本文主要是介绍内涵:高性能网络之shufflenet v2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.概述
这篇文章是高性能神经网络的经典论文之一shufflenet-v2, 发表于18年7月份,由旷视的马宁宁,孙坚等人提出。21年的RepVgg论文中的一些理论基础很多也是来自于这篇文章。这篇文章层层递进的可以总结为如下这样几个问题:
- 高性能网络在做什么?
- 之前高性能网络设计是怎么做的?这样设计的依据目标函数是否存在问题?
- 高性能网络的真实的设计目标是什么?依据设计目标,进行对比实验,可以得到一些有用的怎样的设计准则?
- 依据提出的设计准则,设计了一个网络,效果是否可以达到预期?
2. 高效能网络
如果是学术竞赛,accuracy必定是越高越好。但在实际的业务场景下,算法人员要考虑的除了accuracy之外,还包括efficiency. 其中对于efficiency 的范畴包括网络运行所需要 的耗时、内存、带宽等实际算法工业化落地所要面对的各种实际因素。高效网络,可以理解为在精度不降低的情况下,上述实际参数越低,则越高效率。而在这几个参数中,耗时可能是用户实际更加关注的。
首先要保证精度基本不掉点。就要明确精度来源于哪里。我们能想到的可能包括以下3点:
- 网络深度: 网络越深,非线性越强,
- 网络宽度:也即具体到一个卷积层中卷积的通道数,通道数目越多,特征越丰富
- 特征之间的信息交流:普通卷积操作所固有的
但上述精度的获得事实上是由算法的计算复杂度所带来的,也就是我们通常所讲的计算量Flops(float point operations),它大概可以表示为sum(M * N * K * K * CIN * COUT), sum是代表一个网络有几层,这个网络的计算量就有几个这样的通式相加而成。可以看到其实计算量与精度的来源是一个互为寄生的关系。
- 网络深度代表的是sum的层数,层数多了,但计算量势必也会变大,因此会变得低效。
- 网络宽度对应的是COUT, 特征丰富了,计算量识别也会变大, 因此会变得低效。
- 特征之间的信息交流对应的是K和CIN, 相比较于以上两点,这点会比较含糊。
因此高效网络的设计一般都是针对这一点进行改进。比如包括常见的:用3 * 3卷积代替7 * 7 卷积,来降低参数量;用group卷积来为CIN除以一个g因子,来降低计算量;Depthwise 卷积和Pointwise 卷积, 来降低计算量 。
shfflenet v1和mobilenet v2的核心思想都可以归结于group卷积和Depthwise卷积。这也是shufflenetv2之前高效网络的大概设计思路。
3. 如何设计轻量级网络
shufflenet v2首先指出以往的高效网络的设计在根上就是错的。如果讲高效网络设计作为一个优化问题的话,之前研究学者的优化目标是 m i n ( F l o p s ) min({Flops}) min(Flops)优化条件是尽可能保持网络的深度、广度不下降,特征之间的信息交流不要少。但一系列异常的现象不断的出现:
异常现象1:MobileNet v2和NASNET-A的计算量相当,但前者要远远快于后者。
异常现象2 更大范围的将经典的高效网络计算量和运行速度列举出来。如下图所示(先暂时不要看下图中的Shufflenet V2的点):
如果我们将Xception、ShuffleNet v1、MobileNet v2的计算量限制的一样,如图c所示,在主流GPU上,其速度却千差万别。
因此将Flops作为高效网络设计的目标变量,设计出来的网络极有可能不具有实际的使用价值。另外对比图c和图d, 在GPU平台上运行耗时可能相差较大,但在ARM上却没有那么大的差异。
因此,作者认为首先需要明确两点:
- 我们的目标函数的体现以FLOP作为理论目标函数是有问题。其直接的物理指标应该是耗时(或者延时性),但我们在实际实验之前,必须要有理论的目标函数,否则都是马后炮,这个理论的目标函数应该是大概f(Flops)的一个东西。
- 网络是否高效的分析,必须要建立在指定硬件平台的基础上,因为一个网络设计在GPU上体现了很大的优势,但在ARM平台上却体现不出来。(一个比较直观的解释之一是,不同的平台加速算子的实现以及优化程度不同,比如cudnn可能对3 x 3卷积操作进行了特别的操作)。
因此,接下来的思路就可以比较顺的梳理为:找到f(Flops)------->梳理处规则性的准则------->设计除高效的网络。
3.1 找到f(Flops)
Flops之所以不等同于耗时的高低,原因在于Flops的公式可以看出,它仅仅是对卷积层的操作数的公式。神经网络除此之外,还包括data io, data shuffle 和 elemetwise 操作(例如addTensor和Relu操作等)。
很容易的,把神经网络的所有可能耗时的操作统计全的话,就可统计出如下图所示的耗时分布(以shufflenet v1和mobilenet v2为例)。

可以看到,对于GPU来讲,卷积操作仅占整体耗时分布的50%左右(可以认为对应的就是Flops算出来的大小),这也就难怪,图c中,如果保持Flops一致,实际耗时千差万别。但对于ARM平台,卷积操作几乎占据90%左右,对应图d中,Flops基本和实际耗时一致。而shufflenet v2就是针对图中Data和Elemwise两大块进行分析。
3.2 四条设计准则
3.2.1 G1: CIN==COUT
来看证明过程:以1x1卷积为例子,作者引入了一个MAC(memory access cost)的概念来描述Data耗时,它的计算公式为:hw(CIN+COUT)+CIN * COUT。计算量B的公式为hw Cin Cout如果计算量B固定的话,则MAC满足如下的不等式子,

如果我们希望MAC最小,则测试可得Cin==Cout.推导过程见我的手抄版本。事实上对于k*k的卷积也是同样的结论,不再重复证明。

3.2.2 G2: group卷积的g并不是越大越好。
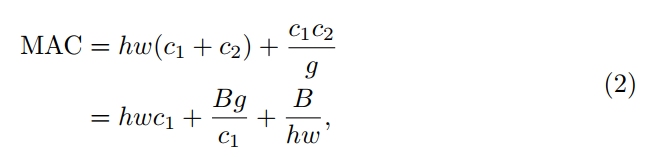
如果以1x1卷积的MAC为例可以写出上面的式子。可以看到如果以g为变量,MAC会随着g的增大而增大。因此group的卷积并不是越大越好。但这并不是讲group卷积就没有价值了,它仍旧是可以使用的。只不过我们假设它的使用场景:如果一个算法人员,我们使用了g卷积,他希望借此可以将输出通道的数量扩大g倍,来达到相同运行速度的情形下,获得一个更好的精度效果。他可能会失望,因为根据G2,此时网络的速度会变慢。但其实他可以将输出通道的数量扩大的倍数不要那么的大,来获得一个计算量耗时+MAC耗时整体不变,来达到提升精度的效果。这其实就涉及到trade-off了。
3.2.3 G3: fragmented operators影响网络的并行度
fragmented operators也就是网络中独立存在的一个卷积或者池化单元。为了确认对fragmented operators概念理解的没有错,可以通过以下几个模块进行以下验证。

接下来作者,做了一个实验来验证fragment的数量(以及并行和串行结构)对运行耗时的影响,如下表所示,

保证FLOPS一致的前提下,fragment的数量越多,耗时越长,对于4:1的fragment数量,耗时大概会达到3:1的量级。但下表也有以下两点信息需要注意:对于非并行芯片,CPU来讲,这种fragment的数量似乎并没有太大影响。对于GPU来讲,当通道数目上升之后,fragment的数量对运行耗时的影响似乎在变小。所以一般部署的时候,大部分公司都会将卷积操作于BN操作进行合并,来减少fragment的数量。再有就是2021年的repVGG论文,的一个核心操作就是将多个卷积进行合并操作。但想说的是G3的实验貌似没有控制MAC的控制变量,若fragment的数量上升,此时MAC其实也在增加,因此增加的耗时可能是由MAC引起的。
3.2.4 G4:Elementwise操作是不可忽略的
Elementwise操作狭义的来讲包括Relu、Addtensor、Addbias操作,广义的来讲,一切具有高的MAC/FLOPS比的操作都可以纳入到这部分,比如包括Deepwise 卷积。在之前的高效能网络中,这部分由于其Flops低,极易被忽略。如下图实验结果所示:

3.3 总结与讨论
总结下来就是4条结论。
- 使用balanced的卷积;
- 小心使用group卷积的代价。
- 减少fragmentation度。
- 减少element-wise操作。
之前的一些轻量级网络犯得错误包括:shufflenetv1过度依赖group卷积,违背了G2; 使用bottleneck-like结构违背了G1。MobileNet v2则是因为inverted bottleneck结构违背了G1.使用了厚的卷积特征违背了准则G4.(薄的eletment-wise耗时约占四分之一,厚的eletment-wise耗时约占六分之一)自动生成的结构则严重的违背了准则G3。
4. 实验结果
接下来让我们看一看,shufflent v2的网络结构。

其中c和d是shufflenet v2的网络结构, a和b是shufflenetv1的网络结构。结构c是本文的重点或者说创新点,首先通过引入channel split结构,将Group卷积消除掉,符合规则2.其次无论是右分支还是整体uint分支都满足cin==cout,符合规则1. 第三点是将add操作替换为Concat操作(是否可以通过指针直接得到),符合规则4. 图d则是在图b的基础上进行了少许改动。
如下图所示是网络结构的具体堆砌方式。大概就是c结构和d结构进行混合,d结构负责拉升通道数量,增加特征的丰富性,提升精度;c结构用来体现本文高效能网络的优势。所以通道数量的变化是24–》48–》96》192而不是我们之前遇到的2^n方式的增长形式。

最后,来看结果:首先是经典高效网络之间,计算量、速度和准确率之间的比较。

shufllenet v2加上se模块,依旧可以提升0.5个百分点。
shufflenet v2有与大网络抗衡的能力。与resnet-50性能比,与SENet网络性能比。

用在检测主干上,也是最好的。

4. 个人感想
repVGG的这篇论文其实的先导文章就是shufflenetv2。v2通过实际定量的实验,推导除了一些准则还是很有意义的。并让我们知道了影响速度的因素除了flops还有mac,并行度。但也会有一些瑕疵,总感觉没有将flops和mac以及并行度放到一个维度上,感觉是三个维度空间上的因素。
这篇关于内涵:高性能网络之shufflenet v2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




