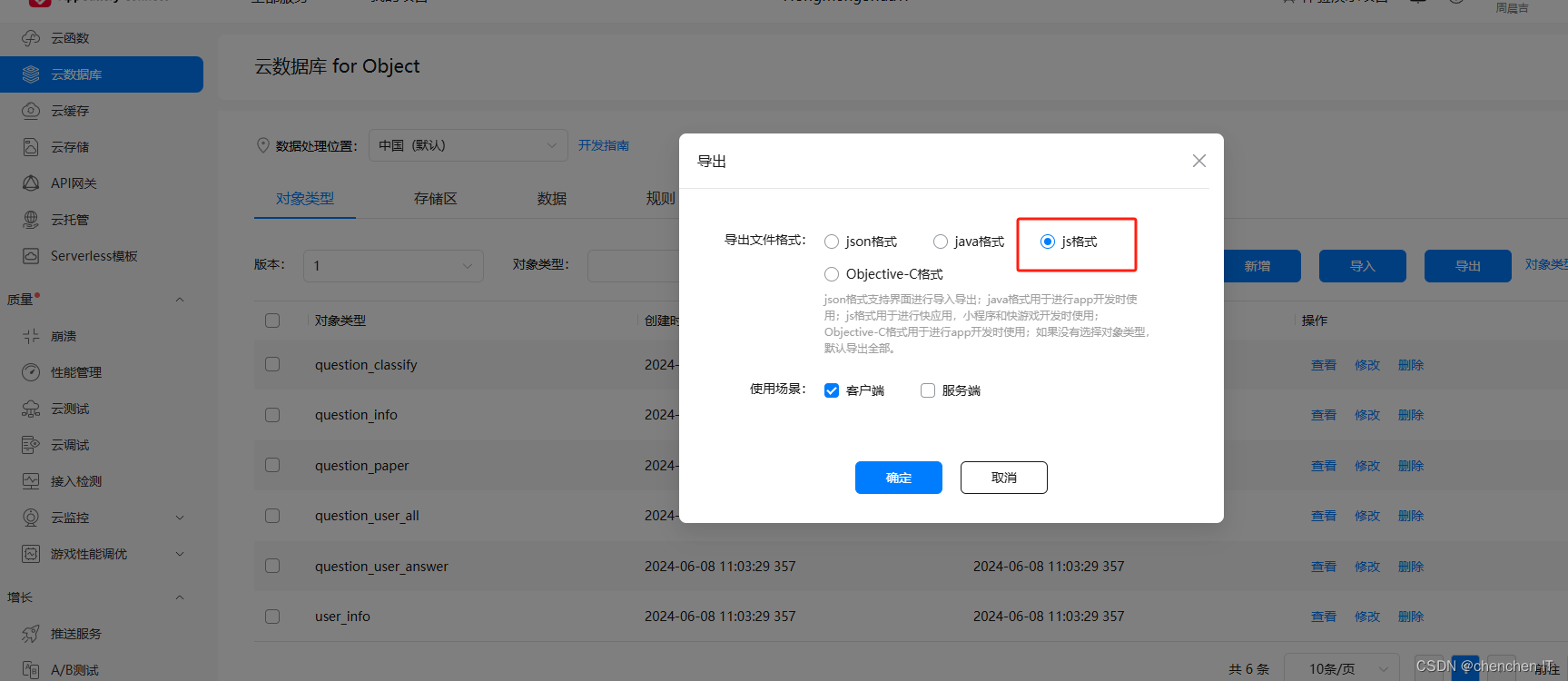
我们就获取到了对应的表类型文件
放在models文件夹中之后方便我们进行引用即可,(json文件形式)
第二种:直接在models 创建表结构
自己填入内容即可,比较费事,但是可以自己写在一起,之后引用一个ets文件即可
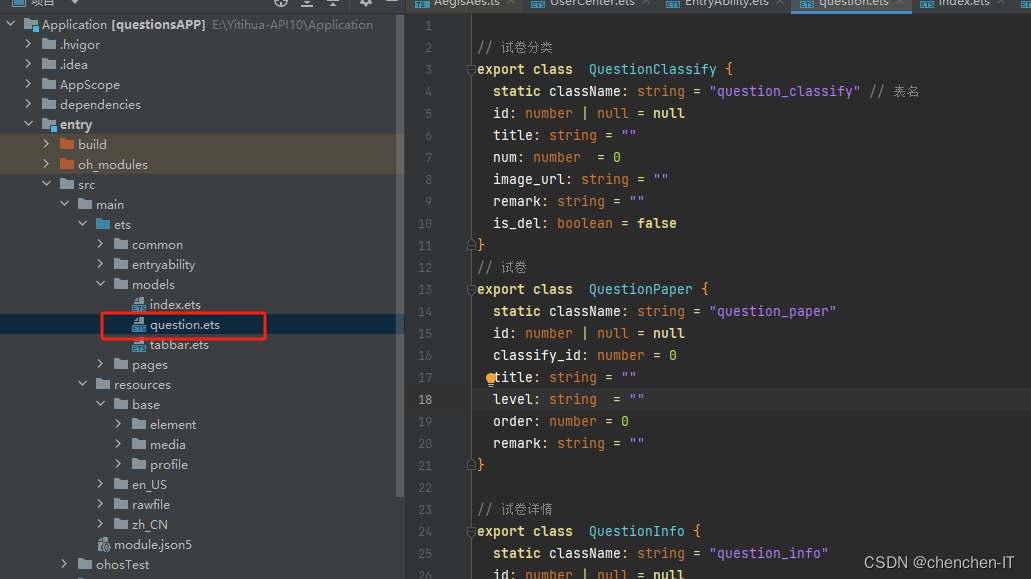
至此我们已经完成了连接数据库所有所需要的操作
这篇关于华为端云一体化开发 初始化云db表结构和表数据(实践2.0)(HarmonyOS学习第七课)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








