本文主要是介绍内涵:CVPR2019之GCNet解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
non-local论文地址
non-local代码地址
gcnet论文地址
gcnet代码地址
senet论文地址
senet代码地址
这篇文章是发表于CVPR2019上的一篇文章,文章花了相当多的文笔放在另外两篇文章Non-local(CVPR2018)和Senet(CVPR2018)之上。而且感情基调较为明显,较为质疑 Non-local的做法,中性略带赞赏性的评价Senet。
这篇文章的思路来源于:作者发现,对于一副图片,不同的query positions 通过 non-local结构获得的全局上下文信息几乎一样。因此作者“质疑”这样“费力”(复杂的网络结构、计算量、参数量)的获得query-specific的全局上下文信息意义不大。因此提出了一个query-independent的Simpled NL(snl)结构。并且通过实验证明,简化之后,参数量、计算量下来了,性能却outperforms Non-local。同时作者还提出,本文提出的gc block结构和Senet都属于一种"三步骤"通用框架:1、全局上下文建模;2、channel-wise 依赖关系转换;3、特征融合。并认为Senet是这种通用框架的实例对象,而GcNet则是一种性能更佳的实例对象。
无论是non-local还是本文所提出的gcnet都属于"long-range dependency “。它们的目的都是尽可能从"global"的角度来理解图像,而不至于陷入盲人摸象的地步。单靠传统的卷积层是无法自己做到这一点的(或者说做的不够好),原因在于一个卷积操作是对一个"local neighborhood"的pixel 关系进行建模。虽然可以通过不断的加深网络,来达到网络后半部分的神经元的感受野变大,达到一种不那么“local”的效果。但这种粗暴的加深网络的做,有如下三个缺点:
1、不够精巧,参数量、计算量粗暴拼凑出来的。
2、网络越深,优化难度越大。
3、不那么"local"并不代表全局,有最大距离的限制。
对上面第三点的理解可以为:在网络的后半部分,feature map右下角的cell,感受野可能扩大了,但可能还是始终无法获得原图片上左上角的信息(因为卷积操作最大距离的限制)。
与之对应的,一个理想的神经网络应该是:不要那么深,让用户优化的太困难;网络涉及的精巧一点,最好较少的参数量达到原始网络结构的性能;真正的做到全局,没有最大距离的限制。
从最近阅读的几篇论文来看,精巧或者说light的网络block单元是现在研究人员追求的一个目标,毕竟现在深度学习领域感觉有点进入瓶颈期的意思,很多论文现在都是在计算量下降的情况下,性能提升0.x个点,这种操作了。而全局则是一个相对较为火爆的切入点之一。从non-local的名字就可以看出,它也是从’global’的角度切入。对于每一个query position,计算该query position与图中其他点之间的关系来提取该点的特征。
然而,作者对non-local的attention map进行可视化后发现不同的query point对应的attention map几乎一样如,图1所示:
图1
既然attention map与具体点的位置无关,一个最直观的反应是,那就不要每一个点单独算一个attention map了。用另外一种同样能够获得全局信息,但一个feature map上的点共用的特征吧。基于此,本文作者提出了简化版的NL(snl)。从网络结构上可以看是如图2的变化:

图2
一个直观的感觉是block结构确实简化了。实际运算的变化,可以见图3中的公式变化。关键部分在于+号后面的变化。Nonlocal+号后面的内容与xi有关,因此每一个点i,需要计算一次。而snl的表达公式+号后面的内容已与xi无关,也即计算一次,然后大家公用,也映证了上文所讲的query-independent。
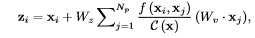
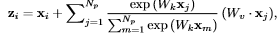 图3
图3
到目前为止,该网络结构还只能称之为snl。作者对snl做了一些结构的优化,就变成了最终的GC block。主要有两点:
1、对于nsl模块中右下角的1x1卷积,它的参数量是CINCOUT。例如,输入通道是2048,输出通道是2048。则参数量就是4000000。这样会导致该模块不够轻量级,无法插入网络的任意位置。作者是通过一个bottleneck结构来替换。这样参数量可以从2cin*cout/r(r通常设置为16)。
2、two-level bottleneck 的引入增加了网路优化的难度,因此作者引入了layer norm(作者论文中实验讲,这一加入还是蛮有效的,0.x个点吧)。
到这里作者发现gcnet的组成已经和senet很像了(如图4所示)。

图4
这时,作者提出了一个“Global context modeling framework”来抽象这一类结构(也即博客开头提到的三步骤结构)。如图5所示
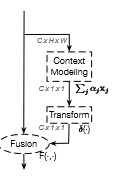
图5
毕竟作者是投稿CVPR这样的顶会,还是要有创新性的。作者在论文中也总结了自己提出的gcnet与senet网络之间的差异:
1、senet 在融合的时候使用的是rescale,而gcnet使用的是sum。因此"SE recalibrate the importance of channels but inadequately models long-range dependency"。
2、Layer-norm的使用。
3、SE中用于提取全局信息的global pooling 是GCNET global attention pooling的一种特例。
4、在有就是性能上,outferms senet网络。
思考:
1、自己读下来non-local和gcnet。感觉gcnet虽然批判non-local花费了很大的笔墨。但我自己感觉,创新性上,gcnet有限,暂时理解的是简单的调整一下网络拼装结构,然后总结一个三步框架。感觉用作实习生工作的阶段性汇报,可以,但中一篇cvpr顶会,暂时还没感受到它的太大的价值。相比较而言,non-local,思想上的query-special的思想和实现,对自己的启发感觉更大。
附录:由于这篇文章涉及到比较多的non-local。因此non-local就暂时不准备单独开一篇博客了,附上对于理解Non-local自己感觉比较重要的一段论文和图。


这篇关于内涵:CVPR2019之GCNet解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








