本文主要是介绍【数据集划分】假如你有超百万条oracle数据库数据(成真版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【数据集划分】假如你有接近百万条oracle数据库数据(成真版)
- 写在最前面
- 小结
- 数据集划分
- 原因
- 注意事项
- 1. 留出法(Hold-out Method)
- 原理
- 算法复杂度
- 代码示例
- Scikit-learn的train_test_split
- 分布式计算框架(如Apache Spark)
- 优化策略回顾
- 优缺点
- 优点
- 缺点
- 2.(适用于少样本,暂不考虑)自助法(Bootstrap Method)
- 3. 交叉验证法(Cross-Validation Method)
- 3.1 (计算成本高,暂不考虑)K-Fold 交叉验证(K-Fold Cross-Validation)
- 3.2 (适用于少样本,计算成本高,暂不考虑)留一法交叉验证(Leave-One-Out Cross-Validation)
- 3.3 分层K-Fold 交叉验证(Stratified K-Fold Cross-Validation)
- 原理
- 算法复杂度
- 代码示例
- 优缺点
- 优点
- 缺点
- 3.4 (适用于类别不平衡,暂不考虑)分组交叉验证(Group K-Fold Cross-Validation)
- 算法复杂度
- Scikit-learn代码示例
- 优缺点
- 优点
- 缺点

写在最前面
大模型,何所谓大?先从大数据开始。
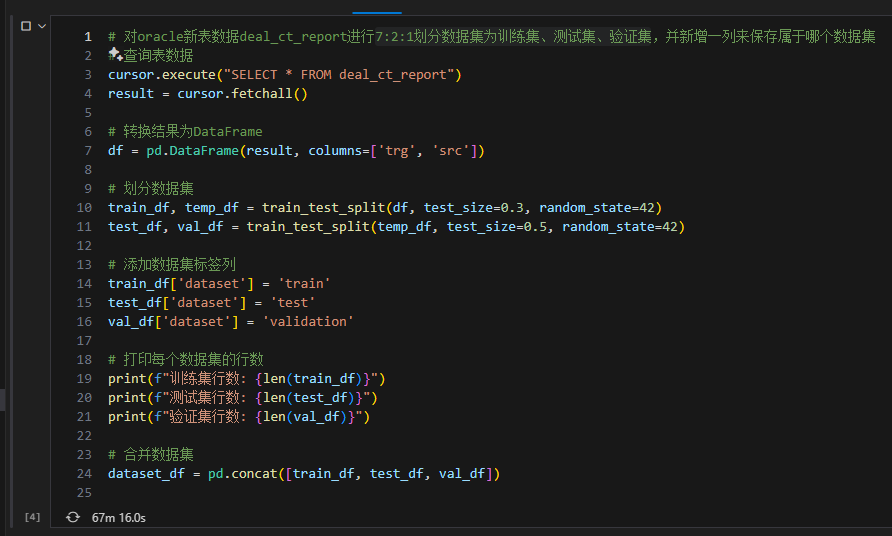
假如你有超百万条oracle数据库数据,那么一直使用的代码:train_df, temp_df = train_test_split(df, test_size=0.3, random_state=42),很可能1h还没划分完数据。
刚开始时,看着电脑忙和,自己闲着,很开心。1h过去后,发现事情好像没有那么简单。于是……
重新学习数据集划分,从时间复杂度角度,重新审视这些机器学习入门知识。
参考:https://blog.csdn.net/Ningbo_JiaYT/article/details/136041904
小结
结论放最前面吧,免得之后不好找。
数据量大,如果类别不平衡,优先考虑分层划分or分组划分。
如果仅考虑时间复杂度,可借鉴留出法的原理,使用分布式计算框架(如Apache Spark)进行优化。
留出法是一种基础的数据集划分方法,通过生成随机数或排序来划分数据集。其时间复杂度主要依赖于数据集的大小,为O(N)。
几种留出法的具体实现及其时间复杂度分析:
- 生成一列随机数[0,1],为每个样本生成一个0到1之间的随机数,根据随机数的大小进行划分。随机数小于0.7的样本划分为训练集,0.7到0.9之间的样本划分为测试集,大于0.9的样本划分为验证集。
算法时间复杂度:O(N)。 - 生成一列随机数,将数据集按随机数从大到小排序,然后根据比例进行划分。前70%的样本划分为训练集,70%到90%之间的样本划分为测试集,剩余的样本划分为验证集。
算法时间复杂度:O(N log N)(由于排序操作)。
数据集划分
数据集划分是机器学习中非常关键的步骤,能直接影响模型的训练效果和泛化能力。它的主要目的是为了评估模型对新数据的泛化能力,即模型在未见过的数据上能表现良好。
数据集通常被划分为三个部分:训练集(Training set)、验证集(Validation set)和测试集(Test set)。
本文中,主要示例7:2:1划分数据集为训练集、测试集、验证集。即将数据集分为70%的训练集、20%的测试集和10%的验证集。
- 训练集用于模型的训练,
- 验证集用于调整模型参数和选择最佳模型,
- 测试集用于最终评估模型的性能。
原因
1.避免过拟合
过拟合(Overfitting)是机器学习和统计学中的常见问题,表现为模型在训练集上的正确率显著高于验证集。通常是模型过于复杂或训练数据量太少,导致捕捉到了数据中的噪声和异常值,而不仅仅是底层的数据分布规律。
2.模型评估
机器学习需要一种可靠的方法来评估模型的预测能力和泛化能力。其中验证集用于初步评估模型的性能,而测试集用于最终评估模型的泛化能力(即模拟真实世界的应用场景)。
3.模型选择和调参
训练集和验证集能帮助研究者在机器学习项目的开发过程中选择最佳模型和调整参数,以提高模型的性能。
注意事项
1.数据泄露
在划分数据集时,要确保测试集(有时也包括验证集)中的信息在训练阶段对模型完全不可见,避免数据泄露导致评估结果不准确。
2.数据不平衡
对于不平衡的数据集,需要特别注意采用分层抽样等技术,确保每个类别的样本在各个子集中都有合理的分布。
3.数据的代表性
数据集划分后,需要确保训练集、验证集和测试集在统计特性上都能代表整个数据集,避免由于数据划分导致的偏差。
1. 留出法(Hold-out Method)
原理,算法复杂度,代码,优缺点。
原理
留出法(Hold-out Method)是一种基础的数据集划分方法,通过将数据集分成多个互斥的子集,以便在模型训练和评估中使用。具体到7:2:1划分,即将数据集分为70%的训练集、20%的测试集和10%的验证集。训练集用于模型的训练,验证集用于调整模型参数和选择最佳模型,测试集用于最终评估模型的性能。
算法复杂度
留出法的时间复杂度主要依赖于数据集的大小。如果数据集包含N条记录,则数据划分操作的时间复杂度为O(N)。
然而,当N非常大时,这种线性时间复杂度仍然可能导致不可接受的延迟。
代码示例
Scikit-learn的train_test_split
下面是使用Scikit-learn进行7:2:1数据集划分的示例代码:
import pandas as pd
from sklearn.model_selection import train_test_split# 假设 df 是一个包含数据集的 DataFrame
df = pd.read_csv('path/to/your/data.csv')# 首先按7:3的比例将数据集划分为训练集和临时集
train_df, temp_df = train_test_split(df, test_size=0.3, random_state=42)# 然后将临时集按2:1的比例划分为测试集和验证集
test_df, val_df = train_test_split(temp_df, test_size=1/3, random_state=42)# 输出划分后的数据集大小
print(f'Training set size: {train_df.shape[0]}')
print(f'Test set size: {test_df.shape[0]}')
print(f'Validation set size: {val_df.shape[0]}')
分布式计算框架(如Apache Spark)
对于大规模数据集,可以使用分布式计算框架(如Apache Spark)进行数据集的7:2:1划分:
from pyspark.sql import SparkSession
from pyspark.sql.functions import rand# 初始化Spark会话
spark = SparkSession.builder.appName("DataSplit").getOrCreate()# 读取数据
df = spark.read.csv("path/to/your/data.csv", header=True, inferSchema=True)# 添加随机列用于划分
df = df.withColumn("rand", rand())# 按7:3划分为训练集和临时集
train_df = df.where("rand <= 0.7").drop("rand")
temp_df = df.where("rand > 0.7").drop("rand")# 再将临时集按2:1划分为测试集和验证集
temp_df = temp_df.withColumn("rand", rand())
test_df = temp_df.where("rand <= 2/3").drop("rand")
val_df = temp_df.where("rand > 2/3").drop("rand")# 转换为Pandas数据框
train_df = train_df.toPandas()
test_df = test_df.toPandas()
val_df = val_df.toPandas()# 输出划分后的数据集大小
print(f'Training set size: {train_df.shape[0]}')
print(f'Test set size: {test_df.shape[0]}')
print(f'Validation set size: {val_df.shape[0]}')
优化策略回顾
- 分布式计算:利用分布式计算框架,如Apache Spark,能够将任务分散到多个节点上并行执行,显著缩短处理时间。
- 增量式处理:将数据集划分为若干小块,逐块进行训练和验证,减少内存消耗,提高处理效率。
- 采样技术:在大数据集中随机抽取子集进行训练和验证,尽管可能会牺牲一定的精度,但能显著提高计算速度。
优缺点
优点
- 简单易用:留出法实现简单,易于理解和使用。
- 计算速度快:对于中小规模的数据集,留出法的计算速度非常快,能快速得到训练集、测试集和验证集。
- 防止过拟合:验证集可以帮助在训练过程中监控模型性能,防止过拟合。
- 更全面的模型评估:通过引入验证集,可以在训练过程中实时评估模型性能,帮助选择最佳的模型超参数。
缺点
- 数据浪费:(数据多,不在乎)部分数据仅用于验证和测试,未参与模型训练,可能导致数据集使用效率不高,尤其在数据集较小时尤为明显。
- 结果不稳定:由于数据集划分具有随机性,不同的划分可能导致不同的模型性能评估结果。
2.(适用于少样本,暂不考虑)自助法(Bootstrap Method)
一种有放回的抽样方法,用于从原始数据集中生成多个训练集的技术,适用于样本量不足时的模型评估。
在自助法中,我们从原始数据集中随机选择一个样本加入到训练集中,然后再把这个样本放回原始数据集,允许它被再次选中。
这个过程重复n次,n是原始数据集中的样本数量。
这样,一些样本在训练集中会被重复选择,而有些则可能一次也不被选中。
未被选中的样本通常用作测试集。
优点:
- 在数据量有限的情况下,自助法可以有效地增加训练数据的多样性。
- 对于小样本数据集,自助法可以提供更加稳定和准确的模型评估。
- 可以用来估计样本的分布和参数的置信区间。
缺点:
- 由于采样是有放回的,可能导致训练集中的某些样本被多次选择,而有些样本则从未被选择,这可能会引入额外的方差。
- 对于足够大的数据集,自助法可能不如其他方法,如 K-Fold 交叉验证,因为重复的样本可能导致评估效果不是很好。
3. 交叉验证法(Cross-Validation Method)
通过将数据集分成多个小子集,反复地进行训练和验证过程,以此来减少评估结果因数据划分方式不同而带来的偶然性和不确定性。
3.1 (计算成本高,暂不考虑)K-Fold 交叉验证(K-Fold Cross-Validation)
把数据集平均划分成 K个大小相等的子集,对于每一次验证,选取其中一个子集作为验证集,而其余的 K-1个子集合并作为训练集。
这个过程会重复K次,每次选择不同的子集作为验证集。
最后,通常取这K次验证结果的平均值作为最终的性能评估。
适用于数据集不是非常大的情况。
优点:减少了评估结果因数据划分不同而产生的偶然性,提高了评估的准确性和稳定性。
缺点:计算成本高,尤其是当K值较大或数据集较大时。
3.2 (适用于少样本,计算成本高,暂不考虑)留一法交叉验证(Leave-One-Out Cross-Validation)
留一法是 K-Fold 交叉验证的一个特例,其中K等于样本总数。这意味着每次只留下一个样本作为验证集,其余的样本作为训练集。
这个过程重复进行,直到每个样本都被用作过一次验证集。
优点:可以最大限度地利用数据,每次训练都使用了几乎所有的样本,这在样本量较少时尤其有价值。
缺点:计算成本非常高,尤其是对于大数据集来说,几乎是不可行的。
3.3 分层K-Fold 交叉验证(Stratified K-Fold Cross-Validation)
原理
分层K-Fold交叉验证(Stratified K-Fold Cross-Validation)是对K-Fold交叉验证的一种改进,特别适用于处理类别不平衡的数据集。
在这种方法中,每次划分数据时都会保持每个类别的样本比例,确保在每个训练集和验证集中各类的比例与整个数据集中的比例大致相同。
这样可以避免因类别不平衡而导致的模型偏差问题,提高模型的泛化能力。
算法复杂度
分层K-Fold交叉验证的时间复杂度与K-Fold交叉验证相同,为O(KN),其中N是数据集的大小,K是交叉验证的折数。
虽然在实现上稍微复杂一些,但对大多数数据集来说,额外的复杂性和计算开销是可以接受的。
代码示例
下面是一个使用Scikit-learn进行分层K-Fold交叉验证的示例代码:
import pandas as pd
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 假设 df 是一个包含数据集的 DataFrame,target 是目标变量
df = pd.read_csv('path/to/your/data.csv')
X = df.drop(columns=['target'])
y = df['target']# 创建 StratifiedKFold 对象
skf = StratifiedKFold(n_splits=5)# 进行分层交叉验证
for train_index, test_index in skf.split(X, y):X_train, X_test = X.iloc[train_index], X.iloc[test_index]y_train, y_test = y.iloc[train_index], y.iloc[test_index]# 训练模型model = RandomForestClassifier(random_state=42)model.fit(X_train, y_train)# 预测并评估y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print(f'Fold Accuracy: {accuracy}')
优缺点
优点
- 保持类别比例:对于分类问题,分层K-Fold交叉验证能够保持每个类别在训练集和验证集中的比例与整个数据集中的比例相同,有助于处理类别不平衡的问题。
- 提高模型泛化能力:通过保持类别比例,模型能够更好地泛化到未见的数据,提高评估结果的可靠性。
- 减少偏差:避免因类别不平衡导致的模型偏差,使得评估结果更加稳定和准确。
缺点
- 实现复杂性:分层K-Fold交叉验证的实现相对复杂,需要根据数据的具体类别分布进行样本的分层抽样。
- 计算开销:尽管时间复杂度与K-Fold交叉验证相同,但由于需要进行分层抽样,计算开销可能略有增加。
分层K-Fold交叉验证是一种适用于处理类别不平衡数据集的有效方法。通过保持类别比例,它能够提高模型的泛化能力和评估结果的可靠性。尽管实现相对复杂,且计算开销略有增加,但其优点使得它在处理分类问题时非常有价值。
3.4 (适用于类别不平衡,暂不考虑)分组交叉验证(Group K-Fold Cross-Validation)
分组交叉验证是一种处理具有明显组结构数据的交叉验证策略。
其核心思想是确保来自同一组的数据在分割过程中不会被分散到不同的训练集或测试集中。
这种方法特别适用于数据中存在自然分组的情况,例如医学领域按病人分组的数据集。
具体来说,假设数据集中有若干个组,每个组包含多个样本。在分组交叉验证中,数据不是随机分成K个子集,而是根据组的标识来分。整个数据集被分为K个子集,但划分的依据是组而不是单个样本。每次迭代中,选定的一个或多个组整体作为测试集,其余的组作为训练集。这个过程重复进行,直到每个组都有机会作为测试集。
算法复杂度
分组交叉验证的时间复杂度主要取决于数据集的大小和组的数量。如果数据集包含N个样本和M个组,则每次划分和训练的时间复杂度为O(N)。整体复杂度也与交叉验证的次数K有关,即O(KN)。尽管整体复杂度高于简单的留出法,但通过合理选择K值和组的划分,可以有效进行模型评估。
Scikit-learn代码示例
下面是一个使用Scikit-learn进行分组交叉验证的示例代码:
import pandas as pd
from sklearn.model_selection import GroupKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 假设 df 是一个包含数据集的 DataFrame,group_col 是表示组的列名,target 是目标变量
df = pd.read_csv('path/to/your/data.csv')
X = df.drop(columns=['target', 'group_col'])
y = df['target']
groups = df['group_col']# 创建 GroupKFold 对象
gkf = GroupKFold(n_splits=5)# 进行分组交叉验证
for train_index, test_index in gkf.split(X, y, groups):X_train, X_test = X.iloc[train_index], X.iloc[test_index]y_train, y_test = y.iloc[train_index], y.iloc[test_index]# 训练模型model = RandomForestClassifier(random_state=42)model.fit(X_train, y_train)# 预测并评估y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print(f'Fold Accuracy: {accuracy}')
优缺点
优点
- 避免数据泄露:确保模型评估不会受到来自同一组但不同样本的数据相似性的影响,从而更好地模拟真实场景。
- 更准确的泛化能力评估:通过对未见过的组进行预测,能够更准确地评估模型对新数据的处理能力。
- 减少过拟合风险:由于整个组作为一个单位进行划分,模型无法通过过拟合个别样本来提高评估性能。
缺点
- 实现复杂性:需要有明确的组标识,且在数据划分时要根据这些组标识进行操作,代码实现相对复杂。
- 可能的样本不均衡:如果各组的大小差异很大,可能导致训练和测试集的样本分布不均,从而影响模型的评估结果。
- 计算开销:由于需要进行多次模型训练和评估,计算开销相对较大,尤其在大数据集的情况下。
分组交叉验证是一种有效的模型评估方法,特别适用于具有自然分组的数据集。尽管其实现较为复杂,且可能导致样本不均衡问题,但通过合理选择组划分策略,可以有效评估模型的泛化能力,避免数据泄露,减少过拟合风险。
欢迎大家添加好友交流。

这篇关于【数据集划分】假如你有超百万条oracle数据库数据(成真版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





