本文主要是介绍bbbike下载OSM路网数据后使用GraphHopper离线进行路径规划,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、bbbike下载OSM路网数据

GraphHopper是一种快速且内存有效的Java导航引擎,默认使用OSM和GTFS数据,也可导入其他的数据源。支持CH(Contraction Hierarchies)、A*、Dijkstra算法。
1、搭建之前要保证jdk安装完成,且完成环境变量配置。网上有一大推的教程,自行进行校验安装;
2、下载Graphhopper( https://github.com/graphhopper/graphhopper)master分支代码

解压文件,注意这里尽量不要解压到具有中文名称的路径中,否则可能会导致服务无法正常启动情况;
3、到OSM上下载地图数据。
下载完成后,将文件放在根目录文件中并修改config.yml

4、运行命令(可通过git)
#先进入到graphhopper目录下,再执行以下语句./graphhopper.sh -a web -i china-latest.osm.pbf#china-latest.osm.pdf是下载的路图
5、运行效果:

6、访问如下:(纬度在前、经度在后)

二、规划路径
URL:
url: "http://127.0.0.1:8989"+ "/route?point=" + lng11 + "%2C" + lat11 + "&point=" + lng21 + "%2C" + lat21 + "&type=json&locale=zh-CN&key=&elevation=false&profile=car&algorithm=alternative_route",三、效果
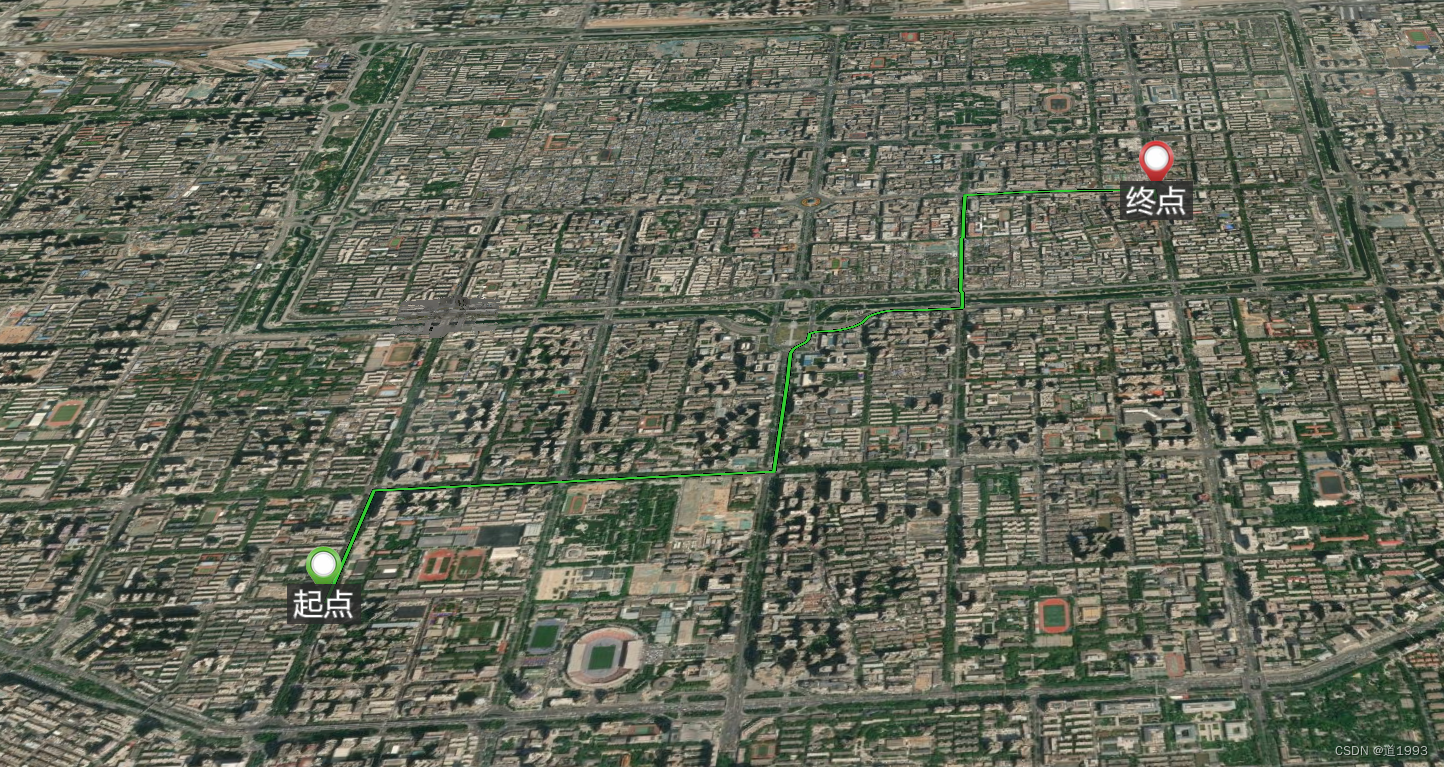
这篇关于bbbike下载OSM路网数据后使用GraphHopper离线进行路径规划的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




