本文主要是介绍阿里 Qwen2 模型开源,教你如何将 Qwen2 扩展到百万级上下文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本次开源的 Qwen2 模型包括 5 个尺寸,分别是 0.5B、1.5B、7B、72B、57B,其中 57B 的属于 MoE 模型(激活参数 14B),其余为 Dense 模型,本篇文章会快速介绍下各个尺寸模型的情况,然后重点介绍下如何利用 Qwen-Agent 将 Qwen2 模型的 8k 上下文扩展到 1M。
本文首发自博客 阿里 Qwen2 模型开源,教你如何将 Qwen2 扩展到百万级上下文
我的新书《LangChain编程从入门到实践》 已经开售!推荐正在学习AI应用开发的朋友购买阅读,此书围绕LangChain梳理了AI应用开发的范式转变,除了LangChain,还涉及其他诸如 LIamaIndex、AutoGen、AutoGPT、Semantic Kernel等热门开发框架。

Qwen2 和 Qwen1.5 的模型结构基本一致,主要是模型预训练数据有所增加(大约在 7T 以上),Qwen2-0.5B、Qwen2-1.5B 模型支持最大上下文长度为 32K;Qwen2-57B-A14B MoE 模型支持最大上下文为 64K;Qwen2-7B、Qwen2-72B 模型支持最大上下文为 128K,代码和数学能力显著提升。
| 模型 | Qwen2-0.5B | Qwen2-1.5B | Qwen2-7B | Qwen2-57B-A14B | Qwen2-72B |
|---|---|---|---|---|---|
| 参数量 | 0.49B | 1.54B | 7.07B | 57.41B | 72.71B |
| 非 Embedding 参数量 | 0.35B | 1.31B | 5.98B | 56.32B | 70.21B |
| GQA | True | True | True | True | True |
| Tie Embedding | True | True | False | False | False |
| 上下文长度 | 32K | 32K | 128K | 64K | 128K |
在 Qwen1.5 系列中,只有 32B 和 110B 的模型使用了 GQA,Qwen2 所有尺寸的模型都使用了 GQA,GQA 显著加速推理,降低显存占用。
模型效果
Qwen2 系列模型效果不光整体超过 Qwen1.5 系列,相对于其他同级别参数开源模型也很亮眼,下面是指令微调模型 Qwen2-72B-Instruct 和 Qwen2-7B-Instruct 和常见开源 SOTA 模型比较。
Qwen2-72B-Instruct 在多项指标超过 Llama-3-70B-Instruct,特别是中文领域,大幅领先。

代码和数学方面都超过了 Llama-3-70B-Instruct

Qwen2-7B-Instruct 和 智谱最近开源的 GLM-4-9B-Chat水平相当。

最后说下开源 License,除了 Qwen2-72B 使用 Qianwen License(有使用范围限制)其余模型 4 个尺寸模型均采用 Apache 2.0 的许可。
更多详细内容,请前往官网博客查看 https://qwenlm.github.io/zh/blog/qwen2/
借助 Qwen-Agent 实现长文本理解
这个也是阿里开源的,特别是在本地使用 Qwen2-0.5B、Qwen2-1.5B 这类上下文长度有限的模型时,通过 Qwen-Agent 框架,能够把处理的上下文扩展到 1M,整体采用的是代理式 RAG(Agentic RAG)思路,具体的做法分为三步。
第一步查询转换

将文本分成每块不超过 512 字短块,保留最相关在 8k 上下文,采用查询转换的方法:
- 步骤 1:引导模型分离用户查询中的指令信息与非指令信息。例如,将用户查询转为{“信息”: [“自行车是什么时候发明的”], “指令”: [“回答时用 2000 字”, “尽量详尽”, “用英文回复”]}。
- 步骤 2:从信息部分提取多语言关键词。例如,"自行车是什么时候发明的"转为{“关键词英文": [“bicycles”, “invented”, “when”], "关键词中文”: [“自行车”, “发明”, “时间”]}。
- 步骤 3:利用 BM25 基于关键词的检索,找出最相关的块。
这也是比较成熟的方案,详细可以看我半年前介绍的完整工程化实现使用这个工具后,我将 RAG 的准确性和召回率都提高了两倍!
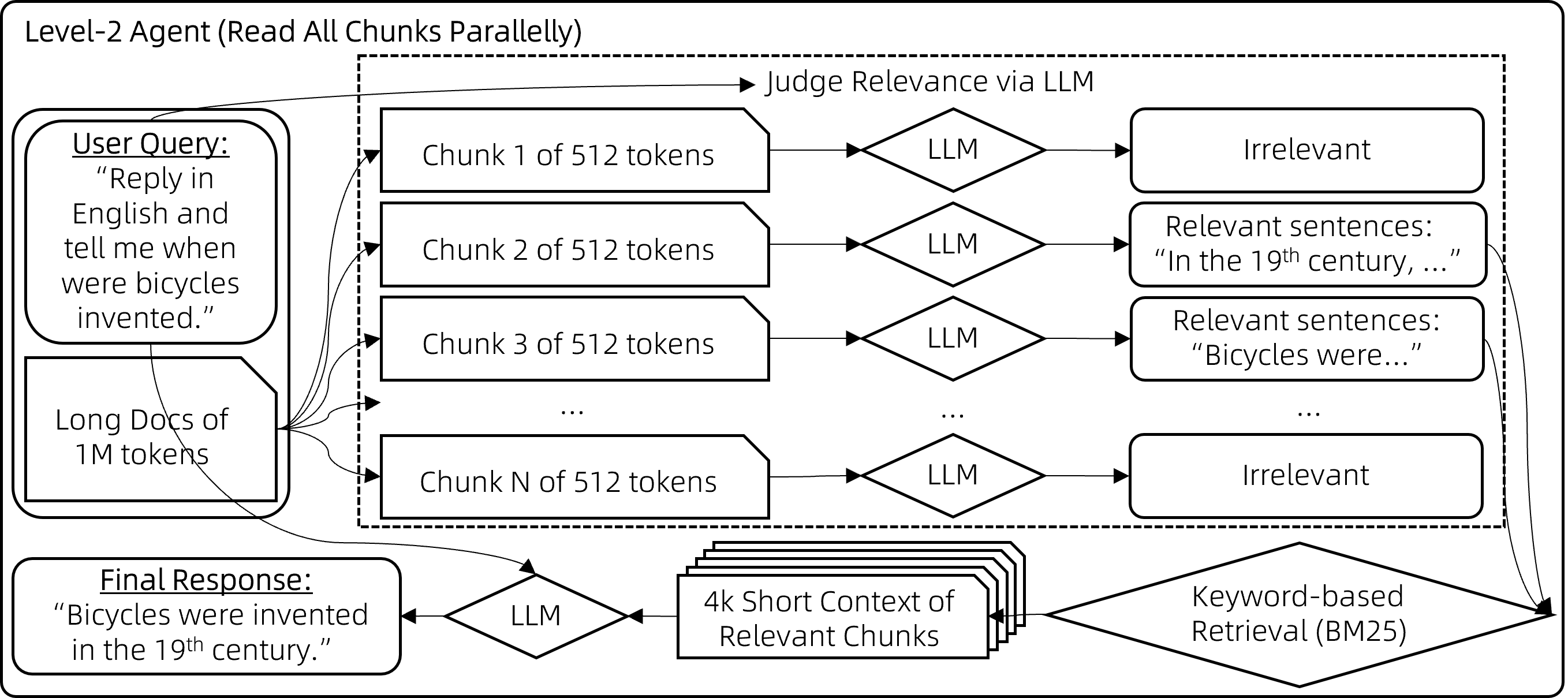
第二步 查询重写
在相关块与用户查询关键词重叠程度不足时,可能导致遗漏相关内容未被检索到,采用二次查询的方式:
步骤 1:对于每个 512 字块,让模型先评估其与用户查询的相关性。若认为不相关,则输出"无";若相关,则输出相关句子。
步骤 2:筛选出相关句子,将其用作搜索查询词,通过 BM25 检索出最相关的块(检索结果长度控制在 8k 上下文限制内)。
步骤 3:基于检索到的上下文生成最终答案。
第三步 自问提示(Self*-*Ask)
当遇到问题:“与第五交响曲创作于同一世纪的交通工具是什么?”模型需先回答子问题:“第五交响曲创作于哪个世纪?”即 19 世纪,接着,才能识别到包含信息“自行车于 19 世纪发明”与原问题相关。
通过让 LLM 自问自答生成多跳问题与答案,然后再生成最终的答案。
向 LLM1 提出一个问题?
while (LLM1 无法根据其记忆回答问题) {
LLM1 提出一个新的子问题待解答。
LLM1 向 LLM2 提问这个子问题。
将 LLM2 的回答添加到 LLM1 的记忆中。
}
LLM1 提供原始问题的最终答案。
通过这种方式就可以让较弱上下文长度的开源模型具备长上下文能力,对于构建完全本地化的 RAG 应用十分有益,下节我将结合 Ollama 在本地部署好 Qwen2-7B,构建高效的笔记搜索软件。
这篇关于阿里 Qwen2 模型开源,教你如何将 Qwen2 扩展到百万级上下文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









