本文主要是介绍【实践】nodeJS写个简单的爬虫程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
经常说SEO却从来没有写过爬虫,今天很有幸看到了关于nodeJS的爬虫程序的实现,模仿着写了个demo,权当砖头抛给大家了。
程序架构
因为是基于nodeJS,我们所需准备的架构很简单,用express4.x生成一个项目,然后再安装request和cheerio模块就可以。项目的package.json是这样的:
{"name": "spider","version": "0.0.0","private": true,"scripts": {"start": "node ./bin/www"},"dependencies": {"body-parser": "~1.13.2","cookie-parser": "~1.3.5","debug": "~2.2.0","express": "~4.13.1","jade": "~1.11.0","morgan": "~1.6.1","serve-favicon": "~2.3.0"},"devDependencies": {"cheerio": "^0.19.0","request": "^2.67.0"}
}当然你也可以直接 copy这个package.json到你自己的项目里,然后 npm install 就可以了。
cheerior模块介绍
用最简单的一句话概括 —— ”cheerior是运行在node服务端的jQuery“,也就是说 cheerior可以像jQuery一样提供简单的API去操纵DOM树。
它的API和jQuery操纵DOM的API基本一致,如果你想更深入地学习cheerior,不妨去看看它在npm的官网的标准API文档:https://www.npmjs.com/package/cheerio 。不过是英文版的哦,如果觉得看不太懂,这里还有个中文精简版的:https://cnodejs.org/topic/5203a71844e76d216a727d2e
抓取网站的源码
安装完所有的node_modules,我们就可以开始我们的抓取之旅了。当然在抓取之前我必须声明:不是每个网站的所有信息都可以爬,我们必须遵循robots协议,否则可能会涉及到法律问题。
举个例子,比如京东的robots文件:
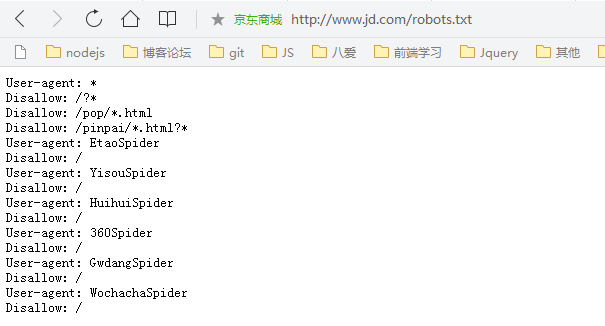
Disallow的东西你是不能爬的,如果你去篡改这个文件那京东就可以告你侵权了。
下面再举个实际的例子,这是我抓取我们八爱网首页的一些信息,代码很简单:
app.js (为了方便我改了原本的app.js)
var express=require('express');
var request=require('request');
var cheerio=require('cheerio');
var app=express();app.get('/',function(req,res){res.charset='utf-8';request('http://www.baai.com/',function(err,response,body){if(!err && response.statusCode==200){$=cheerio.load(body); //当前$相当于整个body的选择器var proInfos=$('.pro-info>h4');var imgs=$('.pro-img>img');var imgsTemp=[],proInfosTemp=[];for(var i=0,len=imgs.length;i<len;i++){imgsTemp.push(imgs.eq(i).attr('data-original'));proInfosTemp.push(proInfos.eq(i).html());}res.json({'productImage':imgsTemp,'proInfosName':proInfosTemp});}});
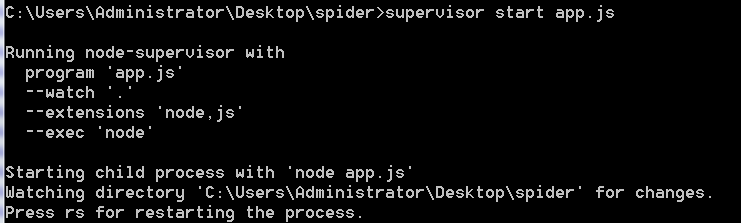
});app.listen(3000);接下来用 supervisor 启动这个node服务,对supervisor有疑问的同学欢迎出门左转翻一翻我前一篇【实践】express搭建nodeJS中间层(三),那里有比较详细的介绍。
好了,成功启动之后控制台可以看到这样的信息:
接下来我们打开浏览器,输入 127.0.0.1:3000 ,就启动这个爬虫程序了,抓取到的数据是这样的:
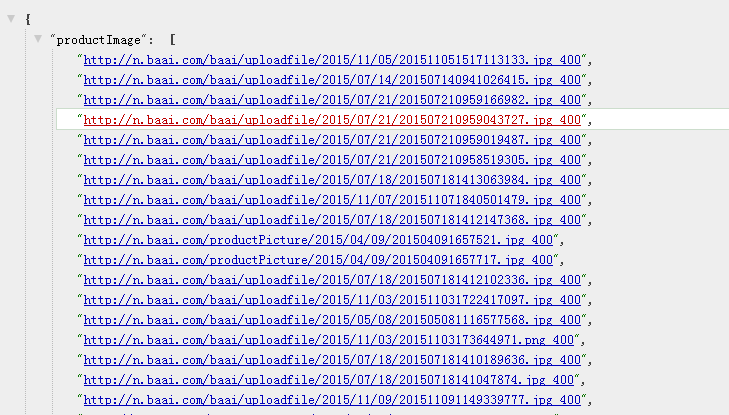
后话
今天就先写个简单的demo吧,感兴趣的同学可以继续研究 如何抓取 ajax 返回的内容。
这篇关于【实践】nodeJS写个简单的爬虫程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


