本文主要是介绍【乐吾乐2D可视化组态编辑器】Web组态、SCADA、数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.简介
乐吾乐 Le5le 2D 可视化组态软件,是乐吾乐公司完全自主研发、核心引擎开源的组态可视化平台。具有实时监控、多样、变化、动态交互、高效、可扩展、支持自动算法、跨平台等特点,能最大程度减少研发和运维的成本,并致力于普通业务人员 0 代码实现Web组态、SCADA等解决方案。拥有丰富的行业图形库和可视化案例。目前已在电力能源、水利水务、物联网、工业互联网、智慧工厂、智慧城市、智慧交通、智慧医疗、教育科研、航空航天、国防军工领域等取得广泛应用。
演示视频:
External Player - 哔哩哔哩嵌入式外链播放器
在线体验:乐吾乐2D可视化
2.特点
丰富的组态能力
- 拖拽编辑,简单易用
- 实时数据、双向通信
- 条件告警、逐帧动画
- 事件消息、组态联动
- 组合状态、视频监控
- 弹框、报表、格式刷
0代码数据通信
- 支持 mqtt 动态数据监听
- 支持 websocket 动态数据监听
- 支持 http 自主请求动态更新数据
管理与应用
- 导入导出组态图
- 导出 HTML、Vue、React 等离线部署包
- 提供离线部署方式,支持云端部署
- 支持集成到第三方平台
多端适配能力
- 支持Chrome、Firefox、Edge、Safari等主流浏览器
- 支持移动端webview方式访问
- 支持手机、平板、PC、大屏等多端展示

扫一扫,查看更多移动端解决方案
强大的扩展能力
- 图形库扩展:自定义图形库扩展,格式支持js、svg、jpg、iconfront
- 数据显示扩展:条件显示、数据格式显示、自定义函数扩展等
- 交互事件扩展:系统消息、自定义消息、生命周期hook、系统接口函数等
- 智能算法扩展:支持自定义拖拽智能算法,自定义连线算法等
- 动画扩展:节点逐帧定义动画、自定义算法动画
- 排版扩展:支持自定义排版布局算法
追求卓越性能
- 稳定,系统交互中断不影响系统运行
- 可支持10000-20000节点
- 支持绑定1000-2000数据点。1000数据点30ms完成刷新
- 支持 1000+动画播放
丰富的组件库资源
- 电力系统,能源系统,物联网,智慧水务,智能制造,数字大屏,图表控件,视频流监控一共4000多个组件
- 支持自定义扩展
图形库清单:文档中心 - 乐吾乐Le5le
广泛的应用场景支持
- 电力能源、水利水务、变电站、光伏系统、火电厂、化工厂、废气治理、炼钢厂、风电、矿山、煤矿系统等
- 物联网、工业互联网、电信机房中心、数据中心、采暖系统、制冷系统、远程监控系统等
- 智慧工厂、智慧楼宇、智慧园区、智慧交通、智慧城市、智慧港口、智慧停车、智慧医疗、智慧农业等
- 大屏展示、看板展示、数据报表、安防监控、IT 运维等
- 架构图、拓扑图、UML图、脑图等
国产开源、自主可控
- 乐吾乐公司自主潜心研发三年,掌握核心技术和知识产权,能够做到完全自主可控,且产品保持持续迭代优化
技术架构
系统采用B/S结构在云端上部署,由前后端分离 + 接口服务 + 数据库组成,遵循Restful Api接口设计标准及规范进行接口开发,或者采用采购方所提供的接口服务。
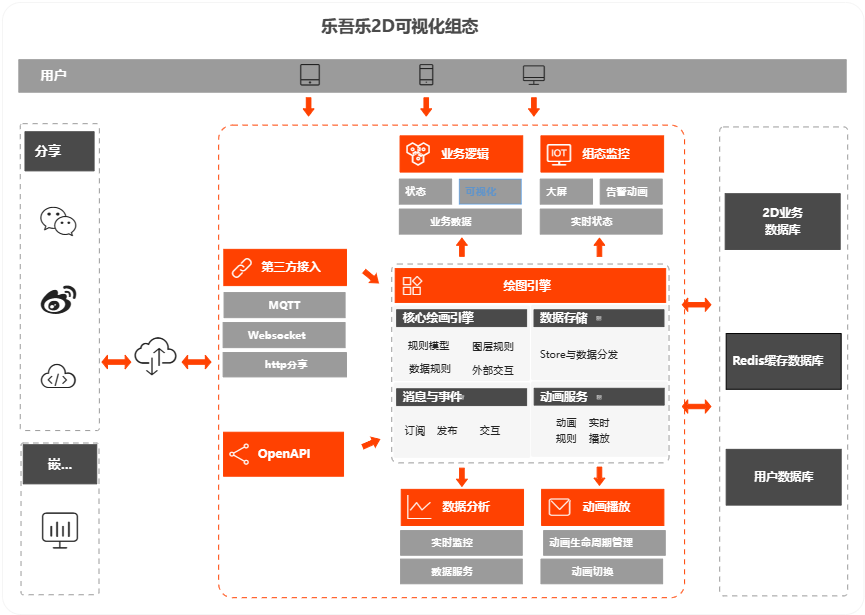
技术线路
1.前端框架采用主流的VUE
2.语言规范采用TypeScript
3.绘画引擎采用meta2d.js
4.底层绘画技术为Canvas
5.后端接口设计遵循Restful Api接口设计标准及规范
3.行业案例
1.智能预制泵站
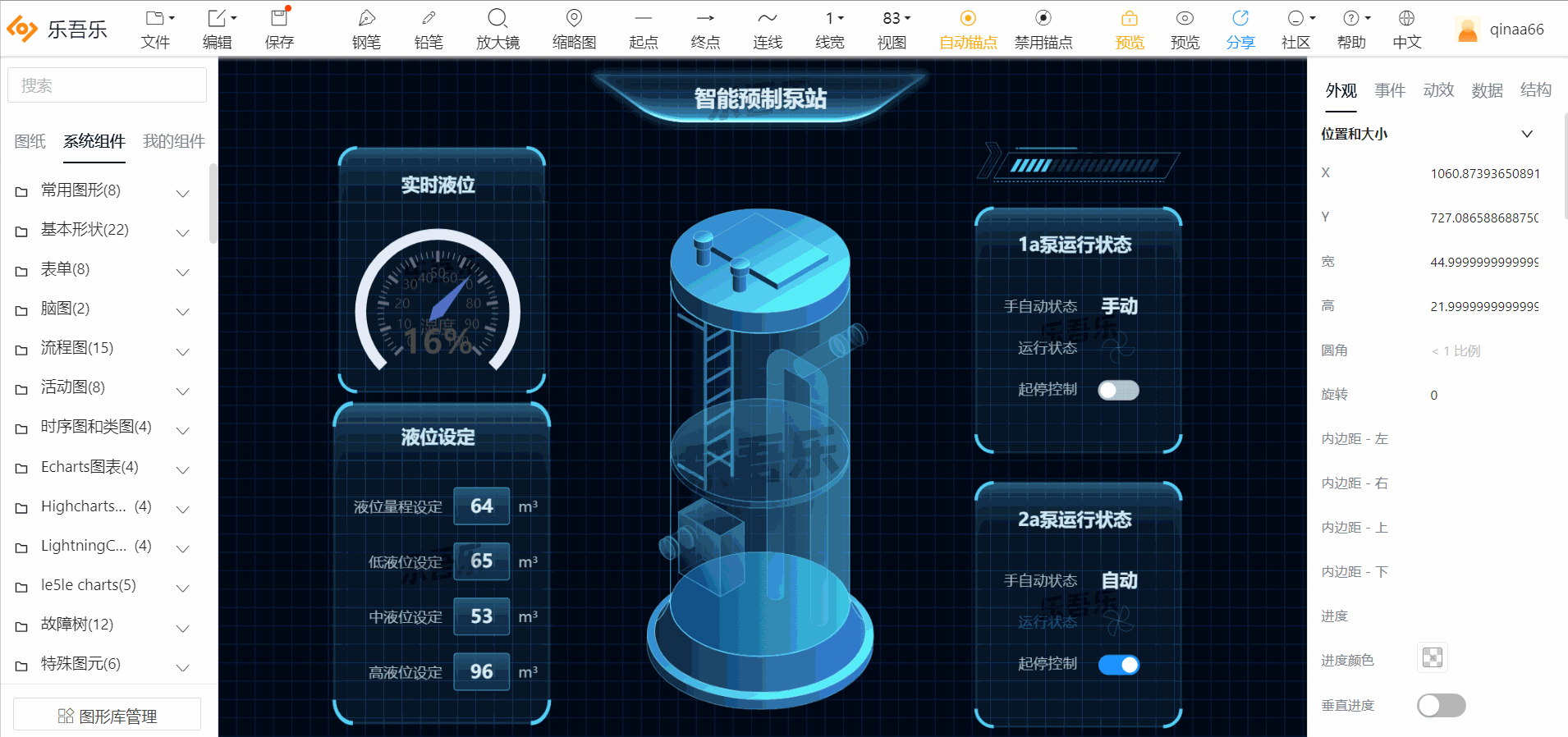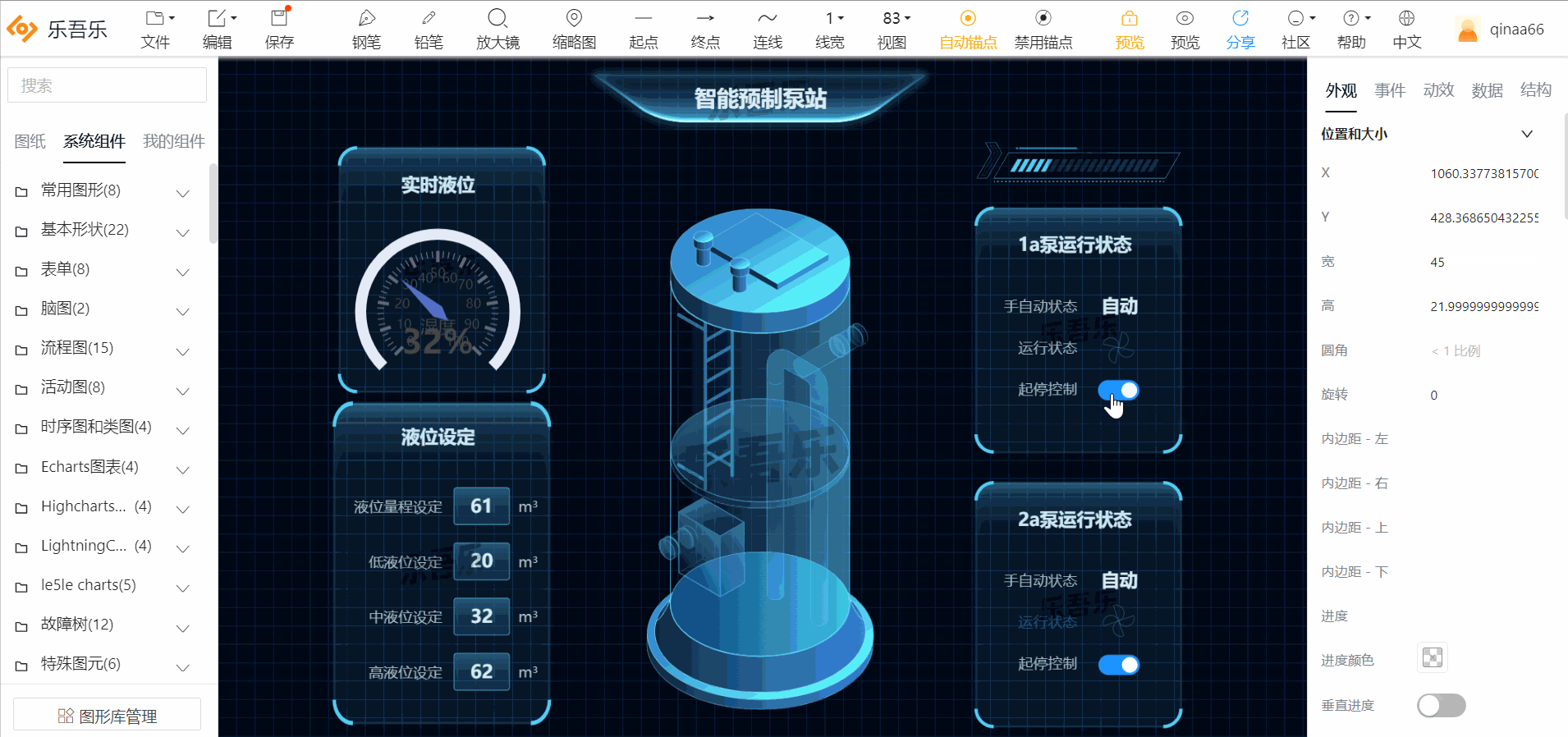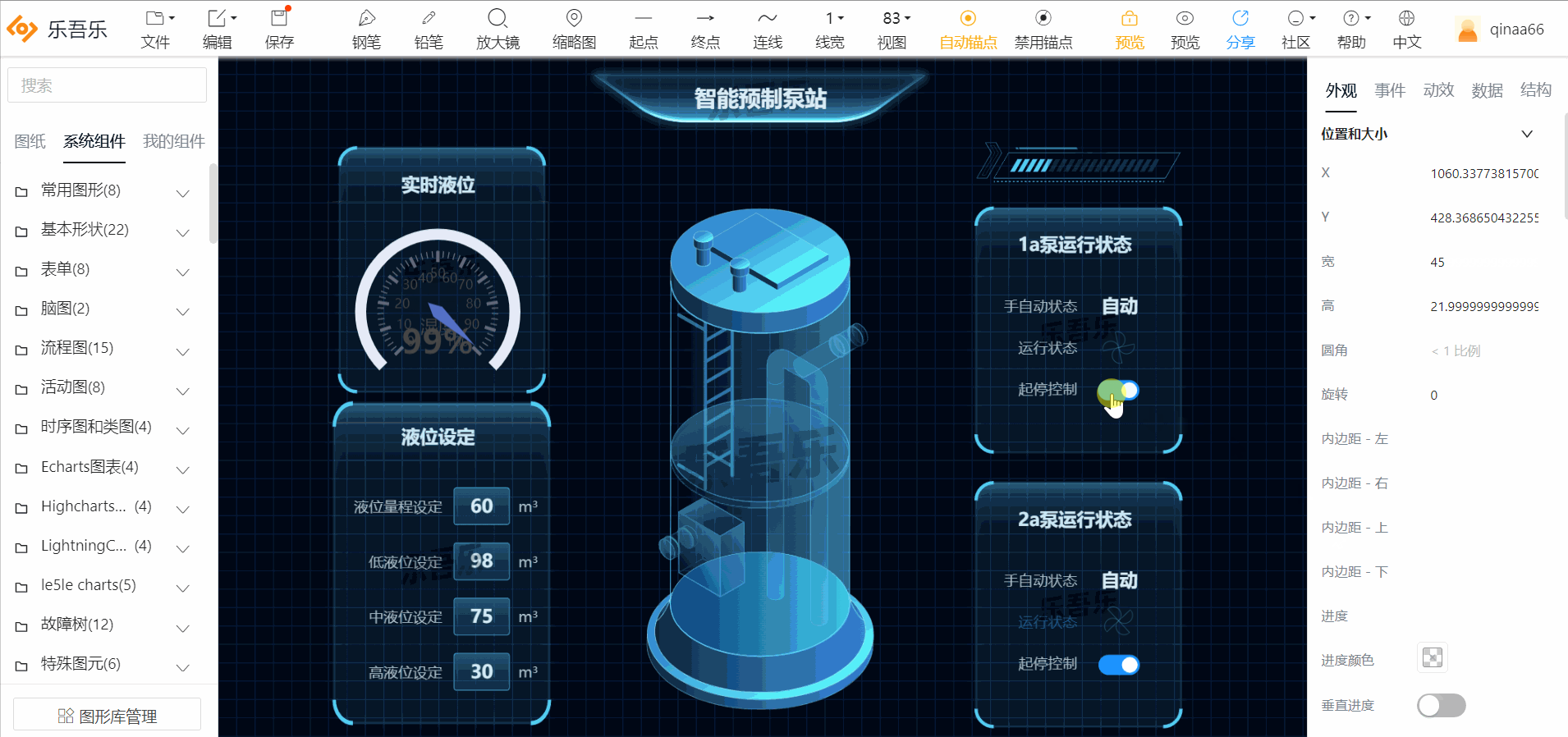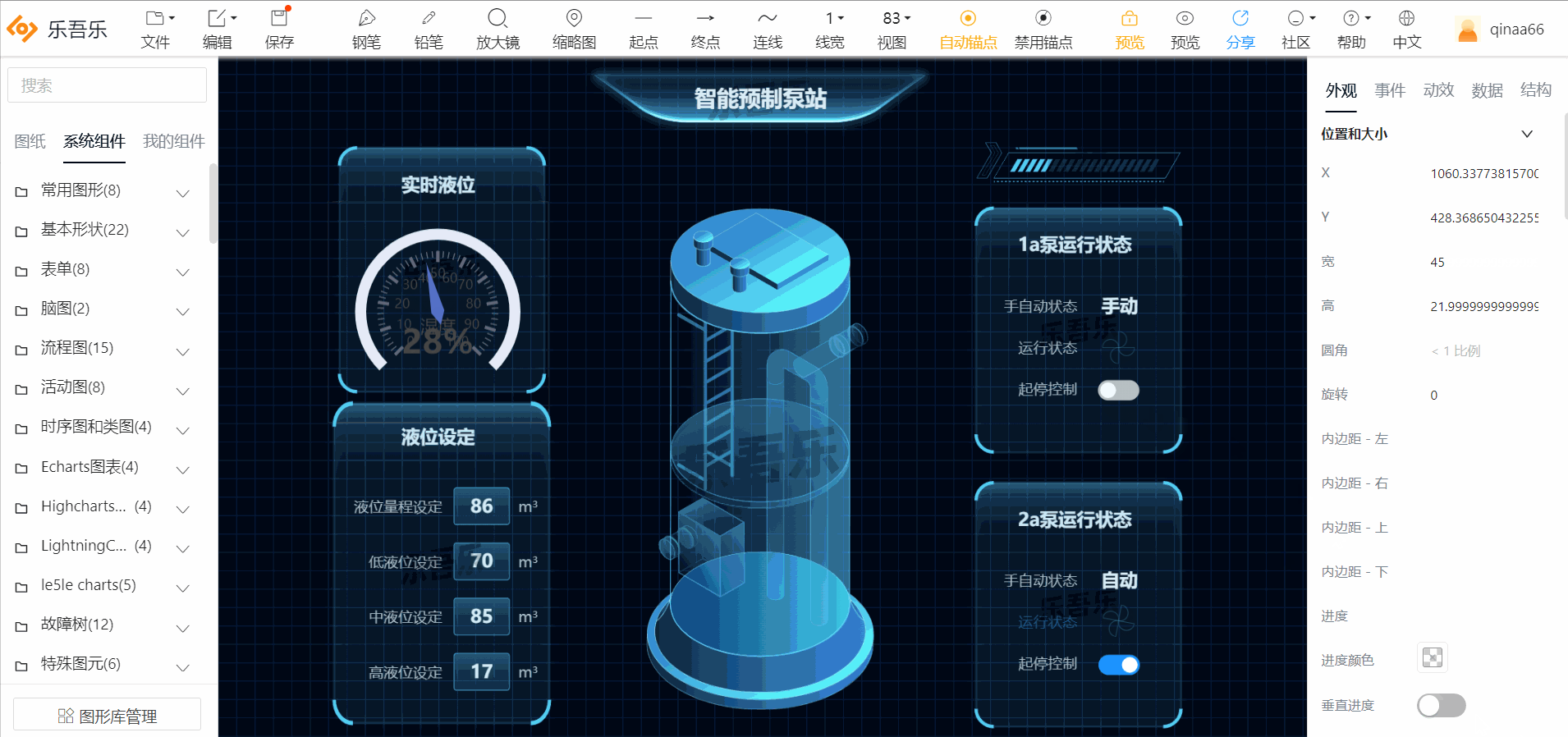
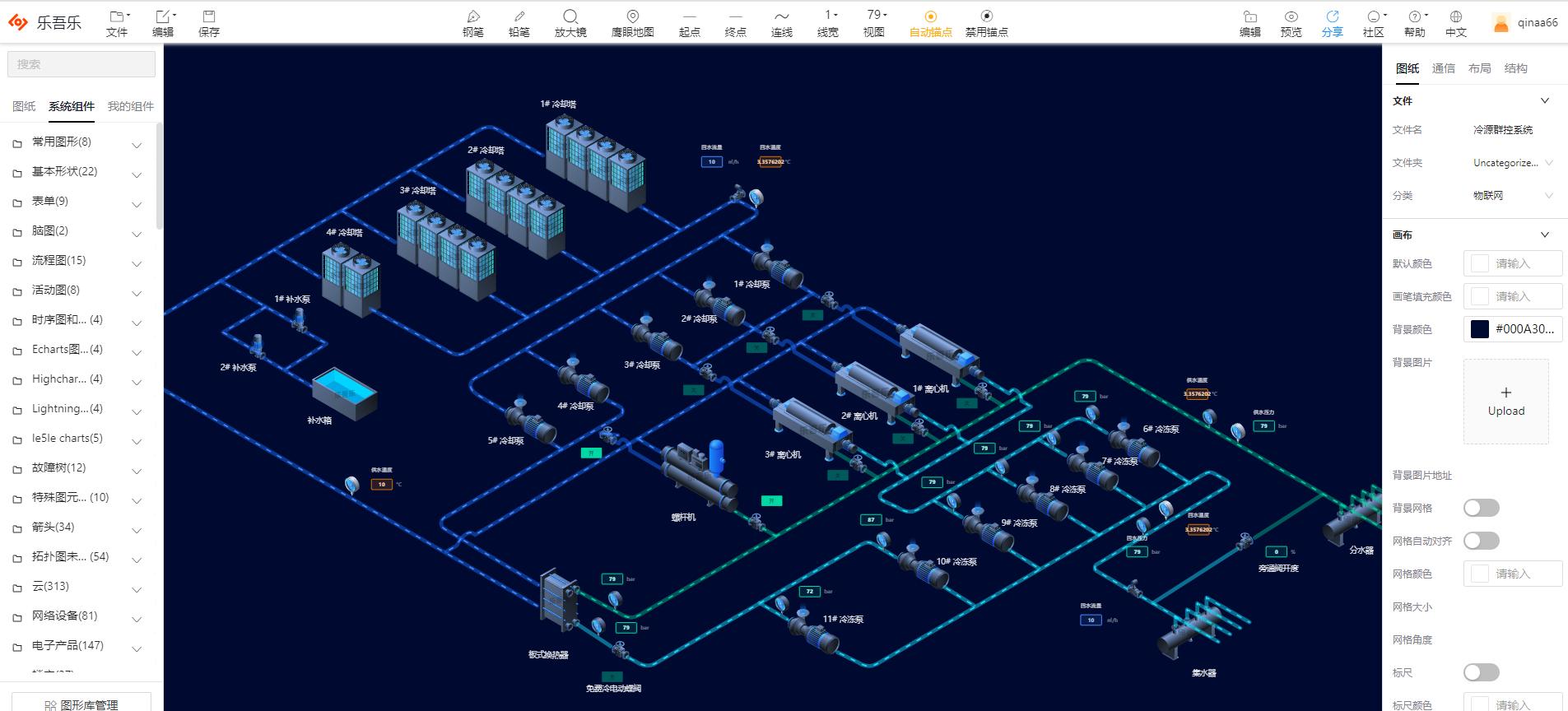
2.冷源群控制系统
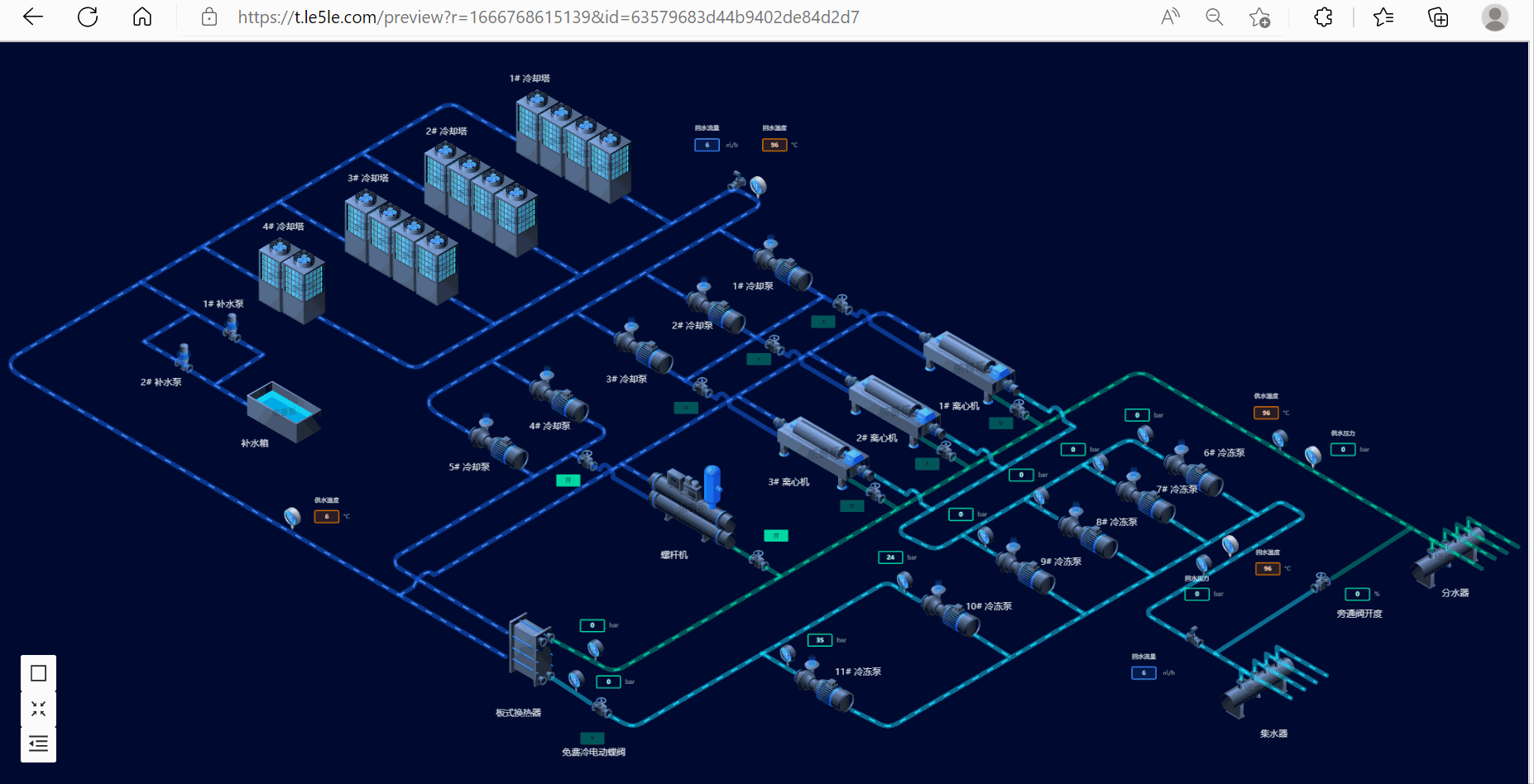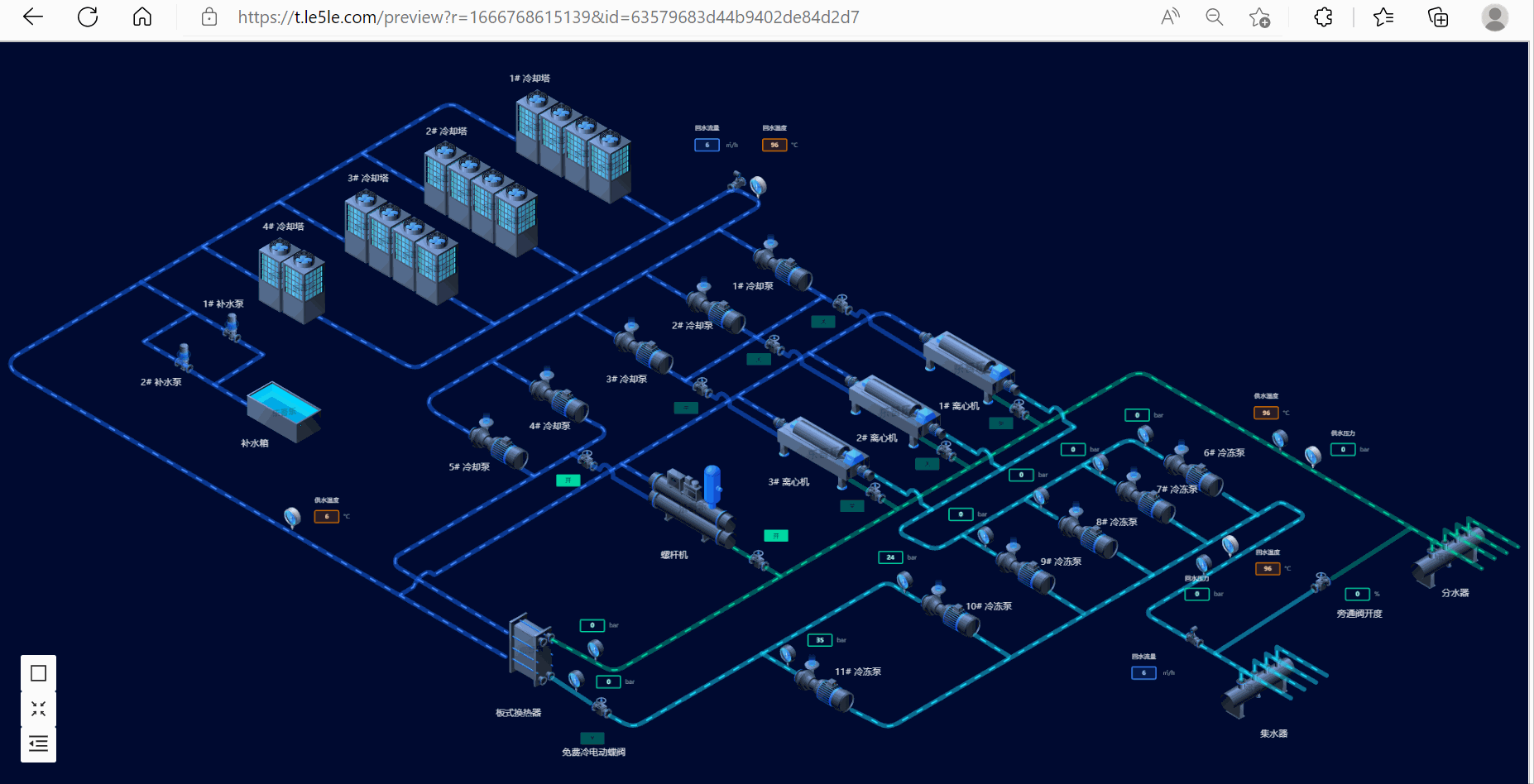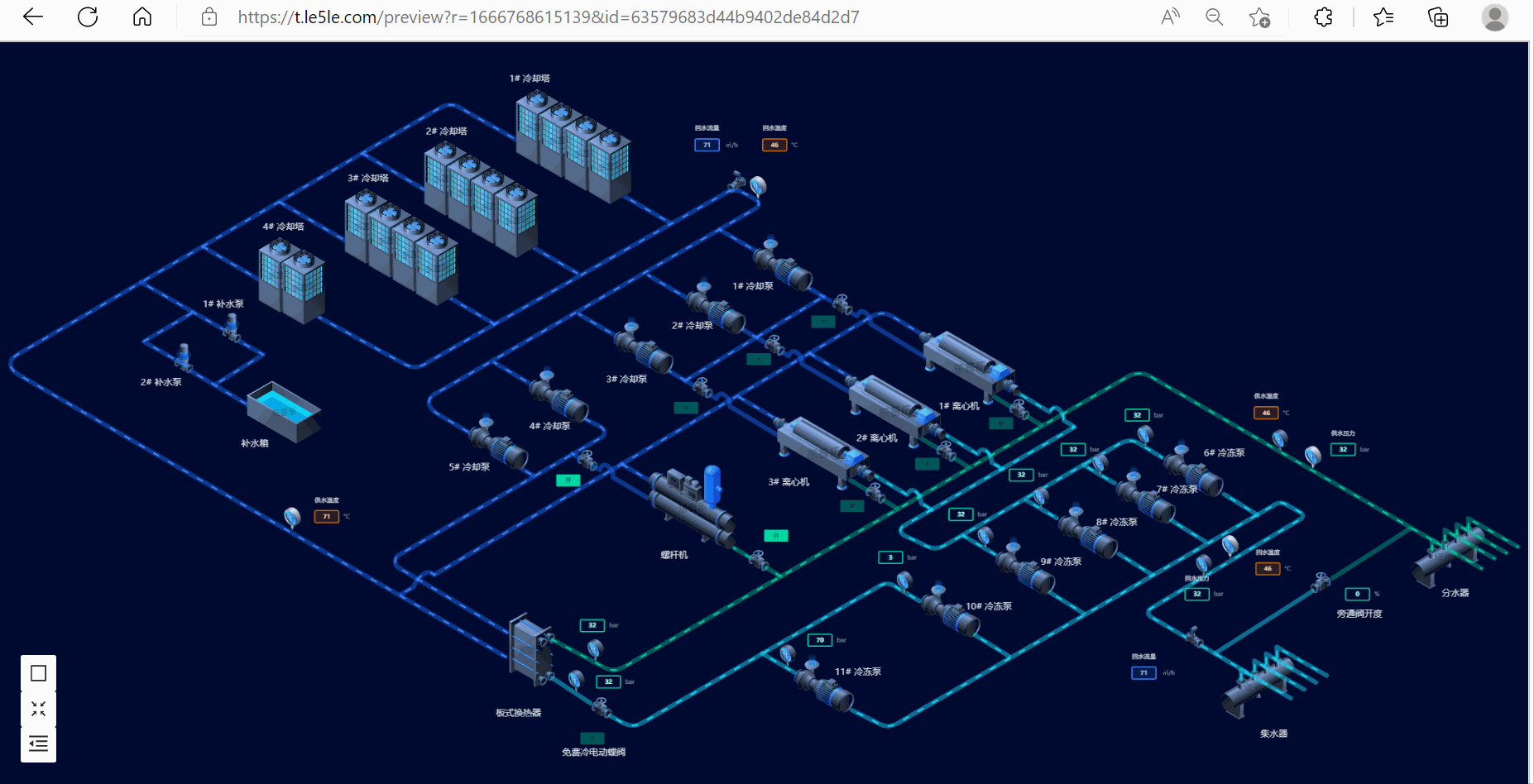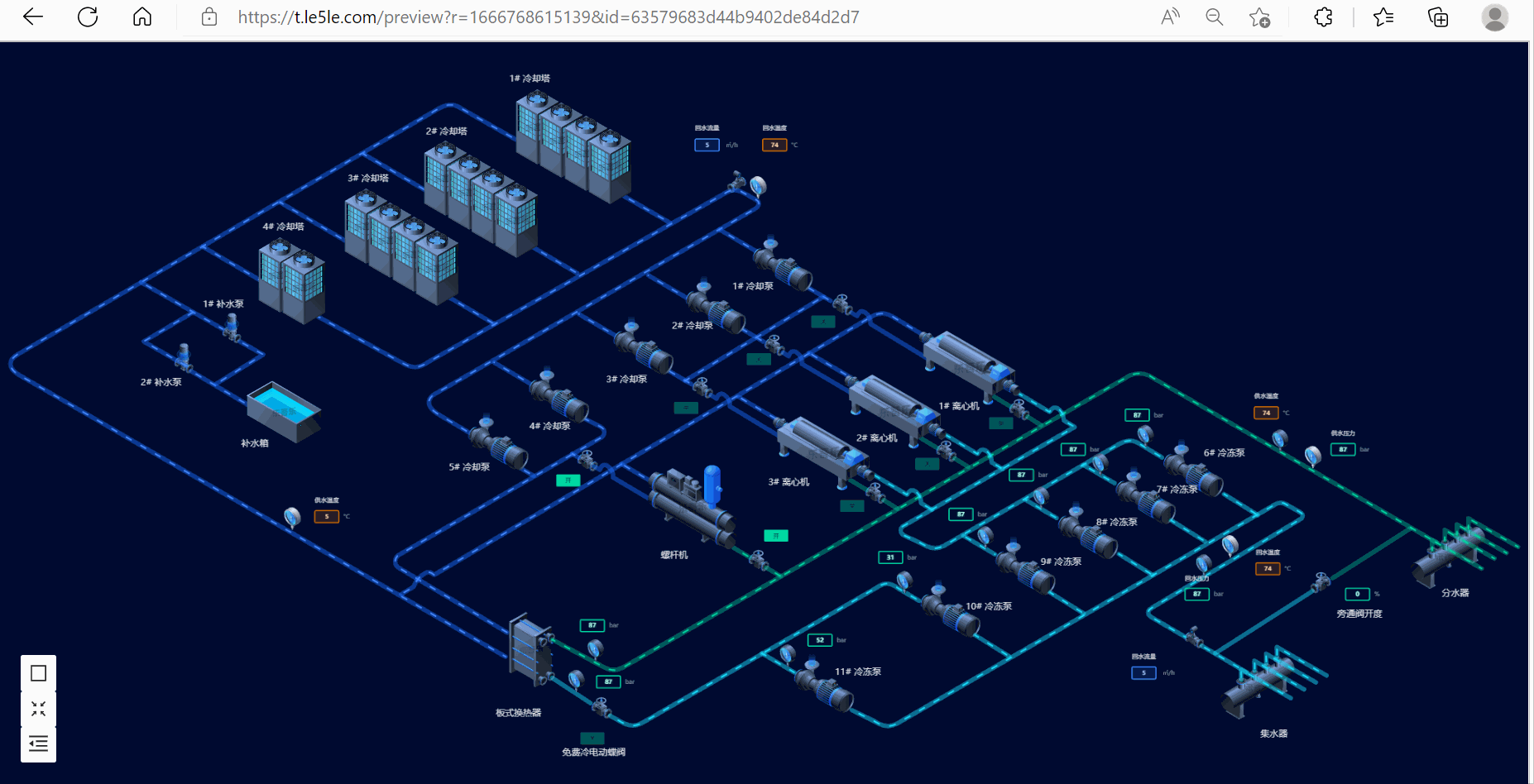
3.废水处理
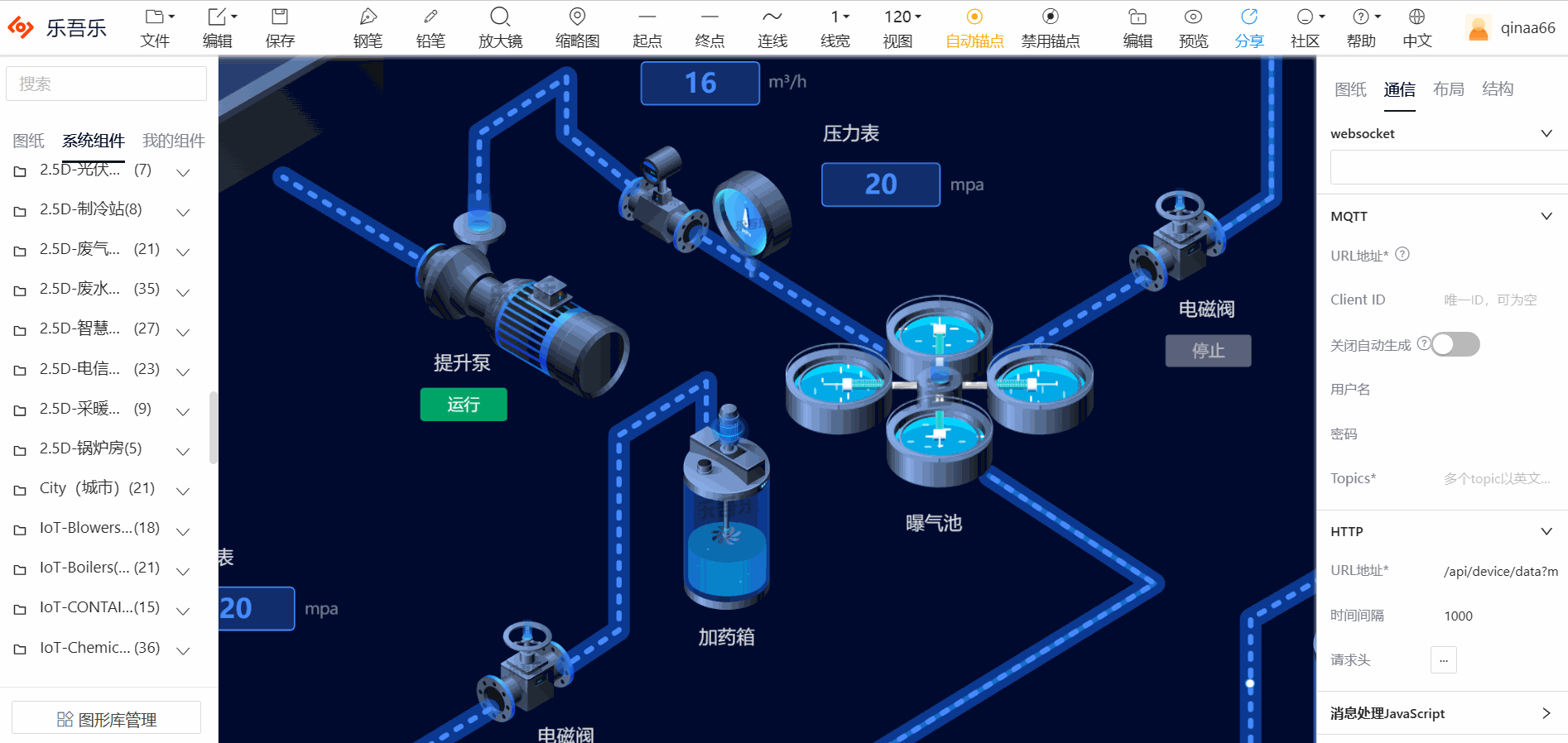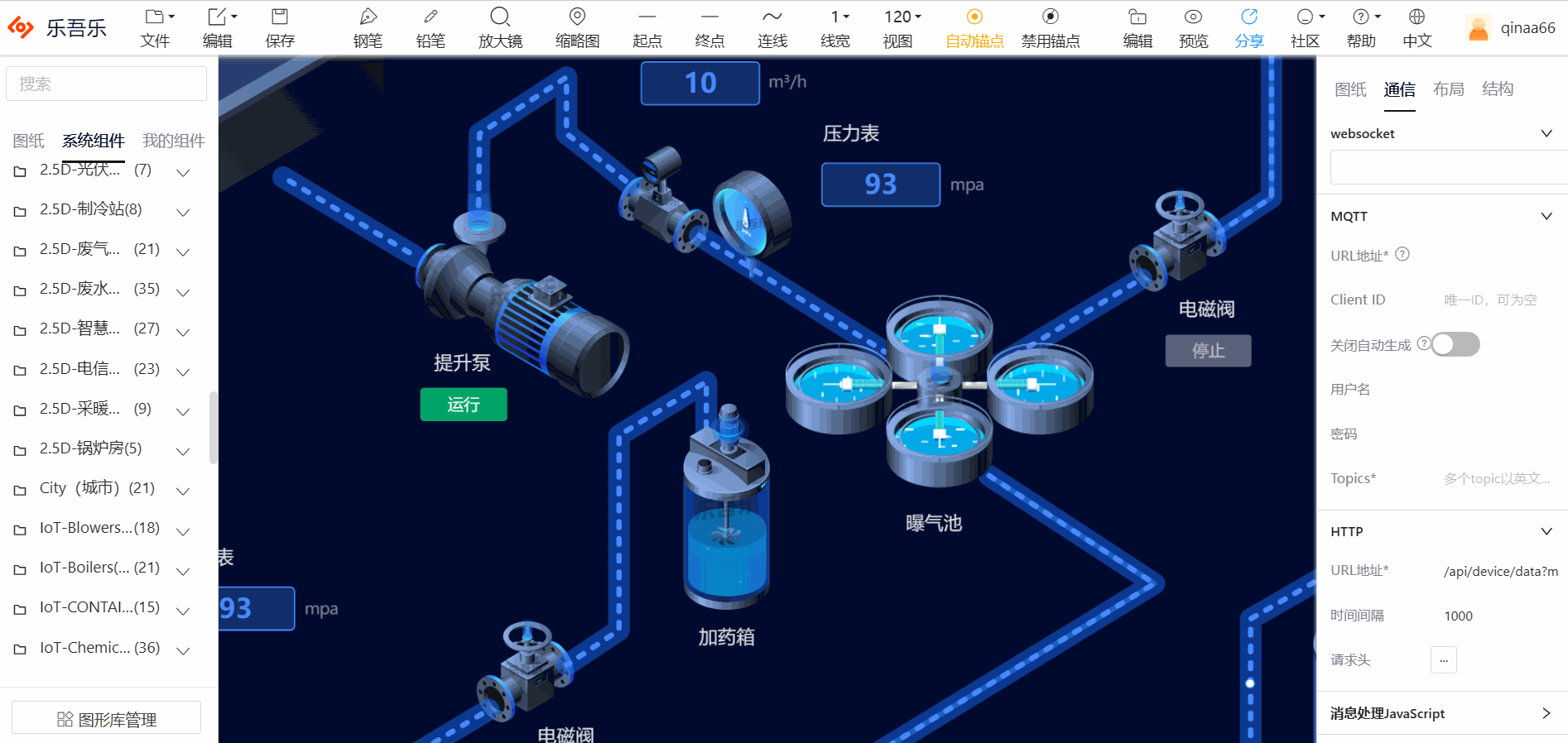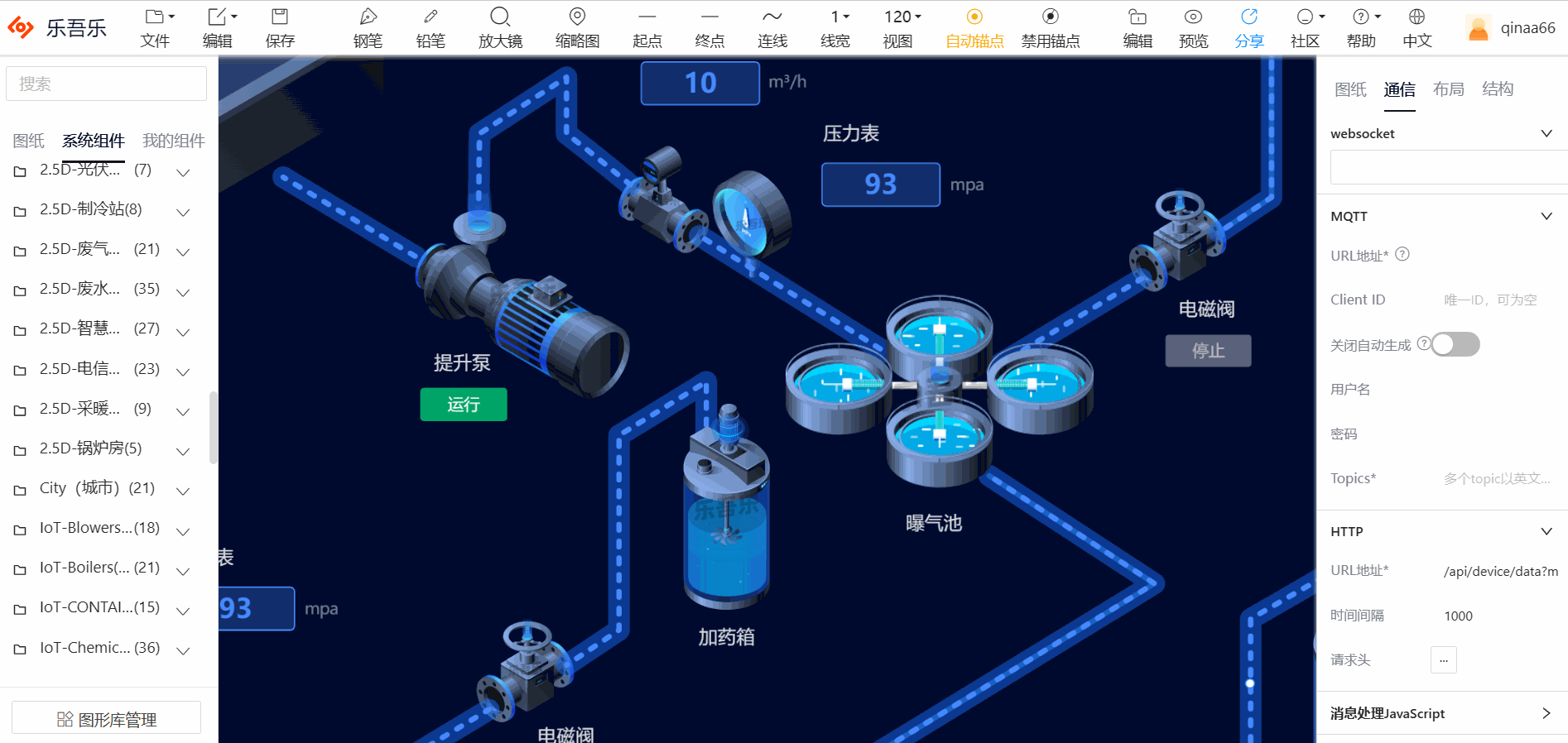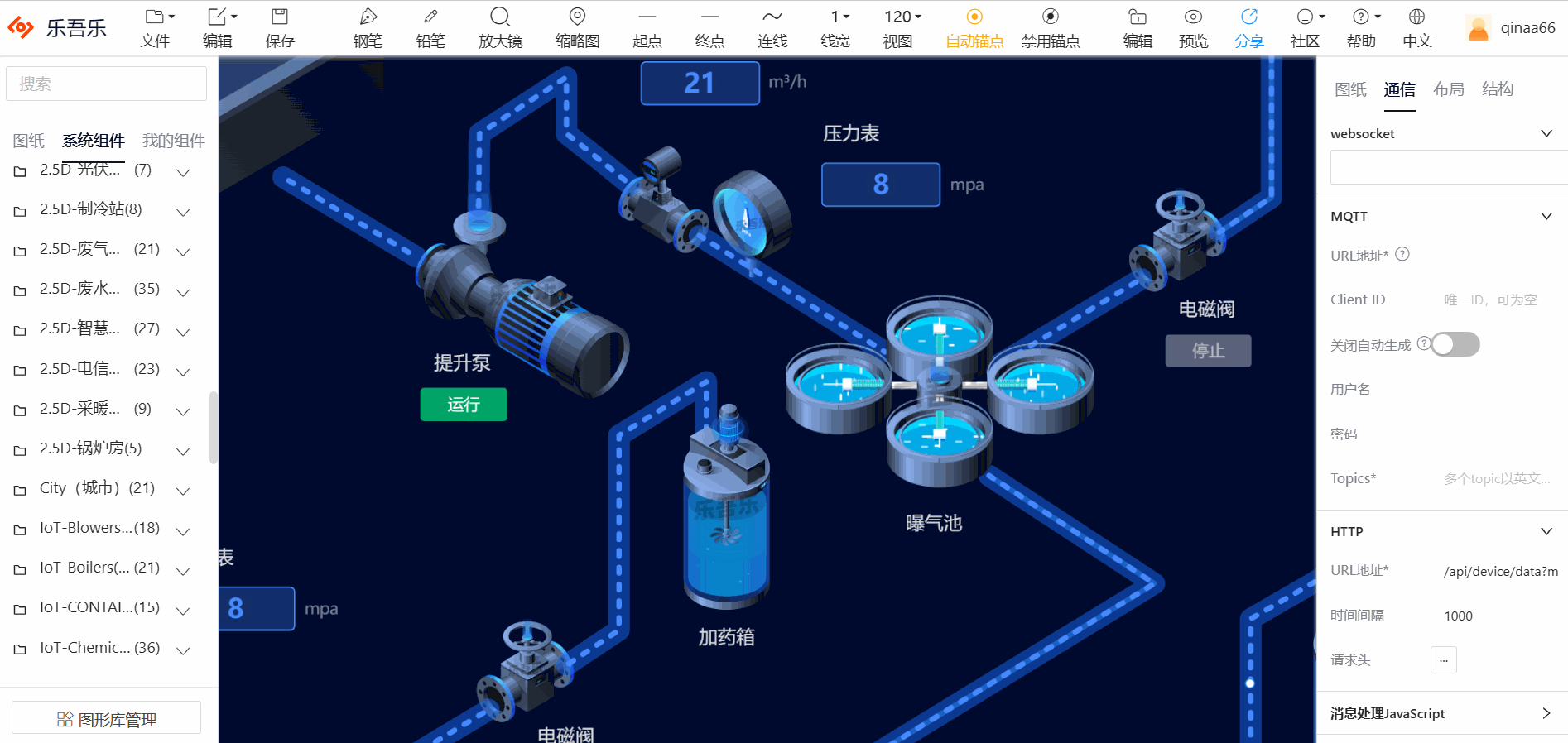
4.电信机房

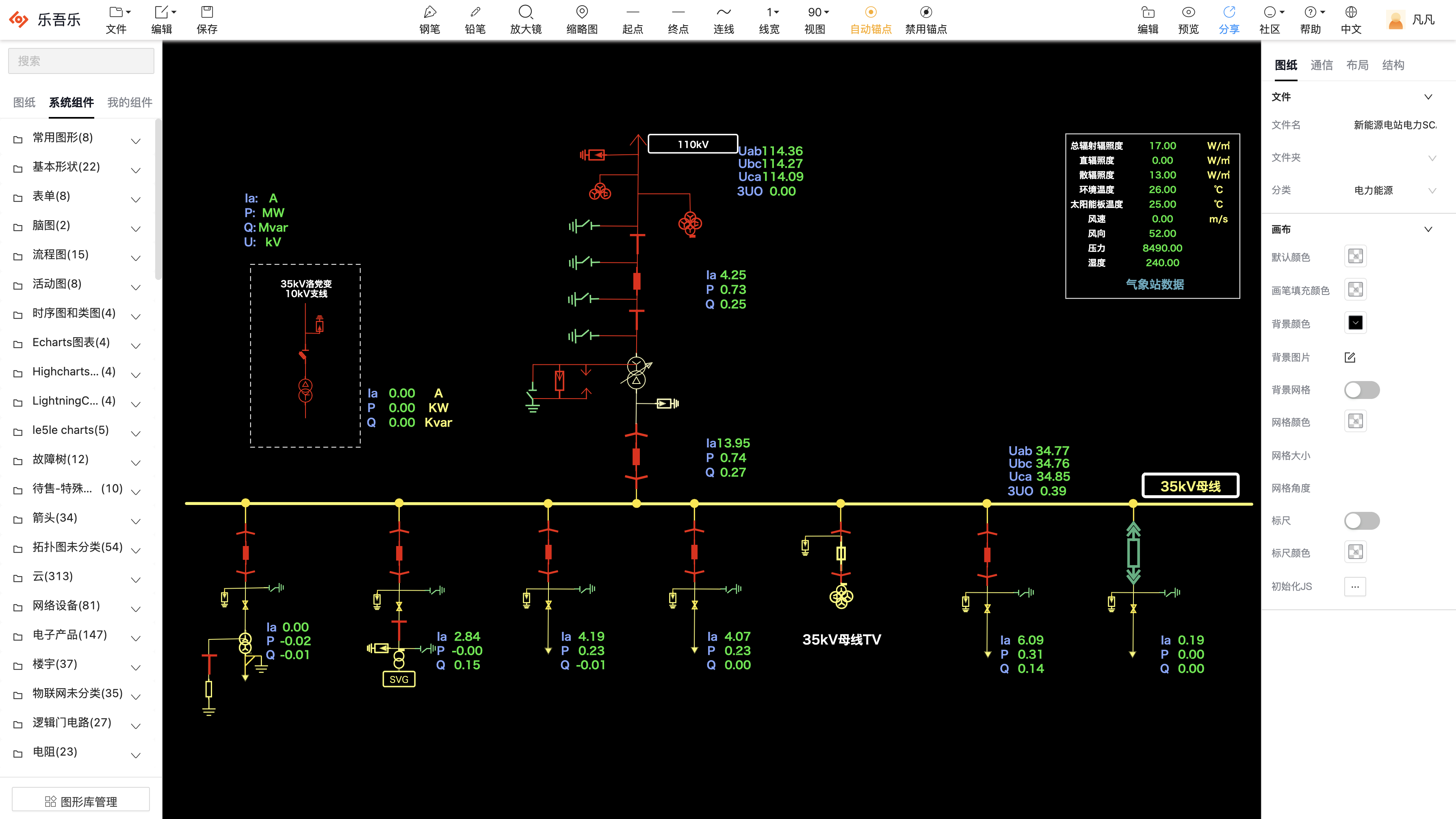
5.电力能源
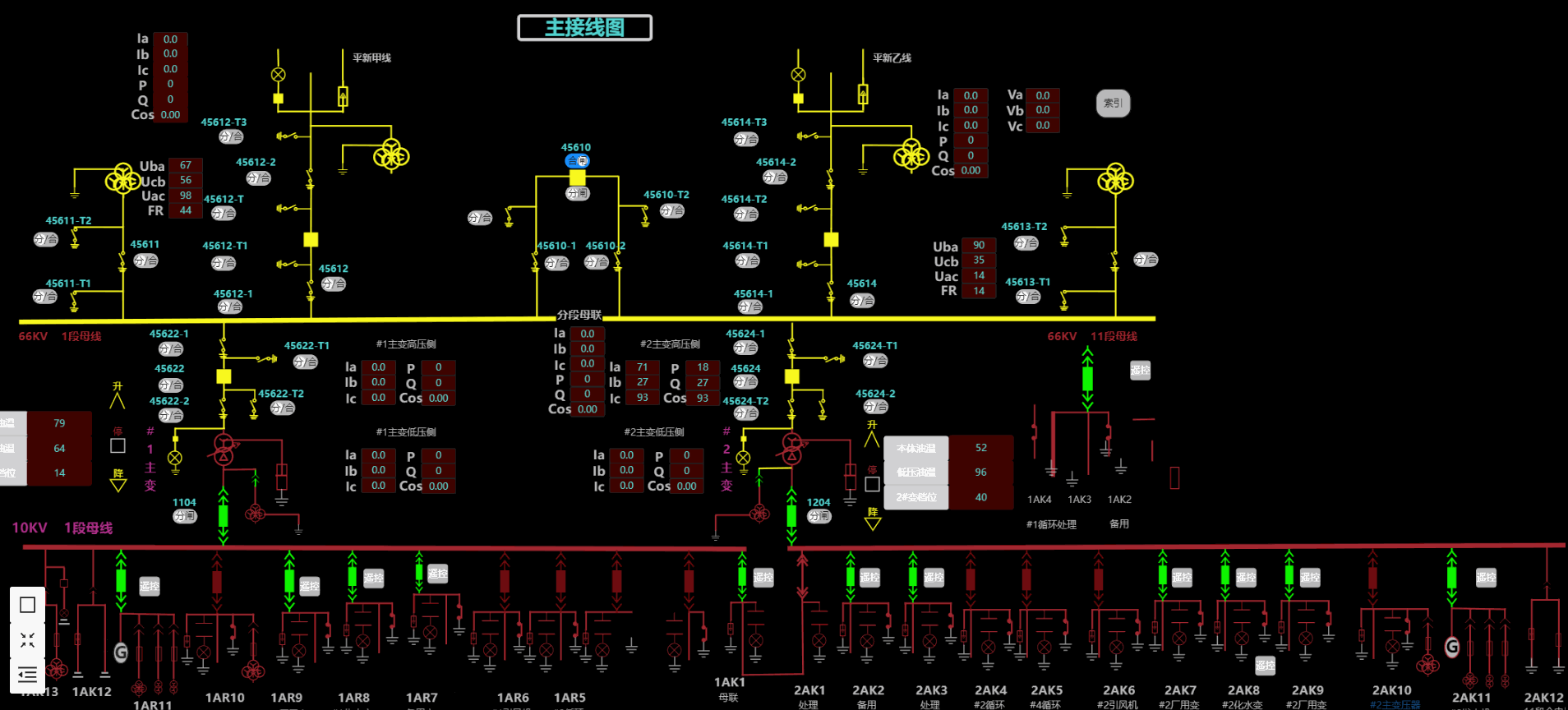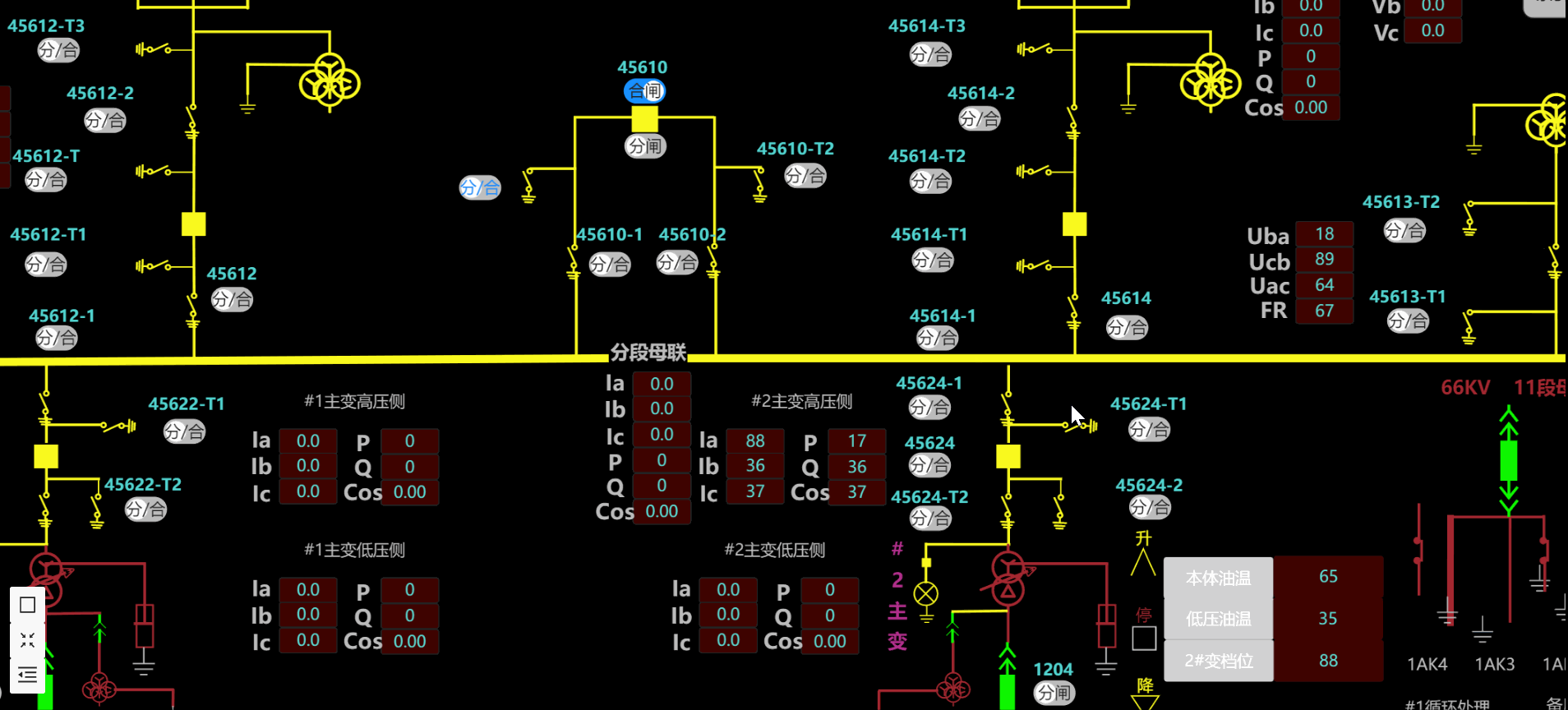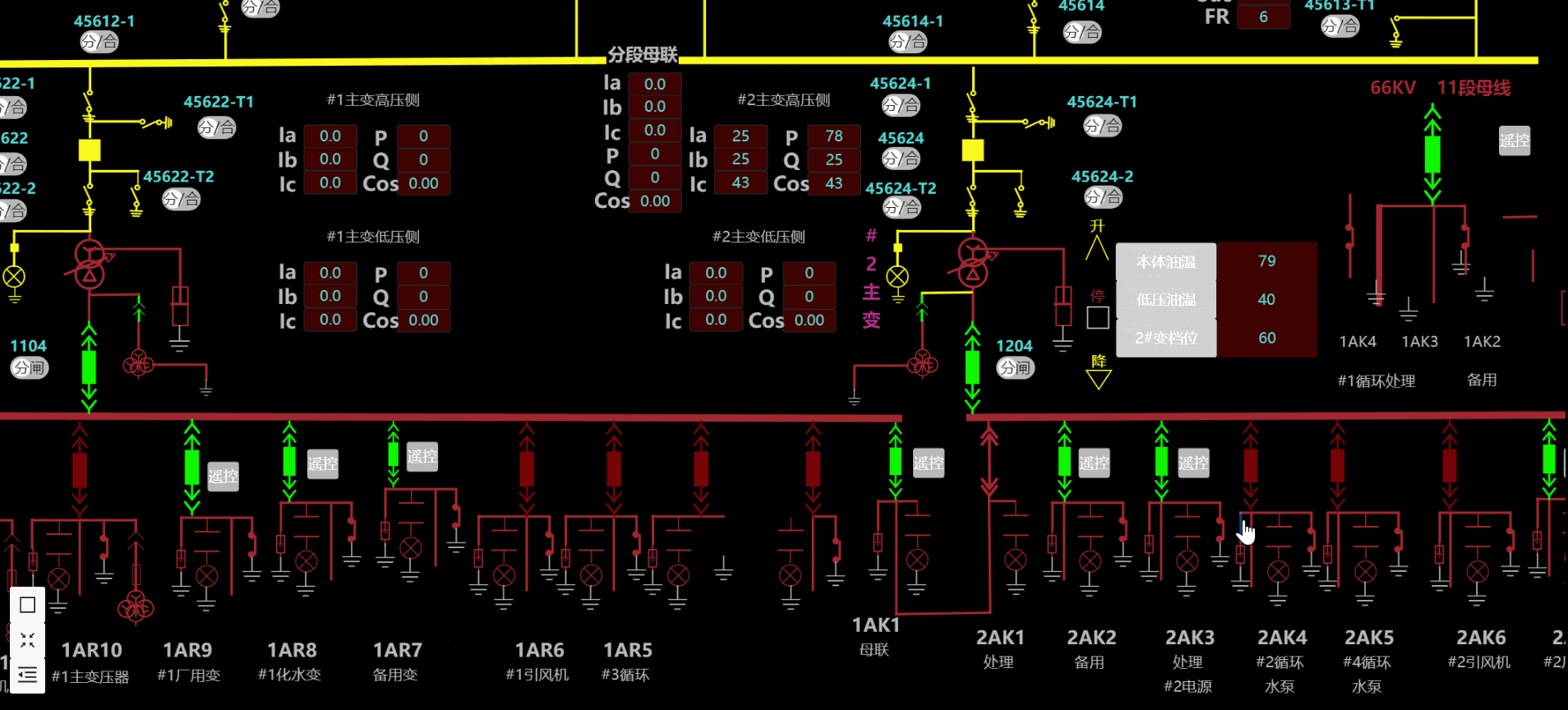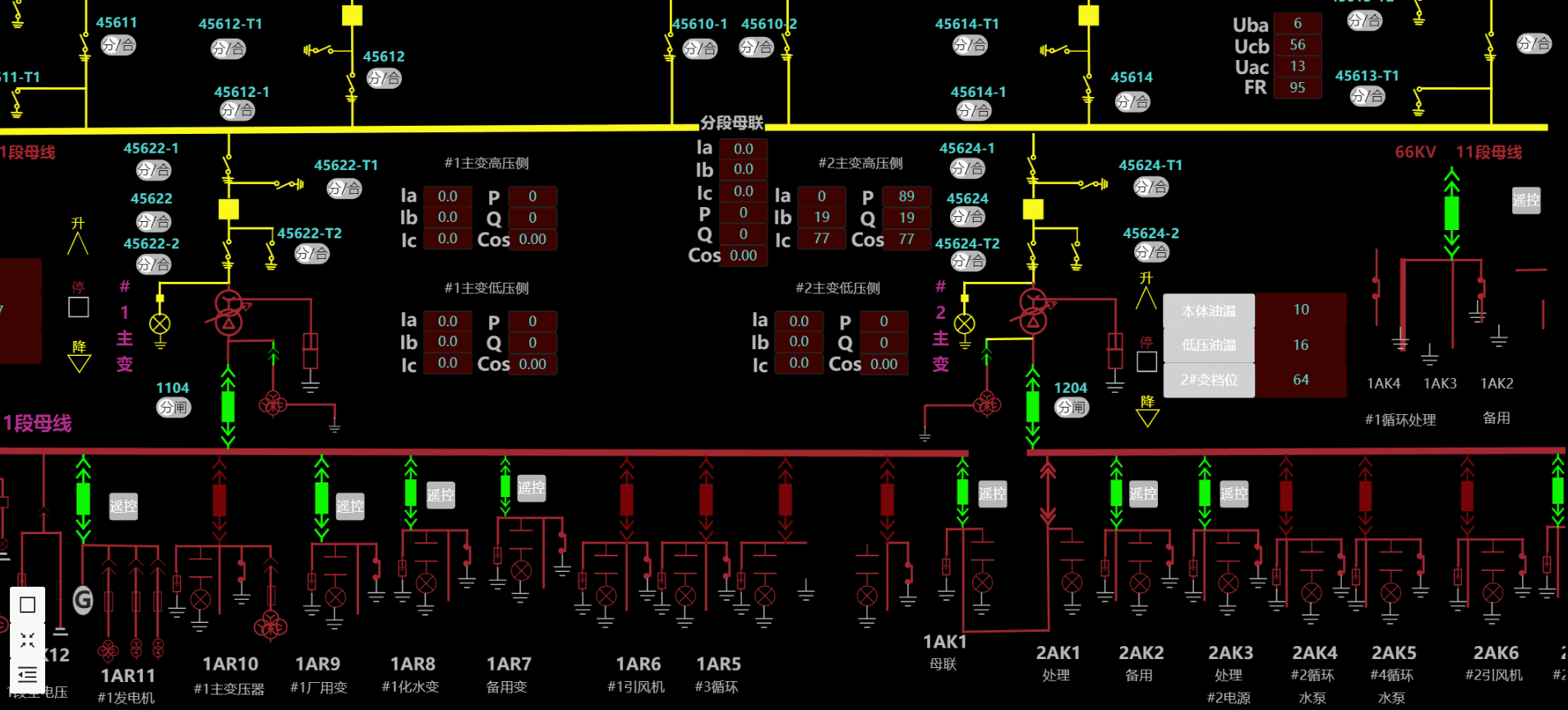
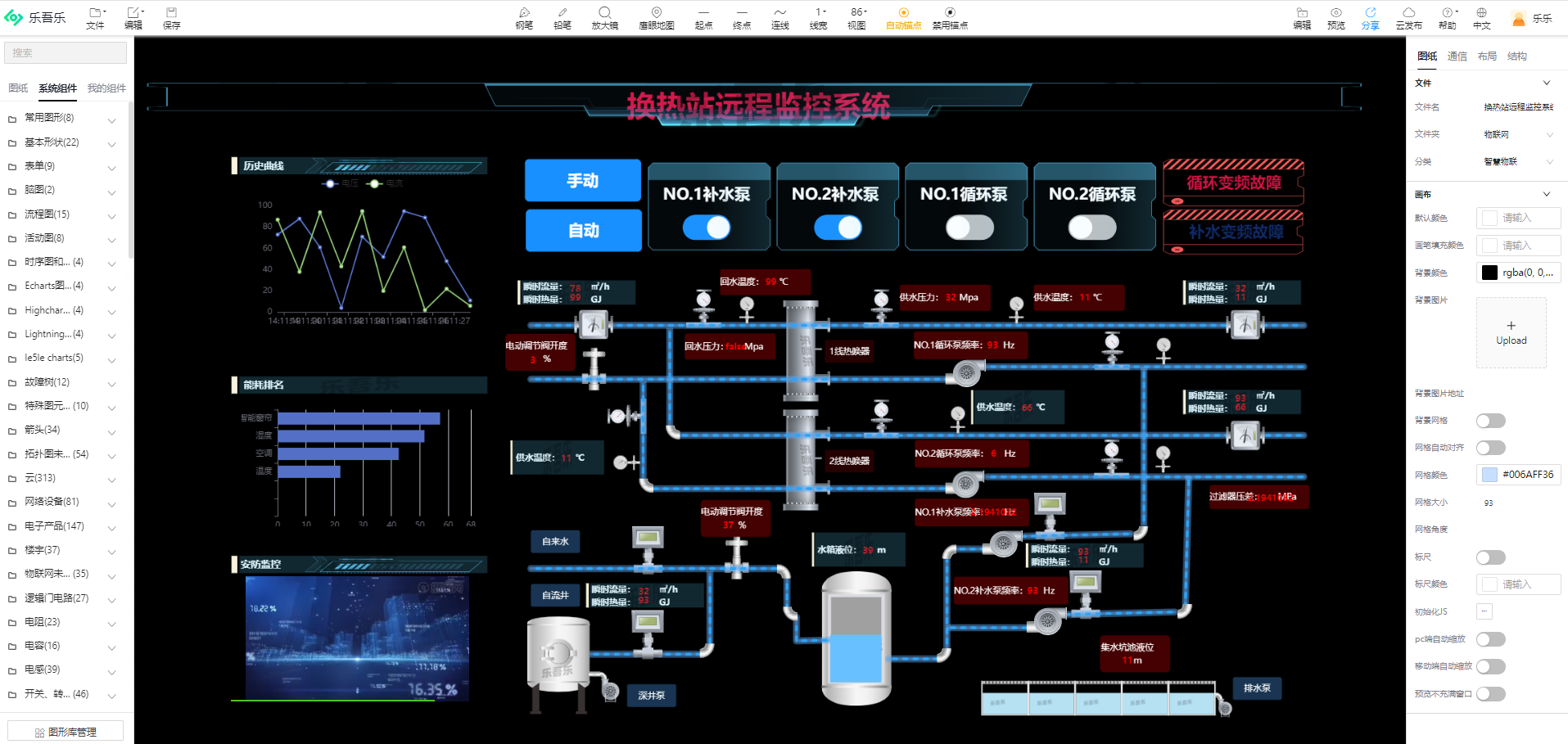
6.热换站远程监控系统
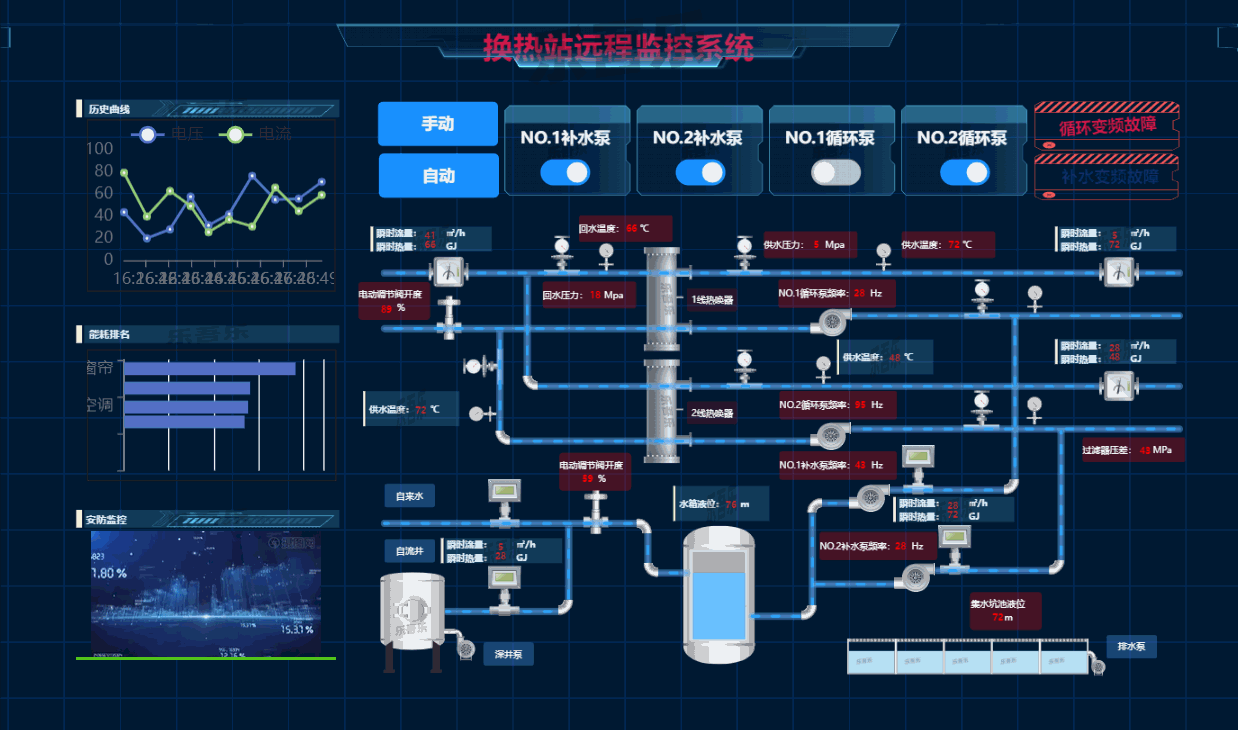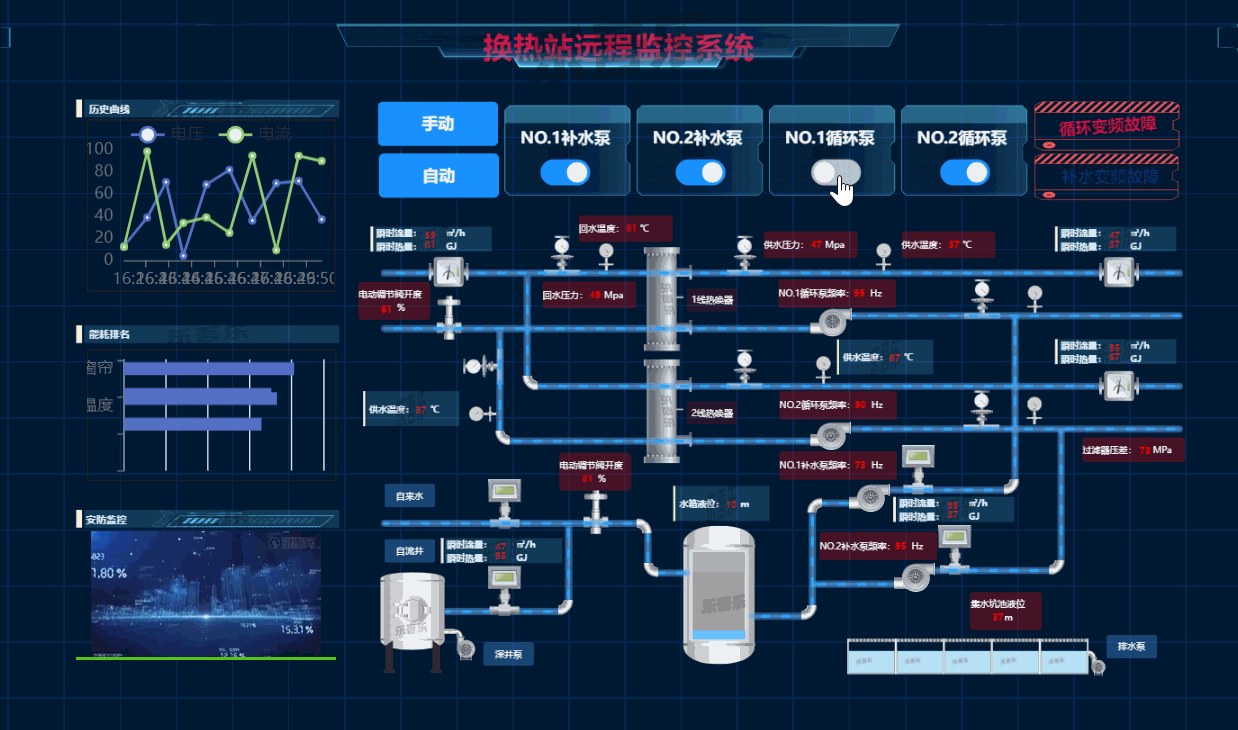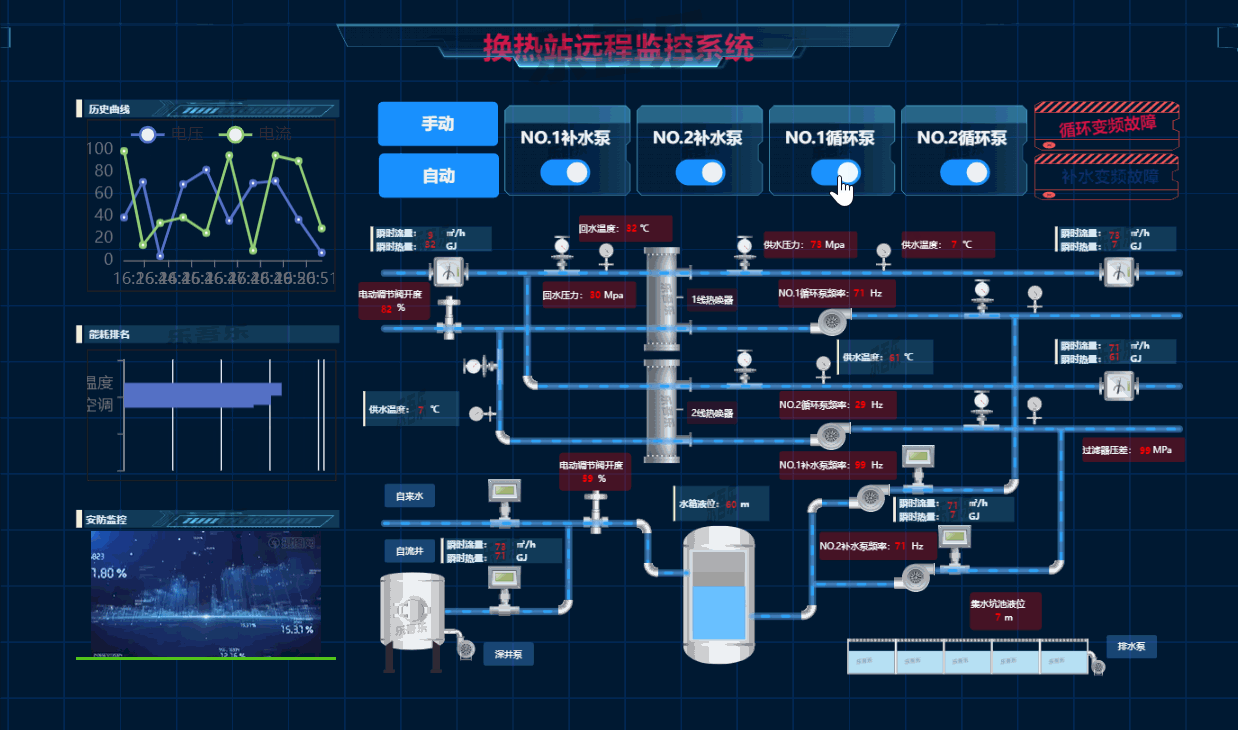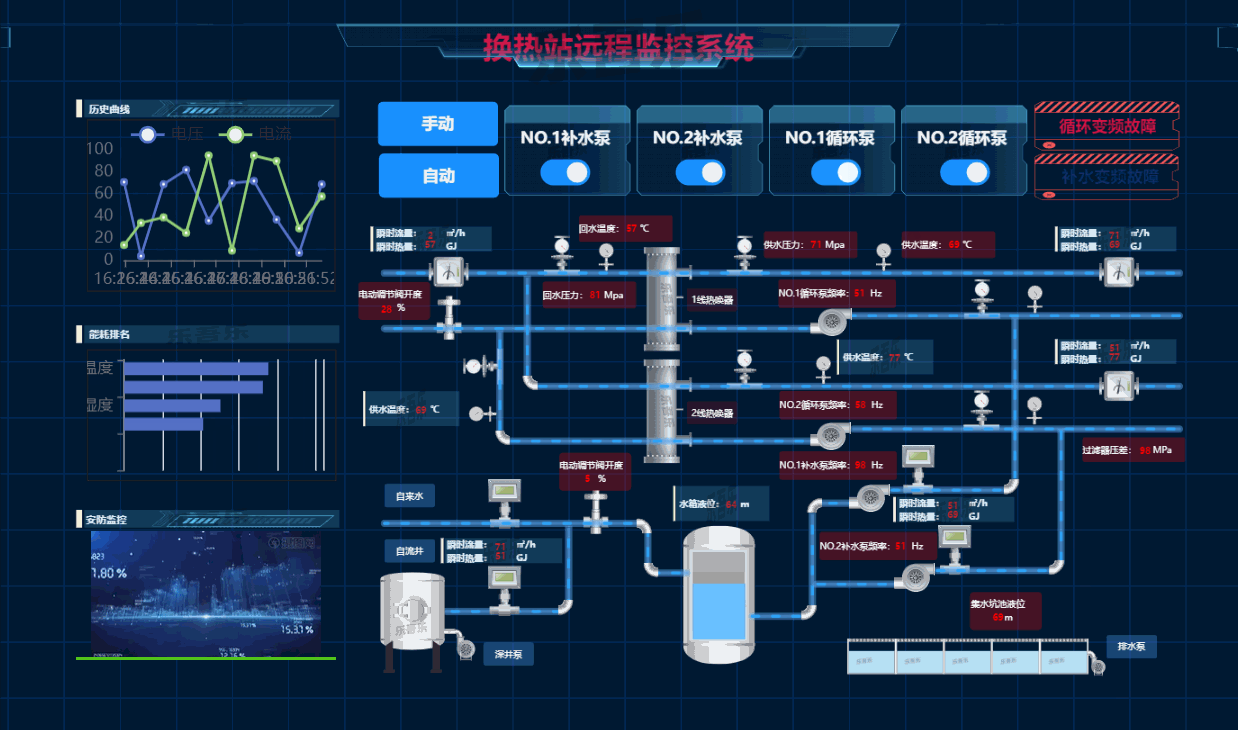
7.智慧交通

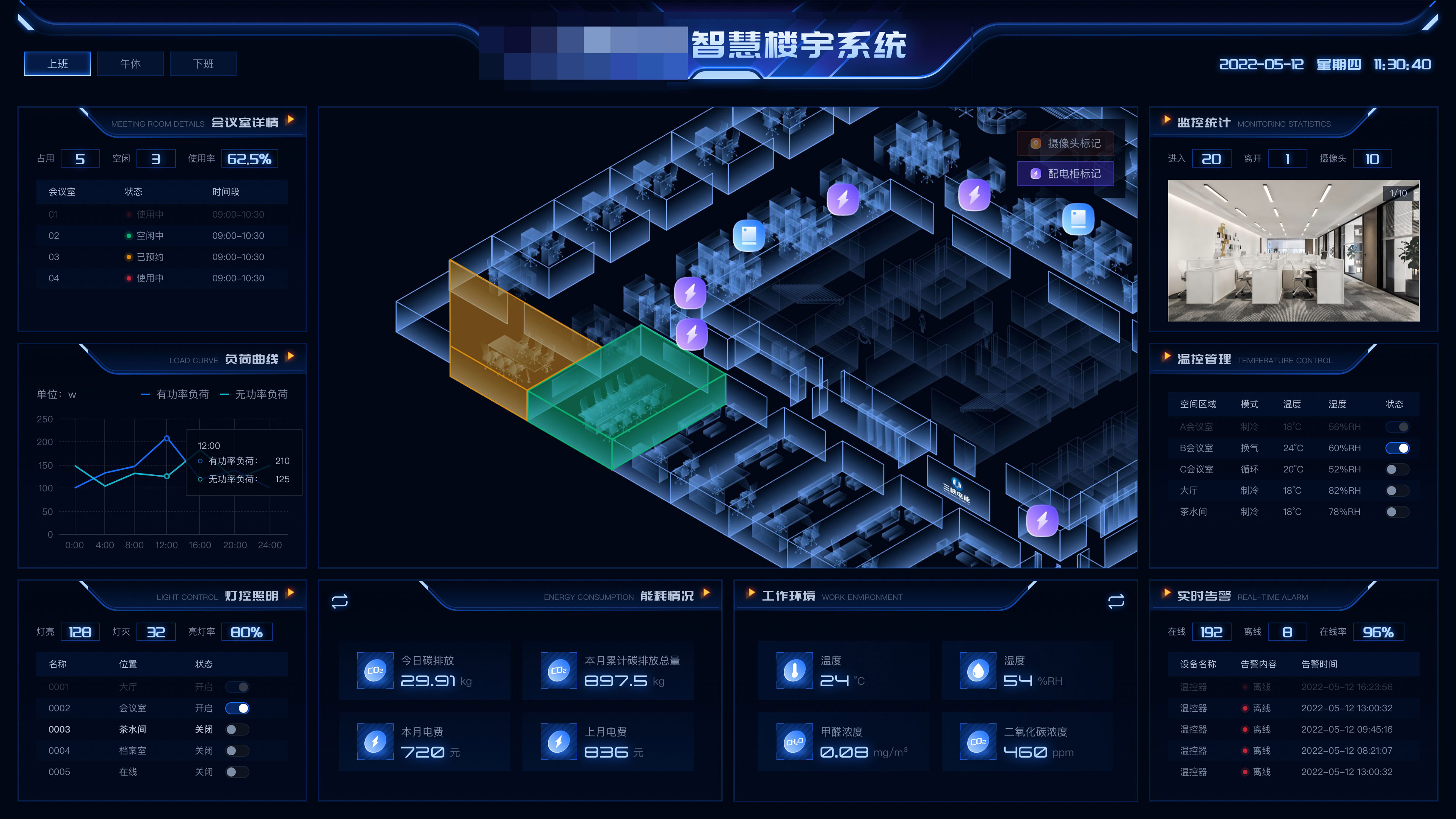
8.智慧楼宇系统
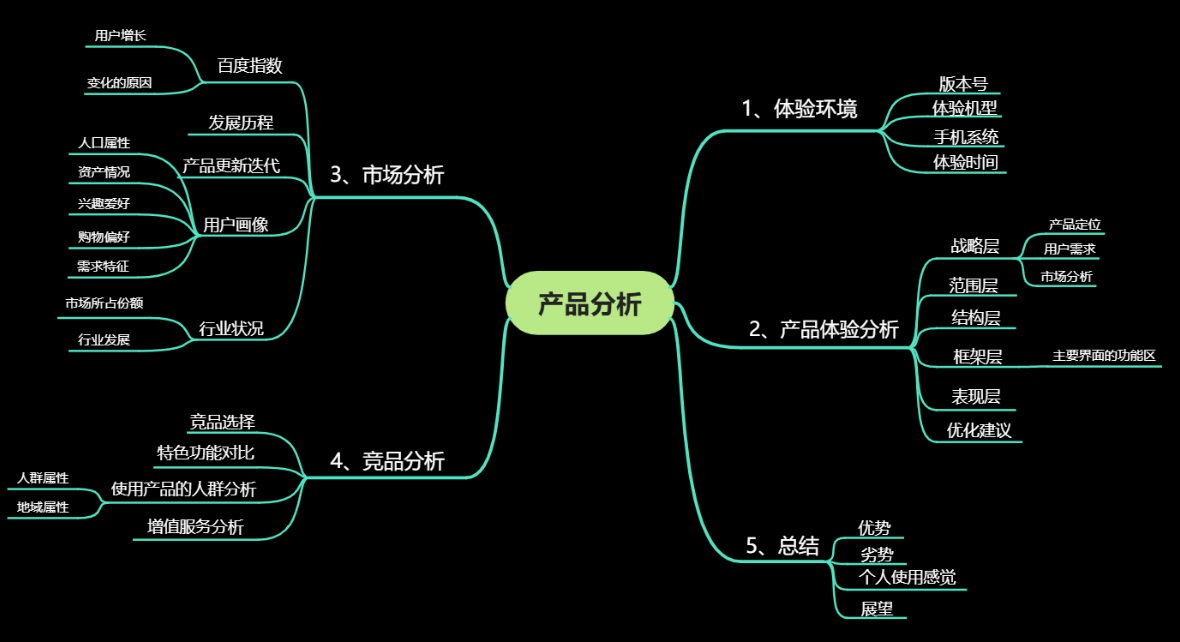
9.思维导图
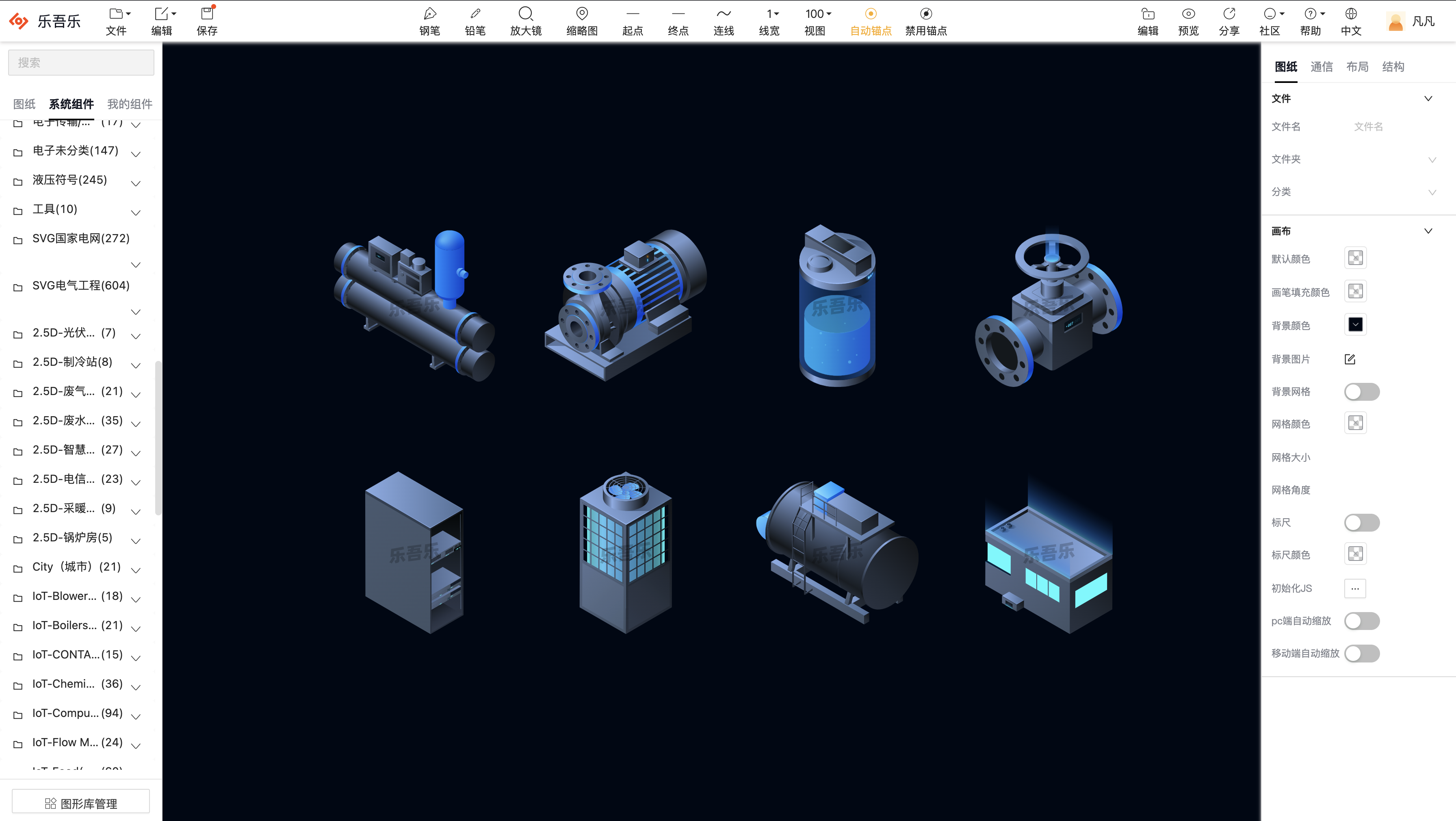
10.自定义图形库
4.在线使用
在线使用:乐吾乐2D可视化
解决方案:炫酷智能的数字可视化平台
部署试用: 文档中心 - 乐吾乐Le5le
这篇关于【乐吾乐2D可视化组态编辑器】Web组态、SCADA、数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





