本文主要是介绍<PostgreSQL数据库内核分析>之第三章:存储管理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、存储管理器的体系结构
- 二、外存管理
- 1.表和元组的组织方式
- 2.磁盘管理器
- 3.内存管理
一、存储管理器的体系结构
存储管理器是DBS与物理存取设备的接口
- 存储管理器的体系结构如下
(1)本地内存是每个后台进程所专有,存储属于该进程的高速缓存Cache、事务管理信息、进程信息等
(2)内存上下文:用于统一管理内存的分配和回收
(3)PG中每个表都用一个表文件来存储,并以表的OID命名,若超出OS文件大小限制,PG会将其切分为多个文件来存储;
每个表除了表文件外,还拥有两个附属文件:
可见性映射表文件VM(作用:加快VACUUM的执行速度)
空闲空间映射表文件FSM作用:(管理表文件的空闲空间)。
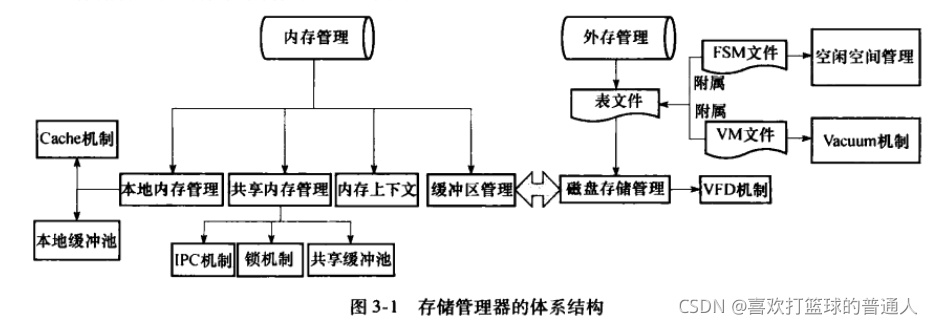
- 存储管理器使用了虚拟文件描述符机制VFD,使得后台进程可以打开“无限多个”文件。
- 缓冲池:进程间共享缓冲池
(1)为了防止多个进程并发访问共享内存中的数据时产生的冲突,PG提供了轻量级锁,用于支持对共享内存中同一数据的互斥访问 - 缓冲池:进程私有的本地缓冲池
(1)PG中的数据在内存中是以页面块的形式存在,每个表空间由多个BLCKSZ(一个可配置的常量)字节大小的文件块组成,每个文件块可以包含多个元组,但是PG不支持元组的跨块存储,每个元组最大为MaxHeadTupleSize,保证了每个文件块中存储的是多个完整的元组。
(2)表文件以文件块为单位读入内存中,每一个文件块在内存中形成一个页面块。
(3)PG在内存中开辟了缓冲区域(缓冲池):磁盘上的文件块读入内存后被存放在缓冲区中,缓冲池被划分为与文件块的尺寸相同的若干个固定大小的缓冲区,一个标准缓冲块的默认大小是8K。
一个PG进程(postmaster、postgres)从数据库读写一个元组的流程:
-
进程的本地内存有2种Cache:存储系统表元组、存储系统表的基本信息
-
PG的共享缓冲池与本地缓冲池:本地缓冲池用于缓冲临时表数据以及其他进程不可见的数据
-
若缓冲池中没有包含所需元组的缓冲块,则需通过存储介质管理器SMGR来从存储介质中读取,并写入到缓冲区中。
-
磁盘管理器负责管理所有存储在磁盘上的文件的操作
-
虚拟文件管理:虚拟文件描述符VFD机制。VFD通过合理使用有限个实际文件描述符来满足无限的VFD访问需求,VFD通过维持一个LRU池来管理FD

-
在PG中,为每个表增加了一个附属文件,即空闲空间映射表FSM,用于记录每个表文件中块的空闲空间大小,通过一定的查找机制和数据组织实现了文件块的快速选择
-
PG使用标记删除的方式来处理元组的删除,即:对元组打上删除标记,而非从物理上删除元组。
元组的物理删除是由VACUUM机制来完成的,由于VACUUM操作时会去遍历所有文件块,去查找被删除的元组效率低,所以也为表设计了可见性映射表VM,用以加快查找的速度。
二、外存管理
每个表文件在磁盘中都以一定的结构进行存储
- 外存管理体系结构

1.表和元组的组织方式
PG中同一个表中的元组是顺序依次插入到表文件中的。
- 元组之间不关联的表文件,称之为堆文件。
PG包括四种堆文件:普通堆ordinary cataloged heap、临时堆temporary heap、序列sequence relation(特殊的单行表)、TOAST表(toast table)。
(1)临时堆仅在会话过程中创建、在会话结束时自动删除;
(2)序列是一种元组值自动增长的特殊堆
(3)TOAST表其实也是一种普通堆,但是它被专门用于存储变长数据。 - 堆文件的物理结构如下,
(1)每个堆文件由多个文件块组成
(2)Linp是ItemIdData类型的数组,每一个ItemIdData结构用来指向文件块中的一个元组
(3)Freespace是空闲空间,新插入页面的元组都从这部分空间来分配
(4)Special space是特殊空间,用于存放与索引方法相关的特定数据
(5)元组信息:存放元组的实际数据和元组的头部信息(事务ID+命令ID等信息)

- 从堆中删除一个元组:采用标记删除的方法,为每个元组使用额外的数据位作为删除标记。
当删除元组时,只需设置相应的删除标记(在元组头部,记录了删除这个元组的事务ID和命令ID),即可设置相应的删除标记。
若上述两个ID有效,则表明该元组应该被删除。
2.磁盘管理器
磁盘管理器并非对磁盘上的文件直接进行操作,而是通过VFD机制进行文件操作。
- 因为一个进程打开的fd数量有限(受限于OS规定的最大值),所以设计了VFD机制
- VFD、真实文件描述符、文件之间的关系
(1)虚拟文件描述符是指:一个叫做VFD的数据结构,其中记录了操作系统为文件分配的真实fd;
(2)多个进程打开同一个文件,那么每个进程将获得一个真实fd,每个真实fd对应一个VFD;

LRU池
- 每一个PG后台进程都使用一个LRU(Last Recently Used,最近最少使用)池来管理所有已经打开的VFD,池中每一个VFD都对应物理上已经打开的文件;
- 每个进程都拥有其私有的LRU池和一系列VFD,进程需要打开文件时都是从自己私有的LRU池中申请VFD
(1)在LRU池中,使用替换最长时间未使用的VFD策略
(2)进程在VfdCache上保持了两个链表,一个是LRU池(双向链表,通过Vfd数据结构的IruMoreRecently属性和IruLessRecently属性链接),另一个是FreeList(空闲链表,记录了所有可被分配的VFD,通过Vfd数据结构中的nextFree属性来连接)。
(3)PG中将一个进程当前正打开的所有文件的VFD都连成一个环,即LRU池;
每个方框代表一个VFD(一个VfdCache数组元素),方框里的符号表示该VFD在数组中的下标。
在LRU池中,每一个VFD都通过指针链接两个VFD,通过指针IruMoreRecently链接最近最常用的VFD,通过指针IruLessRecently链接最近不长使用的VFD;
(4)LRU池的大小与操作系统对于进程打开文件数的限制保持一致,在postmaster进程的启动过程中会调用max_safe_fds函数来检测操作系统限制;
(5)插入:新的VFD在VFD[0]后插入;
删除:在LRU池中删除VFD;若LRU池已满,而又要打开新的fd,则将池中末尾的VFD删除(最少使用的VFD)

空闲空间映射表FSM
- 对于每个表文件(包括系统表在内),同时创建一个名为“关系表OID_fsm”的文件,用以记录该表的空闲空间大小,称之为空闲空间映射表文件FSM。
- FSM物理块与逻辑地址对照
(1)为了实现快速查找,FSM文件不太大且使用了树结构;
FSM中存储的不是实际的文件块空间的大小,而是仅用一个字节来记录,该字节的值用于描述对应文件块中空闲空间的范围:
所以对于任意一个表块,根据该字节的值就可以知道这个表块中空闲空间的范围;
对于任意一个表块,根据其空闲空间的大小可以计算出它对应的FSM字节的取值,eg,N字节空闲空间的表块,FSM中记录的值为(31+N)/32;

(2)FSM块之间使用了一个三层树结构:
第0层和第1层是辅助层:快速定位满足需要表块的FSM块
第2层FSM块:实际存放各表块的空闲空间值;
每一个FSM快内构成一个局部的最大堆二叉树,每个叶子节点表示一个表块的空闲空间值,按照从左至右的顺序,所有第2层FSM块中的叶子节点排列起来就一一对应了表文件中的每一个表块。
第1层FSM块中的叶子节点从左至右顺序对应第2层FSM块的跟节点,第0层与第一层关系类似。
(3)每个FSM块大小默认是8KB,出去头部等信息,每个叶子节点用一个字节记录,假设一个FSM块内可以保存4000个叶子节点,所以,一个FSM文件(有三个FSM块:0层FSM块、1层FSM块、2层FSM块)可以记录4000^3个叶子节点(表块);
这是远远大于2^32,单个表的最大块数(PG的块号长度为32bit,所以单个表最多只能有2^32个块)
(4)FSM文件中第一个文件块中二叉树(0层的0号FAM块)根节点存储的是所有表块空闲空间的最大值。

可见性映射表vm
- PG为了实现多版本的并发控制,当事务删除或者更新元组时,并非从物理上删除,而是通过将其标记为无效的方式进行标记删除,最终对这些无效的清理操作则需调用VACUUM(VACUUM查找包含无效元组的文件块)
- VACUUM有2种情况方式:快速清理Lazy VACUUM和完全清理Full VACUUM。
vm仅在Lazy VACUUM中使用到,Full VACUUM由于要执行跨块清理等操作,需要对整个表文件进行扫描,此时vm文件作用不大。 - vm文件也被划分为若干个文件块(vm块),vm块中除了必要的标记信息外,其他的每一位都对应一个表块,当表块中所有的元组对当前的事务都是可见的时,表块对应的位才设为1。
当对某个表块中的元组进行更新或者删除后,那么该表块在vm文件中的对应位置的标志位将被置0。 - vm文件仅仅是作为一个提示hint,加快vacuum的速度

大数据存储
- toast机制(the oversi-attribute storage technique,数据压缩和线外存储)和大对象机制(使用一个专门的系统表来存储大对象数据)
- toast机制
(1)这类数据类型必须有变长(varlena类型),eg:text类型,只有在准备向支持TOAST的属性中存储超过BLOCKSZ/4字节(2KB),TOAST机制才会被触发。
TOAST机制会试图对将要存储的数据进行压缩或线外存储数据(即:把数据存储在其他的表中),直到数据比BLOCKSZ/4字节短,或者无法得到更好的结果的时候才停止
(2)如果一个表中的属性是可以TOAST的,那么该表的将有一个关联的TOAST表。
(3)TOAST机制优点:可以有效地节省查询时所占的内存空间,TOAST数据只是在向用户显示结果时才被取出来,在查询过程中并不需要检查TOAST数据的具体取值
(4)TOAST技术保障了PG中的元组大小足以存放在一个文件块中,so,TOAST技术必须被设置为一种系统自动处理的机制。
TOAST机制主要集中于变长的数据类型。 - 大对象
(1)PG的大对象存储机制可以支持三种数据类型的存储:
二进制大对象BLOB:eg:图片、视频
字符大对象CLOB:存储大的单字节字符集数据,eg文档
双字节字符大对象DBCLOOB:存储大的双字节字符集数据,eg变长双字节字符图形字符串
(2)一个大对象会被分成若干个元组存放在系统表pg_largeobject中,每一个元组也称为一个页面。
一个元组大小为2KB,设置成2KB的原因是:可以触发TOAST的压缩机制。
TOAST与对象的区别
- TOAST是可变长数据类型的一种大数据存储机制,属于自动触发机制;
大对象属于用于手动调用机制 - TOAST中的数据不能丢失,一旦丢失则报错;大对象中运行数据丢失,若丢失,则用0替代;
- 文件不适合使用TOAST技术,原因:二进制读-》将二进制当做字符串存储到变长数据类型的属性中-》转变成文件;大对象操作是将文件作为一个对象存储到大对象表中,读取时直接读取成一个文件。
- TOAST和大对象操作保存大数据时,都是采用了将数据切片成了片段存储到表中的方式。
3.内存管理
尽可能让使用的文件停留在内存中,这样就能有效地减少磁盘I/O代价。
- PG内存管理

- 一个内存上下文实际上就相当于一个进程环境
PG每个子进程都拥有多个私有的内存上下文,每个子进程的内存上下文组成一个树形结构。

高速缓存 - 当数据库访问表时,需要表的模式信息,比如表的列属性、OID、统计信息等。
PG将表的模式信息存放在系统表中,因此要访问表,就需要首先在系统表中取得表的模式信息。
PG设立了高速缓存Cache来提高对系统表和普通表模式的访问效率。
Cache中包括一个系统表元组SysCache和一个表模式信息RelCache:
SysCache主要用于缓存系统表元组;
RelCache存放的不是元组,而是RelationData数据结构; - 每一个PG进程都维护着自己的SysCache和RelCache。
Cache同步
- PG中,每一个进程都有自己的Cache。同一个进程表在不同的进程中都有对应的Cache来缓存它的元组。桶一个系统表的元组可能被多个进程的Cache所缓存,当其中某个Cache中的一个元组被删除或更新,需要通知其他进程对其Cache进行同步。
PG中会记录下已被删除的无效元组,并通过共享消息队列的方式在进程之间传递消息,收到无效消息的进程同步地把无效元组(RelationData结构,因为RelCache缓存的是一个RelationData数据结构)才能够自己的Cache中删除。 - 当一个元组被删除或者更新时,在同一个SQL命令的后续执行步骤中,我们依然认为该元组是有效的,直到下一个命令开始或者事务提交时改动才生效。
在命令的边界,旧元组变为失效,同时新元组变为有效。so,当执行heap_delete或者heap_update时,不能简单地刷新cache,正确的做法是:保持一个无效链表用于记录元组的delete/update操作。
事务完成后,将无效链表中的信息广播该事务过程中产生的无效信息,其他进程通过消息队列读取无效信息对各自的Cache进行刷新。
当子事务提交时,只需要将该事务产生的无效消息提交到父事务,最后由最上层的事务广播无效消息。
缓冲池管理
这篇关于<PostgreSQL数据库内核分析>之第三章:存储管理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








