本文主要是介绍Elasticsearch 管道查询语言 ES|QL 现已正式发布,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Costin Leau, George Kobar

今天,我们很高兴地宣布 ES|QL(Elasticsearch 查询语言)全面上市,这是一种从头开始设计的动态语言,用于转换、丰富和简化数据调查。在新的查询引擎的支持下,ES|QL 使用简单且熟悉的查询语法和并发处理来提供高级搜索,无论数据源和结构如何,都可以提高速度和效率。
借助 ES|QL 的管道语法,用户可以轻松链接多个操作,简化复杂的数据调查并使查询更加直观和迭代。对于安全性和可观察性用户来说,ES|QL 会感到既熟悉又创新,因为它通过易于使用的查询语言展示了 Elasticsearch 的高级搜索功能。 ES|QL 与 Kibana 集成,增强了数据可视化和分析体验,使用户能够在一个屏幕上进行整个调查,而无需在多个窗口之间切换。
通过不断发展,我们的目标是将 ES|QL 打造成适用于所有 Elasticsearch 用例的通用语言,包括检索增强生成 (RAG)。将 RAG 与地理空间功能和 ES|QL 集成将提高来自不同数据源的查询准确性。 ES|QL 与新的 Search AI Lake 架构的结合可根据需求自动调整资源,从而增强可扩展性、成本效率并简化管理。将计算与存储分离、索引与搜索分离可提高性能和灵活性,确保更快地检索和调查大量数据。
对于面临日益增长的可观察性和安全性需求的团队来说,ES|QL 将成为一个差异化因素。本文将深入探讨你可以在自己的用例中使用 ES|QL 的各种好处和方式。
Elasticsearch 的进步
14 年来,QueryDSL 一直作为 Elasticsearch 的基础语言,为众多组织提供搜索、可观察性和安全性。随着用户需求的发展,很明显他们需要的不仅仅是 QueryDSL 本身所能提供的。他们寻求一种查询语言,不仅可以简化数据调查,还可以通过将搜索、丰富、聚合和可视化集成到一个单一、高效的界面中来增强查询体验。他们需要先进的搜索功能,包括具有并发处理的查找功能,以处理来自不同来源和结构的大量数据。
为此,我们从向量化查询执行和其他数据库技术中汲取灵感,开发了 Elasticsearch 查询语言 (ES|QL)。借助 ES|QL,用户可以使用熟悉的管道 (“|”) 语法来链接操作,从而实现变革性的详细数据分析。
FROM logs-system.auth*
| WHERE host.os.type == "linux"AND event.outcome == "success"AND system.auth.ssh.event == "Accepted"AND (user.name IS NOT NULLAND source.ip IS NOT NULLAND source.port IS NOT NULLAND system.auth.ssh.method IS NOT NULL)
| STATS auth_count = COUNT(*) BY user.name, source.ip,source.port, system.auth.ssh.method
| SORT auth_count DESC
ES|QL 由强大的查询引擎提供支持,提供高级搜索功能以及跨核心和节点的并发处理,使用户能够无缝地跨不同数据源和结构进行查询。
没有对 Query DSL 的翻译或转译;每个 ES|QL 查询都经过语义解析、分析和验证,并优化为在保存数据的相关节点上并行执行的执行计划。目标节点处理查询,使用 ES|QL 提供的框架对执行计划进行即时调整。结果是开箱即用的闪电般快速的查询。
通向正式发布之路
自 8.11 推出以来,ES|QL 一直在不断完善和增强。测试阶段使我们的工程团队能够从社区收集宝贵的反馈,使我们能够迭代并满足用户的首要需求。在整个过程中,我们增强了 ES|QL 的功能,同时确保稳定性、性能以及与你日常使用的核心数据探索和可视化用户体验和工作流程的无缝集成。以下是使 ES|QL 全面可用的一些功能。
稳定性和性能
我们一直在忙于增强专用的ES|QL查询引擎,以确保其在负载下保持稳健的性能,保障运行节点的稳定性。也就是说,请参阅下面过去 6 个月中分组的改进(有关潜在更改的更多测试和确切详细信息,请参阅专用基准测试页面)。
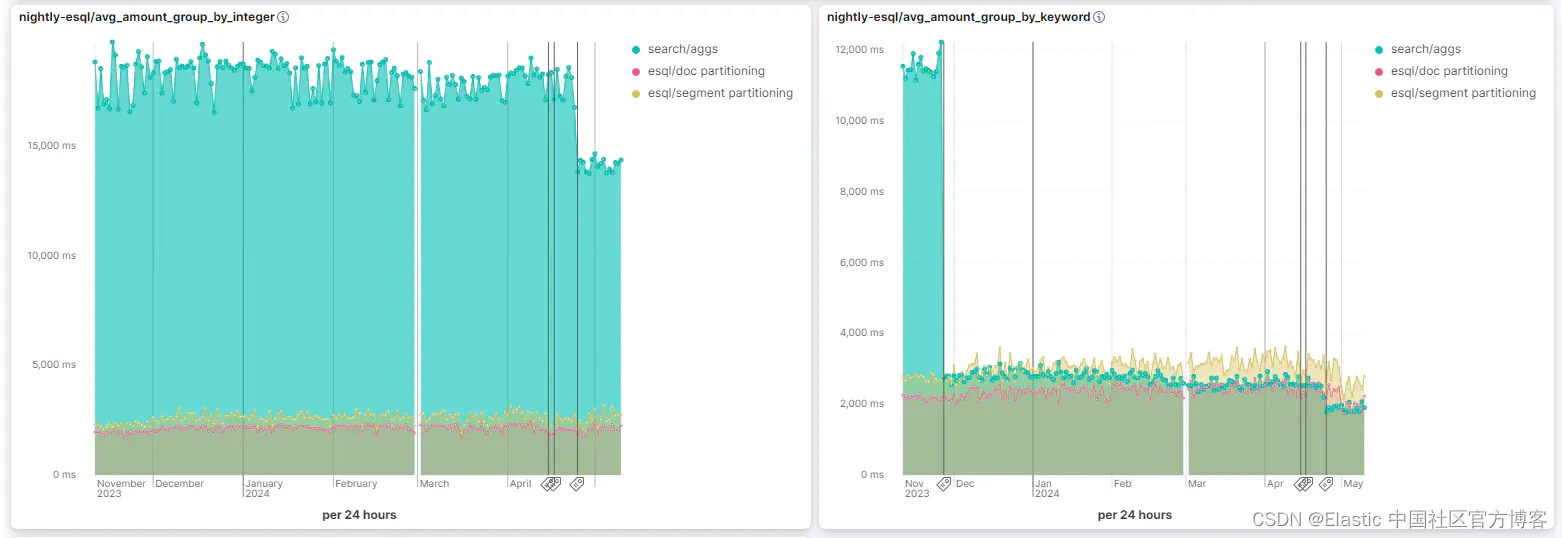
此外,我们还实施了内存跟踪以实现精确的资源管理,并进行了全面的压力测试(包括严格的 HeapAttack),以确保在资源密集型查询期间仔细监控内存使用情况。我们的断路器还可以防止大型和小型堆大小节点上出现 OutOfMemoryErrors (OOME)。
在 Kibana 中可视化数据 使用 ES|QL 以全新方式探索
ES|QL 与 Elastic AI 助手一起使用
我们很高兴能够将生成式 AI 和 ES|QL 结合在一起,首先将它们集成到可观察性和安全性 AI 助手中,允许用户输入翻译成 ES|QL 命令的自然语言,从而实现简单、迭代和流畅的工作流程。
可视化并执行 ES|QL 查询或使用内联编辑弹出按钮对其进行编辑,并将它们无缝嵌入到仪表板中。此增强功能允许在创建图表时进行内联可视化编辑,从而缩短了工作流程,使用户可以更轻松地直接在助手中管理和保存可视化效果。
显着改进查询生成和性能。用户现在可以使用自然语言来可视化 ES|QL 查询,使用内联编辑弹出按钮对其进行编辑,并将其无缝嵌入到仪表板中。此增强功能允许在创建图表时进行内联可视化编辑,从而缩短了工作流程,使用户可以更轻松地直接在助手中管理和保存可视化效果。
ESQL
直接从 Kibana 仪表板创建和编辑 ES|QL 图表
通过直接从 Kibana 仪表板内创建和修改使用 ES|QL 构建的图表,简化你的工作流程并快速洞察数据。你还可以在图表中执行 ES|QL 查询的内联编辑,以快速适应故障排除或威胁追踪中的变化。
ESQL
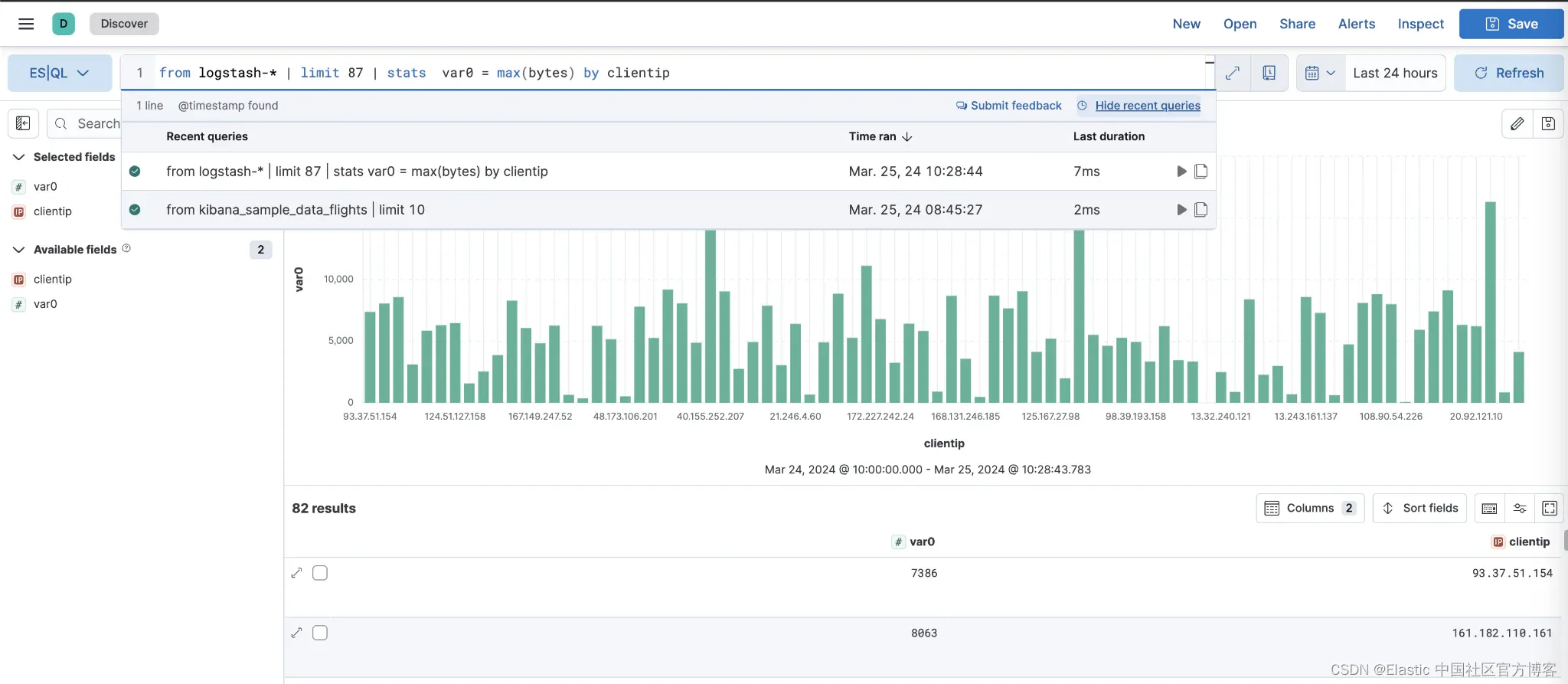
ES|QL 查询历史记录
重复自己可能会令人沮丧,如果你需要重新运行刚才执行的查询,也会同样令人烦恼。现在,借助 ES|QL,你可以通过 ES|QL 查询历史记录快速访问最近的查询。直接在 Kibana Discover、ES|QL 可视化、Kibana 警报或 Kibana 地图中查看、重新运行最近 20 个 ES|QL 查询,以便快速轻松地访问。
混合规划和动态数据缩减
对于大型 Elasticsearch 部署,我们一直在数百个节点以及多达数十万个分片和字段上测试 ES|QL,以确保查询性能随着集群的增长和更多节点的添加而始终保持高性能。
我们扩展了 ES|QL 执行混合规划的能力,以更好地处理数据的动态特性(无论是添加的新字段还是新段)并利用每个节点特有的本地数据模式:
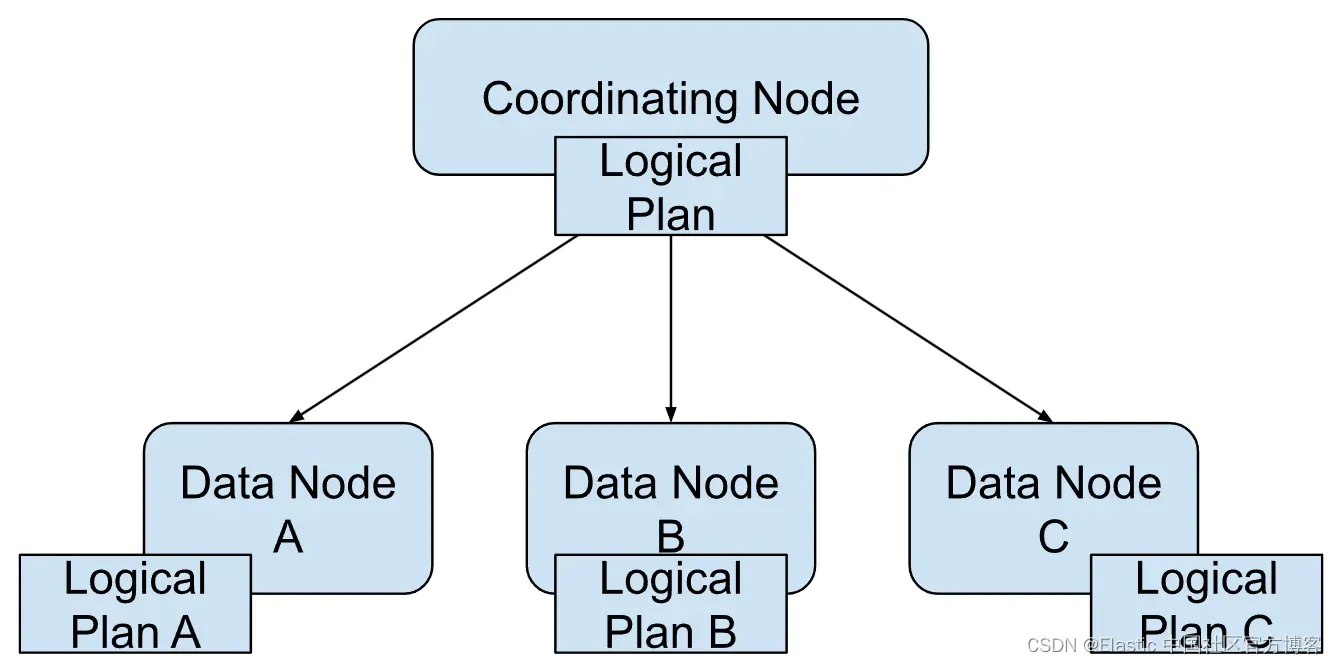
协调节点(接收ES|QL查询并驱动其执行)基于数据的全局视图执行全局规划后,将计划广播到所有可以执行该计划的数据节点。但是,在执行之前,每个节点都会根据每个节点各自的当前存储统计信息在本地更改计划。一个常见的场景是由于模式演变而导致稀疏映射中的早期过滤器评估。
我们正在积极开发一种针对大分片场景的动态数据缩减技术,以最大程度地减少协调器和数据节点之间的 I/O 流量,并减少 Lucene 读取器在查询期间保持打开状态的持续时间。这种方法(包括共享中间结果)在提高跨多个分片的查询效率和运行时间方面显示出巨大的希望。请继续关注未来博客中有关查询执行和架构的更多信息。
异步查询
异步查询使用户能够异步运行长时间运行的 ES|QL 查询。客户不再需要等待结果;相反,他们可以监控进度并在数据准备好后检索数据。通过利用 wait_for_completion_timeout 参数,用户可以定制自己的体验,选择是同步等待还是在指定超时后切换到异步模式。此增强功能不仅提供了更大的灵活性,还优化了资源管理,确保用户的查询过程更顺畅、更高效
长时间运行的 ES|QL 查询可以异步执行,以便客户端可以监视进度并在可用时检索结果,而不是阻塞它们:
POST /_query/async
{"query": """FROM library| STATS MAX(page_count) BY year = BUCKET(release_date, 1 year)| SORT year| LIMIT 5""","wait_for_completion_timeout": "2s"
}通过 wait_for_completion_timeout 客户端可以在切换到异步超时之前选择一个合适的超时来等待结果(并具有同步行为)。
改进的语言和人体工程学
我们简化了 STATS 命令,为数据分析提供更大的灵活性和简单性。以前,用户必须借助额外的 EVAL 命令来进行任意计算以及需要单独的 EVAL 命令的聚合和分组:
FROM company
// use eval to manipulate the grouping column and
// create a conditional for data sanitization
| EVAL g = tenure % 10, trips = COALESCE(trips, 0)
| STATS avg_trips = AVG() BY g
此限制不再是必要的,因为聚合直接在 STATS 命令内接受表达式(并且它们本身也可以组合),从而消除了额外 EVAL 的需要以及由于临时字段而导致的列污染:
FROM company
| STATS avg_trips = AVG(COALESCE(trips, 0)) BY g = tenure %10日期时间单位
ES|QL 现在改进了对日期时间过滤的支持。认识到过滤任务中对日期时间算术的普遍需求,ES|QL 现在支持缩写单位,使查询更加直观和高效。例如,用户现在可以使用 “year”、“month” 和 “month” 等熟悉的缩写轻松指定日期范围。
FROM index
| WHERE @timestamp > now() - 1 year + 1 month + 1 week此更新简化了查询构造,使用户能够更简洁、准确地表达日期时间条件。
字符串文字的隐式数据类型转换
为了最大限度地减少从字符串声明创建专用类型(例如日期)的麻烦,ES|QL 现在使用内置转换函数将字符串常量隐式转换为其目标类型:
FROM index
// convert the declared strings to ip and date-time
| WHERE host_ip in ("127.0.0.1", "::1")AND access_time > "2024-05-15T12:34:56Z"
注意
- 只有常量(或文字)是转换的候选者,列被忽略 - 用户必须显式地使用转换函数。
- 不支持将字符串文字转换为其等价的数字,因为它们可以直接声明;即 “1”+2 会抛出错误,只需将表达式声明为 1+2 即可。
原生 ES|QL 客户端
虽然 ES|QL 通过 _query REST 端点普遍可用,但我们正在努力提供丰富的、固执己见的 API,以便以各种流行语言本地访问 ES|QL。
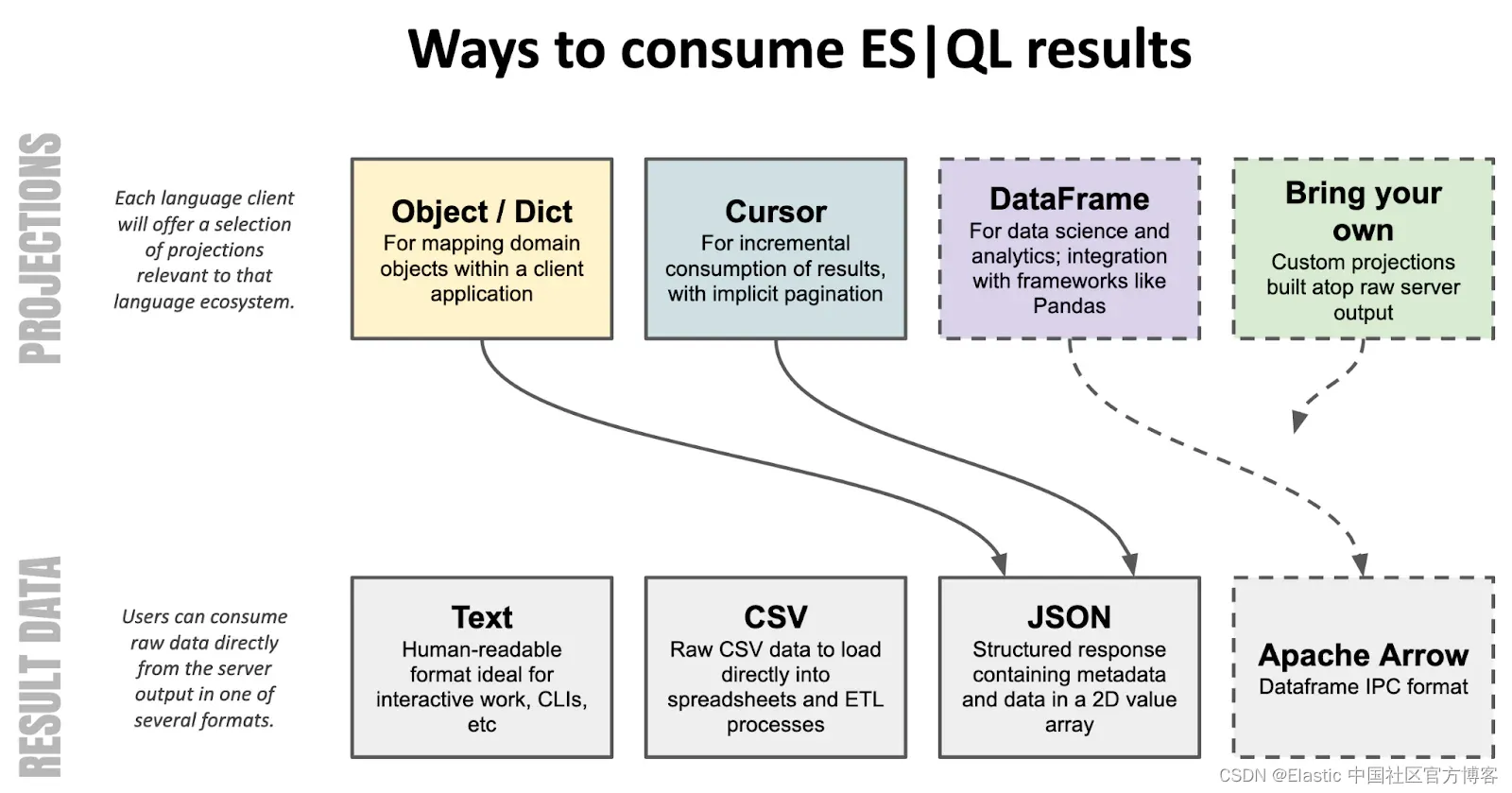
虽然完成上述所有项目需要几个版本,但人们可以通过常规 Elasticsearch 客户端使用 ES|QL,例如,以 Java 或 PHP 对象的形式访问 ES|QL 结果,并在 Python 中将它们作为数据帧进行操作; Jupyter 用户应参阅专用的入门指南笔记本。
自 8.11 首次发布技术预览版以来,ES|QL 一直在 Elasticsearch 生态系统的各个部分发挥作用。例如,可观察性用于使用专门的 AI 助手来简化 OTel 操作。如果我们有更多时间,我们还会提到引入的许多其他函数,例如多值标量字段、地理空间分析(标量函数和聚合函数)和日期时间处理。
技术预览版中跨集群搜索中的 ES|QL
Elasticsearch 中的跨集群搜索使用户能够跨多个 Elasticsearch 集群查询数据,就像数据存储在单个集群中一样,从而提供统一查询、全局洞察和许多其他效率。现在,在技术预览版中,具有跨集群搜索功能的 ES|QL 将其查询能力扩展到跨分布式集群,使用户能够利用 ES|QL 从单个 UI 中查询和分析数据,无论数据位于何处。
虽然 ES|QL 作为基本许可证免费提供,但在跨集群搜索中使用 ES|QL 将需要企业级许可证。要在跨集群搜索中使用 ES|QL,请使用格式为 <remote_cluster_name>:<target> 的 FROM 命令,从远程集群上的 my-index-000001 检索数据。
FROM cluster_one:my-index-000001
| LIMIT 10
展望未来
搜索、嵌入和 RAG
我们很高兴与大家分享一项激动人心的进展:利用 ES|QL 进行高级信息检索,包括全文搜索和 AI/ML 支持的探索。我们的团队致力于使 ES|QL 成为评分、混合排名以及与 Elasticsearch 中的大型语言模型 (LLM) 集成的最佳工具。
该专用命令将简化检索过程,使用户能够对结果进行过滤和评分。在下面的示例中,我们展示了一个综合搜索场景,结合了范围过滤器、快速查询和混合搜索技术。
这是它可能实现的预览,命名为 TBD(Search 或 Retrieval):
// dedicated search command
SEARCH images [// range filter| WHERE date > now() - 1 month// (fast) query for filtering and scoring (returned in _score column)| RANK MATCH "mountain lake"// filter by score| WHERE _score > 0.1// keep only top 100 results | LIMIT 100// perform hybrid search on a user defined image vector using knn | RANK KNN image user_image_vector K 10
]
// break down the results by rating and count the votes
| STATS c = COUNT(votes) BY rating
// return only the top 5 resuls
| LIMIT 5
例如,上面的查询演示了通过评级检索前 5 个最受欢迎的图像,其描述中包含术语 “mountain lake”,类似于用户定义的图像矢量。该引擎在幕后智能地管理过滤器、重新排列查询并应用重新排名策略,确保最佳搜索性能。
这一进步有望彻底改变 Elasticsearch 中的信息检索,为用户提供无与伦比的控制和探索和发现相关内容的效率。
时间序列、指标和 O11y
Elasticsearch 通过时间序列数据流 (TSDS) 提供了专用的指标解决方案,这是一个强大的概念,可以通过使用专门的类型和路由将磁盘存储减少高达 70%。
我们计划在 ES|QL 中充分利用这些功能 - 首先引入专用命令:
METRICS pods load=avg(cpu), writes=max(rate(indexing_requests)) BY pod
| SORT pod
内联统计 - 不减少数据的聚合
ES|QL 中的 STATS 命令对于汇总统计数据非常有用,但当用户想要聚合数据而不丢失其原始上下文时,它通常会带来挑战。例如,如果你希望在每件 T 恤价格旁边显示平均类别价格,传统的聚合方法可能会掩盖原始数据。输入 INLINESTATS:该功能旨在通过执行 “inline - 内联” 统计来解决此问题。
借助 INLINESTATS,用户可以计算每个组内的统计数据,并将结果无缝集成回原始数据集,从而保留原始组的上下文。这一强大的功能增强了 ES|QL 中统计分析的清晰度和深度,使用户能够获得有意义的见解,同时保持数据的完整性。
FROM shop
// compute the average price for each category
// and add it under 'avg_price' column;
// the produced column is now available on all
// entries used to perform the inline grouping
| INLINESTATS avg_price = AVG(price) BY category
现在开始尝试
ES|QL 的推出标志着 Elastic 功能的重大进步,为用户提供了强大而直观的数据查询和分析工具。凭借其简化的语法、强大的功能和创新的特性,ES|QL 为用户打开见解并从数据中获取价值开辟了新途径。无论你是经验丰富的 Elasticsearch 用户还是刚刚入门,ES|QL 都邀请你亲自探索、实验和体验 Elasticsearch 查询语言的强大功能。
请务必查看我们充满示例的演示操场或尝试 Elastic Cloud。已经运行 Elasticsearch 了吗?只需将你的集群升级到 8.14 并尝试一下即可。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一次 Elasticsearch 工程师培训的举办时间!
原文:Elasticsearch piped query language, ES|QL, now generally available — Elastic Search Labs
这篇关于Elasticsearch 管道查询语言 ES|QL 现已正式发布的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







