本文主要是介绍flask_sqlalchemy时间缓存导致datetime.now()时间不变问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题是这样的,项目在本地没什么问题,但是部署到服务器过一阵子发现,这个时间会在某一刻定死不变。
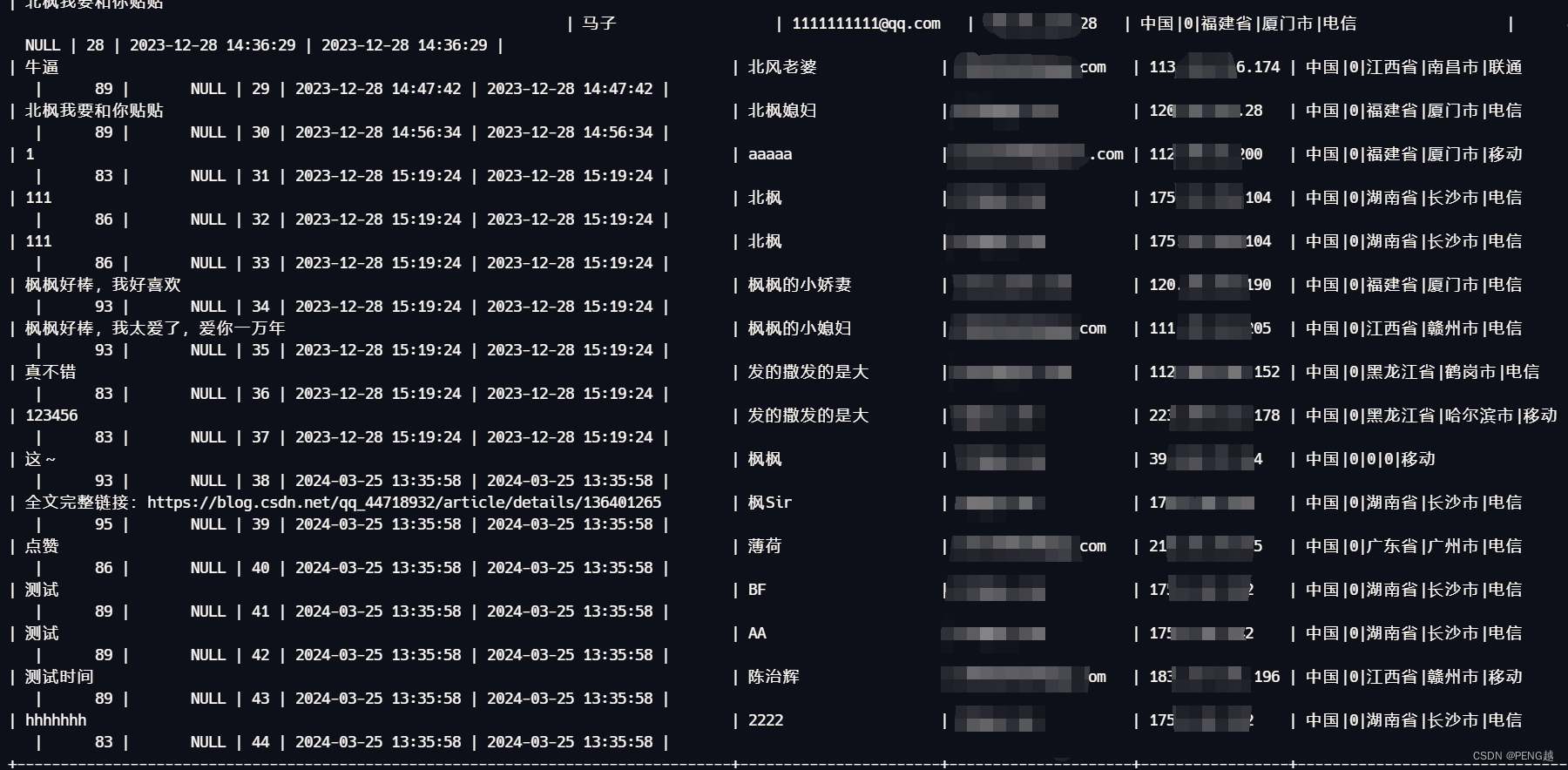
重启uwsgi后,发现第一条数据更新到了目前最新时间,过了一会儿再次发送也变了时间,但是再过几分钟再发就会变成和上次一样的时间。
我的基类模型是这样写的
class BaseModel(db.Model):""" 基类模型 """__abstract__ = Trueid = db.Column(db.Integer, primary_key=True, comment='id主键')add_time = db.Column(db.DateTime, default=datetime.now(), comment='创建时间')upd_time = db.Column(db.DateTime, default=datetime.now(), onupdate=datetime.now(), comment='更新时间')
从发送到保存都检查了一遍,没有发现什么问题,且检查了debian的时区和date是没问题的,因为python的datetime就是基于系统时间而言去生成的。
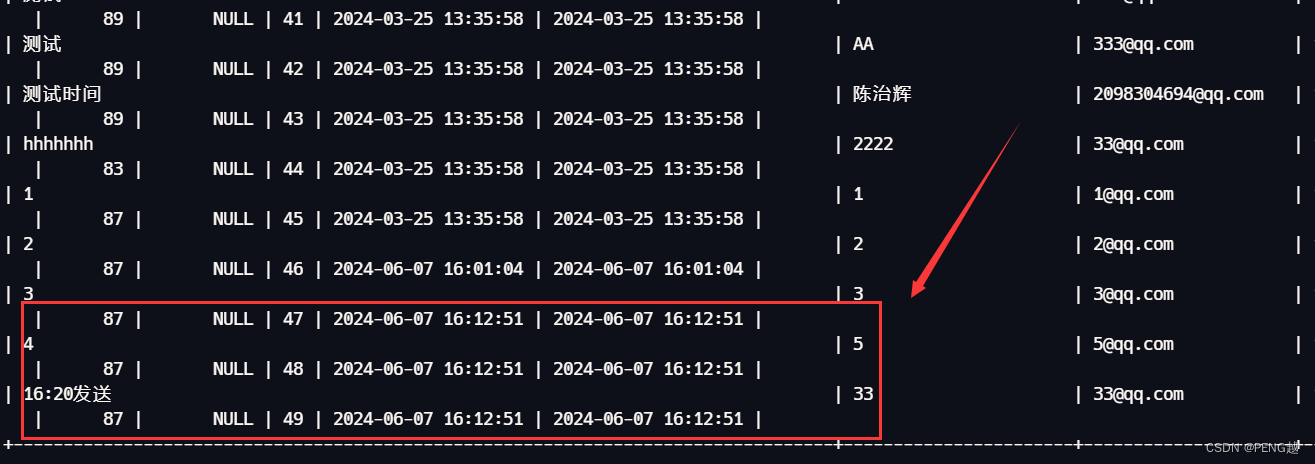
后搜了相关资料发现也有人遇到这个坑,于是记录下来。关键原因在于sqlalchemy的缓存,在于传入 default和onupdate的默认值是datetime.now(),该函数在模型调用时,就会生成时间,这块的生成会产生缓存,导致时间一直停留,目前推断是这样,具体的原因没有排查到源码层。没追根溯源到底是哪部分造成的缓存。但是经过实际测试在第一次启动uwsgi进行启动时发布是最新的时间数据,然后过了5分钟再次发送也是新的数据。但是再过10分钟再发送就和5分钟前发送的一样了。这块可以看图2
解决方案是需要将时间函数改成函数引用的方式,将now的函数地址传递。这也每次sqlalchemy生成执行sql的时候,将会直接执行函数引用,将 datetime.now当作参数进行传递,并执行。
最终将 datetime.now()改成datetime.now搞定
class BaseModel(db.Model):""" 基类模型 """__abstract__ = Trueid = db.Column(db.Integer, primary_key=True, comment='id主键')add_time = db.Column(db.DateTime, default=datetime.now, comment='创建时间')upd_time = db.Column(db.DateTime, default=datetime.now, onupdate=datetime.now, comment='更新时间')
这篇关于flask_sqlalchemy时间缓存导致datetime.now()时间不变问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








