本文主要是介绍【CS.CN】深入解析HTTP中的Expect: 100-continue头:性能优化的利器还是鸡肋?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
- 0 序言
- 0.1 由来
- 0.2 使用场景
- 0.3 现在还需要吗?
- 1
Expect: 100-continue的机制 - 2 语法 && 通过重新设置空的
Expect头优化性能 - 3 实例分析:长连接中的
Expect问题解决 - 4 总结
0 序言
0.1 由来
Expect: 100-continue头部字段最早在HTTP/1.1规范中引入。其主要目的是在客户端发送大请求主体(如文件上传)之前,确保服务器能够处理该请求,从而避免不必要的数据传输。
可以将Expect: 100-continue机制比作一个礼貌的问询:
- 情景设定:
- 想象你要向朋友送一个大礼物(比如一个大箱子)。
- 你不确定朋友是否有地方存放这个大箱子。
- 正常流程:
- 你打电话(建立TCP连接),告诉朋友你有一个大箱子(发送请求头)。
- 朋友确认他们有地方放这个大箱子(服务器响应100 Continue)。
- 你再送过去(发送请求主体)。
- 使用
Expect: 100-continue:- 你先打电话(建立TCP连接),告诉朋友你有一个大箱子,但等朋友确认他们有地方放这个大箱子后你才送过去(发送
Expect: 100-continue头并等待100 Continue响应)。 - 如果朋友说没有地方(返回错误状态),你就不送了(节省了不必要的传输)。
- 你先打电话(建立TCP连接),告诉朋友你有一个大箱子,但等朋友确认他们有地方放这个大箱子后你才送过去(发送
0.2 使用场景
- 大数据上传:当客户端需要上传大文件或大数据时,使用
Expect: 100-continue可以确保服务器能够接受这些数据,从而避免在服务器不能处理请求的情况下浪费带宽。 - 带宽受限的环境:在带宽较低或受限的网络环境中,通过此机制可以减少不必要的数据传输,提高效率。
- 节省带宽:避免在服务器不能处理请求的情况下发送大量数据,节省网络带宽。
- 提高效率:在服务器无法处理请求时,客户端能尽早得知,避免等待无效的传输过程。
0.3 现在还需要吗?
虽然Expect: 100-continue在某些情况下依然有用,但现代网络环境和服务器架构的进步使其重要性有所降低:
- 快速网络:现代网络速度提高,使得发送请求头和等待100 Continue响应的时间成本变得相对较高。
- 高效服务器:现代服务器处理能力提升,通常可以快速判断并响应请求,无需客户端等待确认。
- 其他优化手段:现在有更多的优化手段和更好的网络协议(如HTTP/2, HTTP/3)可以提升传输效率。
是否需要使用Expect: 100-continue取决于具体的应用场景:
- 需要:在高带宽消耗的应用场景中,尤其是大数据上传或受限带宽环境中,依然可以使用。
- 不需要:在一般的Web请求或快速网络环境中,去掉
Expect: 100-continue头可以减少等待时间,优化性能。
1 Expect: 100-continue的机制
Expect 是一个请求消息头,包含一个期望条件,表示服务器只有在满足此期望条件的情况下才能妥善地处理请求。
规范中只规定了一个期望条件,即 Expect: 100-continue, 对此服务器可以做出如下回应:
100如果消息头中的期望条件可以得到满足,使得请求可以顺利进行的话,417(Expectation Failed) 如果服务器不能满足期望条件的话;也可以是其他任意表示客户端错误的状态码(4xx)。
例如,如果请求中 Content-Length 的值太大的话,可能会遭到服务器的拒绝。常见的浏览器不会发送 Expect 消息头,但是其他类型的客户端如 cURL 默认会这么做。
在持久连接中,
Expect头可以显著影响请求的性能。默认情况下,客户端可能会添加Expect: 100-continue头,这要求服务器在接受请求主体前响应100 Continue。虽然这种机制有助于避免无效数据的传输,但在某些环境下可能导致不必要的延迟。
客户端发送带有Expect: 100-continue头的请求,服务器在确认可以处理请求后响应100 Continue,然后客户端发送请求主体。如果服务器没有及时响应,客户端将在等待一段时间后继续发送请求主体。这种等待时间会增加请求的总耗时,尤其在长连接中更明显。
在HTTP长连接(持久连接)中,客户端与服务器之间会复用同一个TCP连接以发送多个请求/响应对话。这通常会显著降低延迟和资源消耗,但在某些情况下可能会遇到性能问题。
HTTP协议中的Expect头字段通常用于通知服务器客户端期望的特定行为。默认情况下,客户端可能会自动添加Expect: 100-continue头,这意味着在发送大数据请求主体(例如文件上传)之前,客户端希望服务器先确认请求是否会被接受。
这种机制可以有效避免不必要的数据传输,但在使用长连接时,客户端等待服务器响应100 Continue可能导致显著的延迟。如果服务器未及时响应,客户端将等待一个超时时间,然后再发送请求主体,这会增加总体请求耗时。
注意: Expect: 100-continue机制与连接的长短无关。无论是短连接还是长连接,当客户端发送一个包含Expect: 100-continue头的请求时,都会触发同样的机制:客户端在发送请求主体前等待服务器的100 Continue响应。所以在短连接中,Expect: 100-continue头的存在同样会导致客户端在发送请求主体前等待服务器的100 Continue响应。如果服务器的响应不及时或网络延迟较大,这段等待时间会增加整个请求的耗时。
2 语法 && 通过重新设置空的Expect头优化性能
目前规范中只规定了 “100-continue” 这一个期望条件: 表示通知接收方客户端要发送一个体积可能很大的消息体,期望收到状态码为100 (Continue) 的临时回复。
Expect: 100-continue
e.g.比如curl库默认设置, 或者发送大消息体时: 服务器开始检查请求消息头,可能会返回一个状态码为 100 (Continue) 的回复来告知客户端继续发送消息体,也可能会返回一个状态码为417 (Expectation Failed) 的回复来告知对方要求不能得到满足。
# 客户端发送带有 Expect 消息头的请求,等服务器回复后再发送消息体。PUT /somewhere/fun HTTP/1.1
Host: origin.example.com
Content-Type: video/h264
Content-Length: 1234567890987
Expect: 100-continue
为了避免这种延迟,可以显式设置空的Expect头。这样,客户端会直接发送请求主体,而不等待服务器响应100 Continue。这减少了等待时间,提高了请求的整体速度。
3 实例分析:长连接中的Expect问题解决
3.1 实际应用中的问题与解决过程
在实际应用中,我负责将一个使用cURL库访问上游接口的系统从原本的短连接改为长连接。我们的初衷是通过长连接减少频繁建立和关闭连接的开销,从而显著降低接口调用的耗时。然而,改为长连接后,监控视图却显示接口调用的平均耗时不降反增。

3.2 问题发现与初步分析
为了进一步了解问题,我们开始对接口调用过程进行抓包分析。在抓包数据中,我们发现每次发起HTTP请求时,第一跳的请求会出现几百毫秒的延迟。这种延迟在后续请求中并未消失,导致整体耗时增加。
3.2 抓包分析与根本原因
以下是抓包分析的关键步骤和示例:
- 抓包工具:使用Wireshark等抓包工具,捕获HTTP请求和响应数据包。
- 筛选HTTP请求:在Wireshark中筛选HTTP请求,定位包含
Expect: 100-continue头的请求。 - 分析时间戳:检查包含
Expect头的请求和后续发送请求主体的时间戳,确认延迟发生的具体位置。 - 确认问题:发现客户端在发送请求头后,等待服务器返回
100 Continue响应的过程中出现了明显延迟。
Frame 1: 102 bytes on wire (816 bits), 102 bytes captured (816 bits) on interface eth0, id 0Arrival Time: Jan 1, 2024 15:45:12.123456789 UTC[Time shift for this packet: 0.000000000 seconds]Epoch Time: 1672598712.123456789 seconds[Time delta from previous captured frame: 0.000000000 seconds][Time delta from previous displayed frame: 0.000000000 seconds][Time since reference or first frame: 0.000000000 seconds]Frame Number: 1Frame Length: 102 bytes (816 bits)Capture Length: 102 bytes (816 bits)[Frame is marked: False][Frame is ignored: False][Protocols in frame: eth:ethertype:ip:tcp:http]
Ethernet II, Src: Vmware_00:00:00 (00:50:56:c0:00:08), Dst: Vmware_00:00:01 (00:50:56:c0:00:01)
Internet Protocol Version 4, Src: 10.0.0.2, Dst: 10.0.0.3
Transmission Control Protocol, Src Port: 49152, Dst Port: 80, Seq: 1, Ack: 1, Len: 40
Hypertext Transfer ProtocolGET / HTTP/1.1\r\nHost: www.example.com\r\nUser-Agent: curl/7.68.0\r\nAccept: */*\r\nExpect: 100-continue\r\n\r\n通过深入分析抓包数据,我们注意到客户端在发送请求头后,等待了较长时间才继续发送请求主体。进一步检查HTTP头部字段,我们发现请求头中包含了Expect: 100-continue。这种配置要求服务器在收到请求头后,先返回一个100 Continue响应,然后客户端才发送请求主体。如果服务器响应不及时,客户端会等待一段时间,从而导致整体耗时增加。
3.3 解决方案与实施
为了解决这一问题,我们决定通过显式设置空的Expect头,绕过100-continue机制,让客户端在发送请求时直接发送请求主体。具体实现如下:
std::list<std::string> lstHeader;
xx_api::Prom* prom = xx_api::Prom::GetInstance();
lstHeader.push_back("Content-Type: application/xml;charset=utf-8");
lstHeader.push_back("MsgTp:" + msgTp);
lstHeader.push_back("OriIssrId:" + kPyeeAcctIssrId);
lstHeader.push_back("Expect:");
3.4 结果验证与性能提升
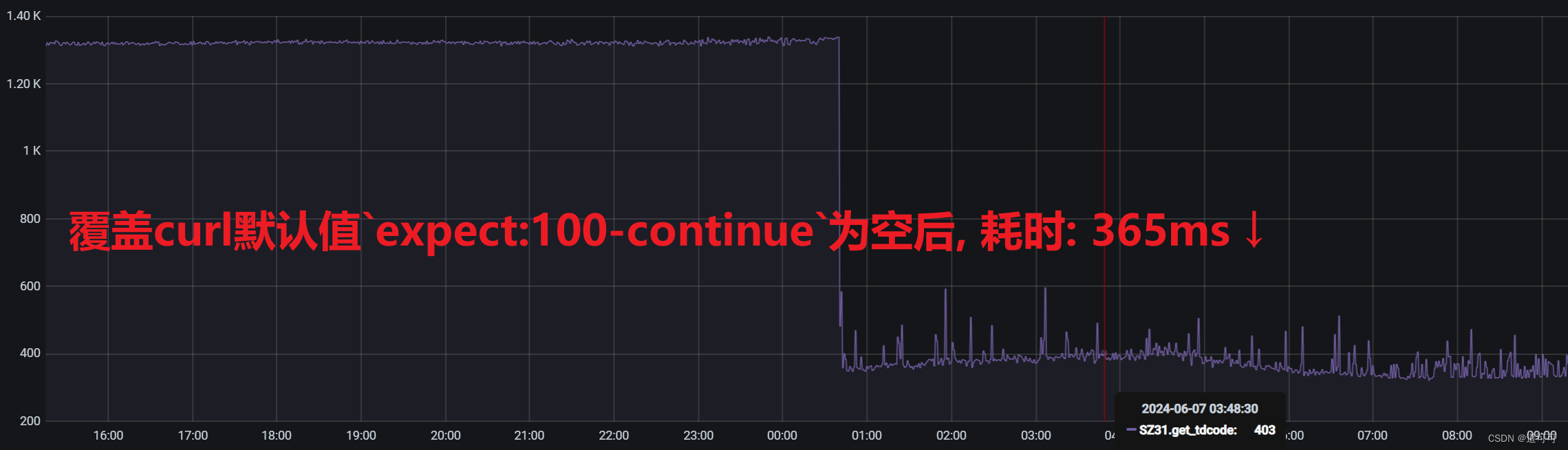
在实施这一改动后,我们再次进行了性能测试。监控视图显示,HTTP请求的平均耗时显著下降,之前的几百毫秒延迟不复存在。经过多次测试和实际运行,确认这种改动有效解决了因Expect: 100-continue头导致的延迟问题。
4 总结
无论是短连接还是长连接,通过去掉Expect: 100-continue头可以避免等待服务器的100 Continue响应,从而减少请求的整体耗时,提升性能。
1000.06.CS.CN.7.2.4-HTTP-连接管理-Expect头的使用与性能影响-Created: 2024-06-06.Thursday17:51
这篇关于【CS.CN】深入解析HTTP中的Expect: 100-continue头:性能优化的利器还是鸡肋?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




