本文主要是介绍【爬虫】使用Python爬取百度学术页面的标题、作者、摘要和关键词,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 安装所需库
- 编写爬虫
- 代码解释
- 运行脚本
- 结果
在本文中,我将介绍如何使用Python编写一个网络爬虫,从百度学术页面提取研究论文的标题、作者、摘要和关键词。我们将使用
requests和
BeautifulSoup库来实现这一目标。
安装所需库
首先,确保已安装所需的Python库:
pip install requests beautifulsoup4
编写爬虫
以下是一个示例脚本:
import requests
from bs4 import BeautifulSoup# 百度学术页面URL
url = "https://xueshu.baidu.com/usercenter/paper/show?paperid=7ea6e4650085a4bf2457468cc815cabe&site=xueshu_se"# 请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}# 发送请求
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'if response.status_code == 200:# 解析HTMLsoup = BeautifulSoup(response.text, 'html.parser')# 提取标题title_tag = soup.find('a', {'data-click': "{'act_block':'main','button_tp':'title'}"})title = title_tag.get_text(strip=True) if title_tag else "未找到标题"# 提取作者author_tag = soup.find('p', {'class': 'author_text'})author = author_tag.get_text(strip=True) if author_tag else "未找到作者"# 提取摘要abstract_tag = soup.find('p', {'class': 'abstract'})abstract = abstract_tag.get_text(strip=True) if abstract_tag else "未找到摘要"# 提取关键词keywords_tag = soup.find('div', {'class': 'kw_wr'})if keywords_tag:keywords = [keyword.get_text(strip=True) for keyword in keywords_tag.find_all('a')]keywords = ', '.join(keywords)else:keywords = "未找到关键词"# 打印提取结果print("标题:", title)print("作者:", author)print("摘要:", abstract)print("关键词:", keywords)
else:print("无法访问网页")代码解释
- 请求头设置:使用请求头模拟浏览器请求,避免被网站屏蔽。
- 解析网页内容:使用
BeautifulSoup解析HTML,提取所需信息。 - 处理未找到元素的情况:如果元素未找到,输出相应的提示信息。
运行脚本
将上述代码保存为一个Python文件,例如scraper.py,然后在命令行中运行:
python scraper.py
结果
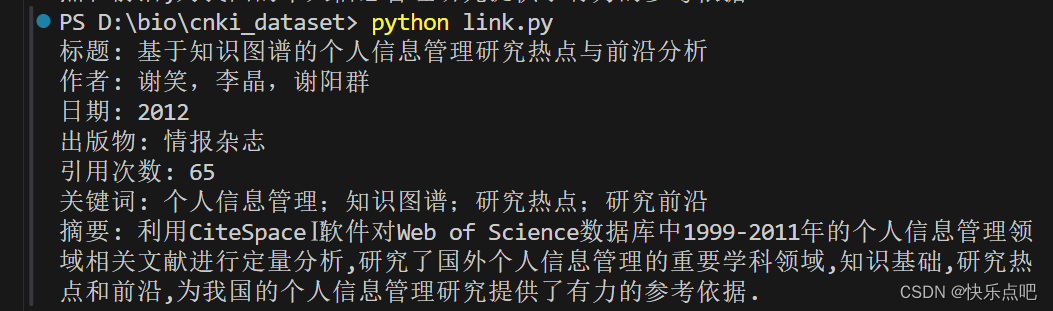
这篇关于【爬虫】使用Python爬取百度学术页面的标题、作者、摘要和关键词的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





