本文主要是介绍揭秘GPU技术新趋势:从虚拟化到池化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

从GPU虚拟化到池化
大模型兴起加剧GPU算力需求,企业面临GPU资源有限且利用率不高的挑战。为打破这一瓶颈,实现GPU算力资源均衡与国产化替代,GPU算力池化成为关键。本文深入探讨GPU设备虚拟化途径、共享方案及云原生实现,旨在优化资源利用,推动算力革命。
汪照辉,中国银河证券杰出架构师,深耕容器云、微服务、DevOps等数据转型技术,见解独到。他倡导的“平台融合”观点广受认可,并发表多篇技术文章,涵盖容器平台、微服务、DevOps、数字化转型等领域,展现了其深厚的软件规划与设计能力,备受业界瞩目。
智能化应用如人脸识别、语音识别、文本识别、智能推荐、智能客服、智能风控等已广泛应用于各行各业,这些应用被称为判定式AI的范畴,通常和特定的业务场景相绑定,因此在使用GPU(Graphics Processing Unit)卡的时候也通常各自独立,未考虑业务间GPU共享能力,至多实现vGPU 虚拟化切分,从而一张物理GPU卡虚拟出多张vGPU,可以运行多个判定式AI 应用。
随着大模型的兴起,对GPU算力的需求越来越多,而当前现实情况使企业往往受限于有限的GPU卡资源,难以支撑众多的业务需求,同时由于业务特性等,即便进行了虚拟化,往往难以充分使用GPU卡资源或持续使用资源,从而也造成有限的卡资源也无法有效利用。
从GPU虚拟化需求到池化需求
智能化应用数量的增长对GPU算力资源的需求越来越多。NVIDIA虽然提供了GPU虚拟化和多GPU实例切分方案等,依然无法满足自由定义虚拟GPU和整个企业GPU资源的共享复用需求。TensorFlow、Pytorch等智能化应用框架开发的应用往往会独占一张GPU整卡(AntMan框架是为共享的形式设计的),从而使GPU卡短缺,另一方面,大部分应用却只使用卡的一小部分资源,例如身份证识别、票据识别、语音识别、投研分析等推理场景,这些场景GPU卡的利用率都比较低,没有业务请求时利用率甚至是0%,有算力却受限于卡的有限数量。单个推理场景占用一张卡造成很大浪费,和卡数量不足形成矛盾,
因此,算力切分是目前很多场景的基本需求。再者,往往受限于组织架构等因素,GPU由各团队自行采购和使用,算力资源形成孤岛,分布不均衡,有的团队GPU资源空闲,有团队无卡可用。
针对GPU算力资源不均及国产化需求,我们亟需实现算力池化。此举旨在平衡在线与离线、业务高峰与低峰的资源需求,同时满足训练、推理及开发、测试、生产环境的多样化需求。通过统一管理和调度复用,实现GPU资源的切分、聚合、超分、远程调用及热迁移,大幅提升资源利用率,满足当前迫切的GPU算力池化需求。
GPU设备虚拟化路线
GPU设备虚拟化有几种可行方案。
PCIe直通模式(pGPU)即直接挂载物理主机的整块GPU到虚拟机,然而它属于独占模式,无法实现GPU的虚拟化切分,无法支持多应用共享,因此其实际应用价值有限。
第二是采用SR-IOV技术,允许一个PCIe设备在多个虚拟机之间共享,同时保持较高性能。通过SR-IOV在物理GPU设备上创建多个虚拟 vGPU来实现的,每个虚拟vGPU可以被分配给一个虚拟机,让虚拟机直接访问和控制这些虚拟功能,从而实现高效的I/O虚拟化。NVIDIA早期的vGPU就是这样的实现,不过NVIDIA vGPU需要额外的license,额外增加了成本。SR-IOV虽然实现了1:N的能力,但其灵活性比较差,难以更细粒度的分割和调度。
MPT,即受控的直通模式,乃PCIe设备虚拟化的先进方案。它融合1:N灵活性、卓越性能与功能完整性,但逻辑上类似内核态的device-model。然而,由于厂商通常不公开硬件编程接口,MPT可能带来厂商依赖。尽管如此,其独特的优势仍使其成为虚拟化领域的重要选择。
API转发模式备受青睐,其层次结构涵盖CUDA API(截获CUDA请求,用户态)、GPU Driver API(截取驱动层请求,内核态)和设备硬件层API。设备硬件层API获取难度较大,因此当前市场主流为CUDA API与GPU卡驱动Driver API转发模式。这两种模式分别对应用户态和内核态,确保AI应用的高效调用与数据传输。
AI开发框架常与GPU卡紧密集成,如华为CANN、海光DTK、英伟达TensorFlow和Pytorch等。这些框架不仅支持AI应用开发,还能在框架层实现转发,极大便利了AI应用的迁移与部署,为开发者提供了高效灵活的开发环境。
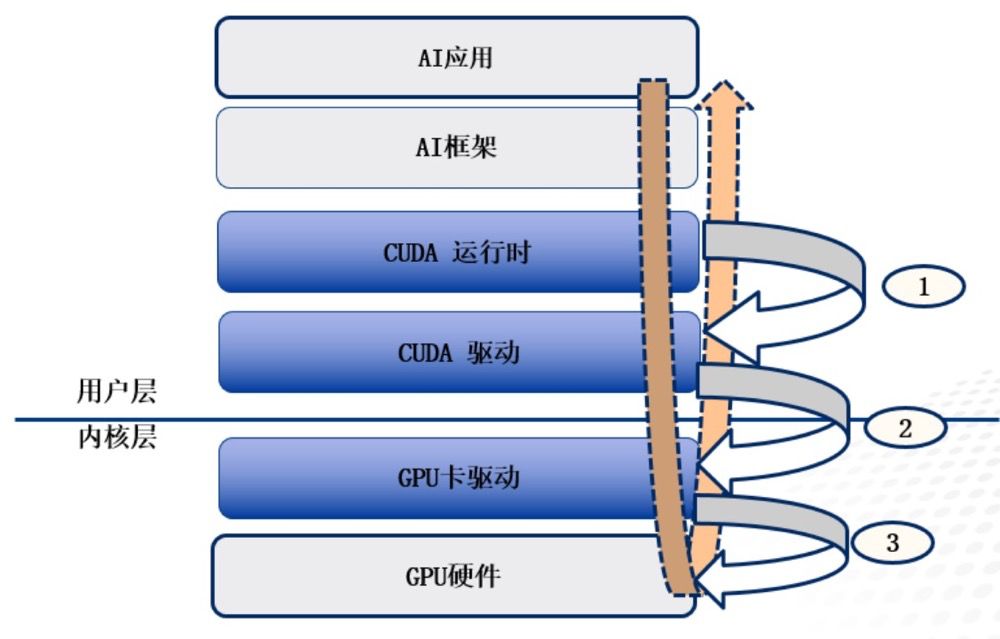
AI应用调用层次
GPU虚拟化和共享方案
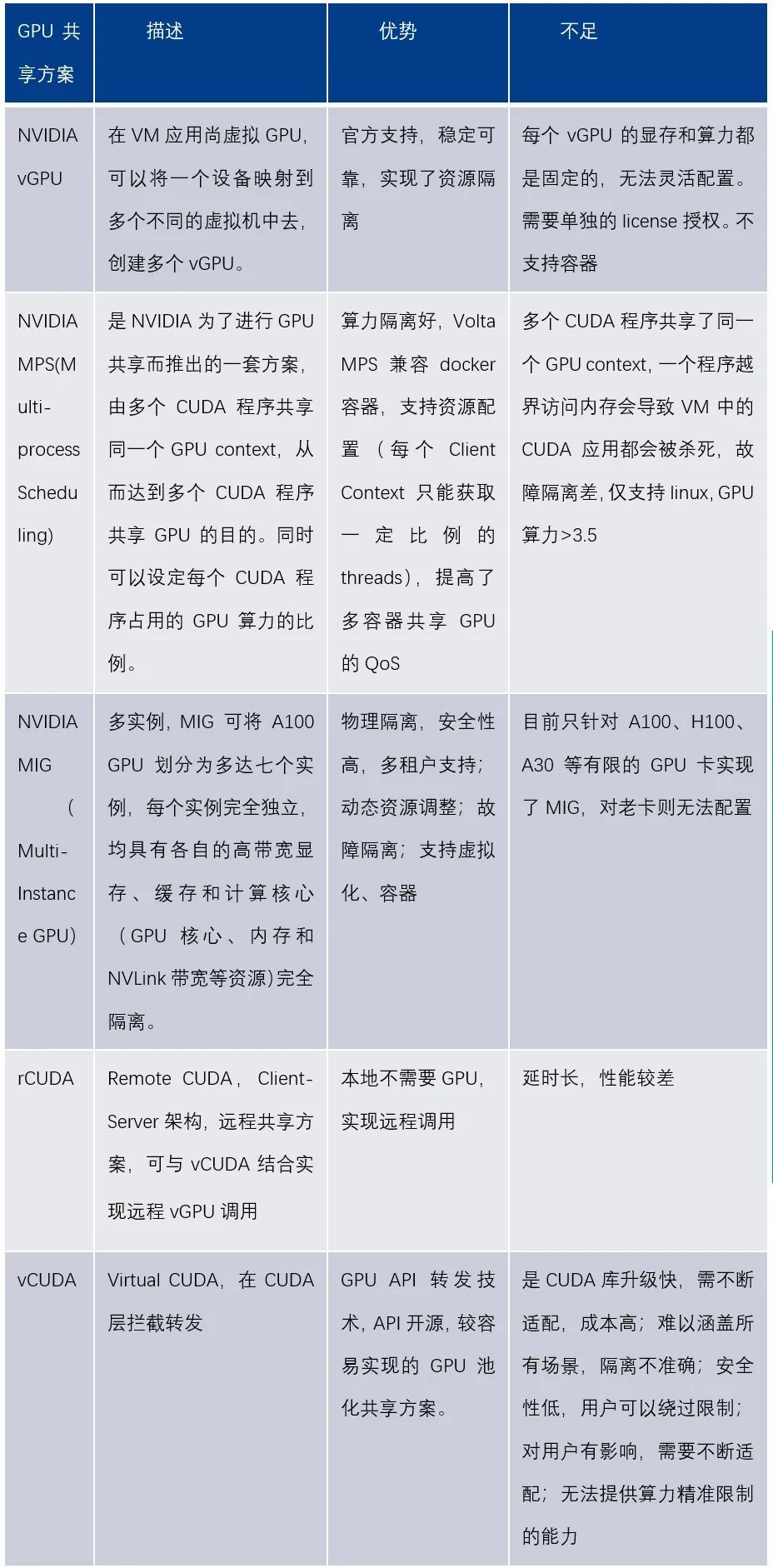
深入解析GPU设备虚拟化,探讨GPU虚拟化和共享的实现途径。英伟达官方提供vGPU、MIG、MPS等方案,同时非官方方案如vCUDA、rCUDA、内核劫持等也各具特色,共同满足多样化需求。
NVIDIA VGPU方案
NVIDIA vGPU是NVIDIA的高可靠、安全虚拟化方案,但局限明显:不支持容器,资源分配固定,无法动态调整;共享损耗较高;不支持定制,且需额外license费用。这些限制影响了其使用的灵活性和成本效益。
MIG方案
MIG是多实例GPU方案。只支持Linux操作系统,需要CUDA11/R450或更高版本;支持MIG的卡有A100, H100 等比较高端的卡;支持裸机和容器,支持vGPU模式,一旦GPU卡设置了MIG后,就可以动态管理instance了,MIG设置时persistent 的,即使reboot也不会受影响,直到用户显式地切换。
借助MIG,用户可以在单个GPU卡上获得最多7倍的GPU资源,为研发人员提供了更多的资源和更高的灵活性。优化了GPU的利用率,并支持在单个GPU上同时运行推理、训练和高性能计算(HPC)任务。每个MIG实例对于应用程序都像独立GPU一样运行,使其编程模型没有变化,对开发者友好。
MPS(Multi-Process Scheduling)
MPS多进程调度是CUDA应用程序编程接口的替代二进制兼容实现。从Kepler的GP10 架构开始,NVIDIA 引入了MPS ,允许多个流(Stream)或者CPU 的进程同时向GPU 发射K ernel 函数,结合为一个单一应用程序的上下文在GPU上运行,从而实现更好的GPU利用率。当使用MPS时,MPS Server会通过一个 CUDA Context 管理GPU硬件资源,多个MPS Clients会将他们的任务通过MPS Server 传入GPU ,从而越过了硬件时间分片调度的限制,使得他们的CUDA Kernels 实现真正意义上的并行。
但MPS由于共享CUDA Context也带来一个致命缺陷,其故障隔离差,如果一个在执行kernel的任务退出,和该任务共享share IPC和UVM的任务一会一同出错退出。
rCUDA
rCUDA指remote CUDA,是远程GPU调用方案,支持以透明的方式并发远程使用CUDA 设备。rCUDA提供了非GPU节点访问使用GPU 的方式,从而可以在非GPU 节点运行AI应用程序。rCUDA是一种C/S架构,Client使用CUDA运行库远程调用Server上的GPU接口,Server监控请求并使用GPU执行请求,返回执行结果。在实际场景中,无需为本地节点配置GPU资源,可以通过远程调用GPU资源从而无需关注GPU所在位置,是非常重要的能力,隔离了应用和GPU资源层。
vCUDA
vCUDA采用在用户层拦截和重定向CUDA API的方式,在VM中建立pGPU的逻辑映像,即vGPU,来实现GPU资源的细粒度划分、重组和再利用,支持多机并发、挂起恢复等VM的高级特性。vCUDA库是一个对nvidia-ml和libcuda库的封装库,通过劫持容器内用户程序的CUDA调用限制当前容器内进程对GPU 算力和显存的使用。vCUDA优点是API开源,容易实现;缺点是CUDA库升级快,CUDA 库升级则需要不断适配,成本高;另外隔离不准确无法提供算力精准限制的能力、安全性低用户可以绕过限制等。目前市面上厂商基本上都是采用vCUDA API转发的方式实现GPU算力池化。
GPU算力池化云原生实现
GPU池化(GPU-Pooling)是通过对物理GPU进行软件定义,融合了GPU虚拟化、多卡聚合、远程调用、动态释放等多种能力,解决GPU使用效率低和弹性扩展差的问题。GPU资源池化最理想的方案是屏蔽底层GPU异构资源细节(支持英伟达和国产各厂商GPU) ,分离上层AI 框架应用和底层GPU类型的耦合性。
不过目前AI框架和GPU类型是紧耦合的,尚没有实现的方案抽象出一层能屏蔽异构GPU。基于不同框架开发的应用在迁移到其他类型GPU时,不得不重新构建应用,至少得迁移应用到另外的GPU,往往需要重新的适配和调试。
算力隔离、故障隔离是GPU虚拟化和池化的关键。算力隔离有硬件隔离也就是空分的方式,MPS共享CUDA Context方式和Time Sharing时分的方式。越靠底层,隔离效果越好,如MIG硬件算力隔离方案,是一种硬件资源隔离、故障隔离方式,效果最好。但硬件设备编程接口和驱动接口往往是不公开的,所以对厂商依赖大,实施的难度非常大,灵活性差,如支持Ampere架构的A100等,最多只能切分为7个MIG实例等。
NVIDIA MPS是除MIG外,算力隔离最好的。它将多个CUDA Context合并到一个CUDA Context中,省去Context Switch的开销并在Context内部实现了算力隔离,但也致额外的故障传播。MIG和MPS优缺点都非常明显,实际工程中用的并不普遍。采用API转发的多任务GPU时间分片的实现模式相对容易实现和应用最广。
AI应用通过GPU调用层次,实现多层次资源池化,涵盖CUDA层、Driver层及硬件设备层。这些层次将加速应用精准转发至GPU资源池。底层转发性能损失小,操作空间大,但编程复杂度与难度也随之提升。精准配置,高效利用,助力AI性能飞跃。
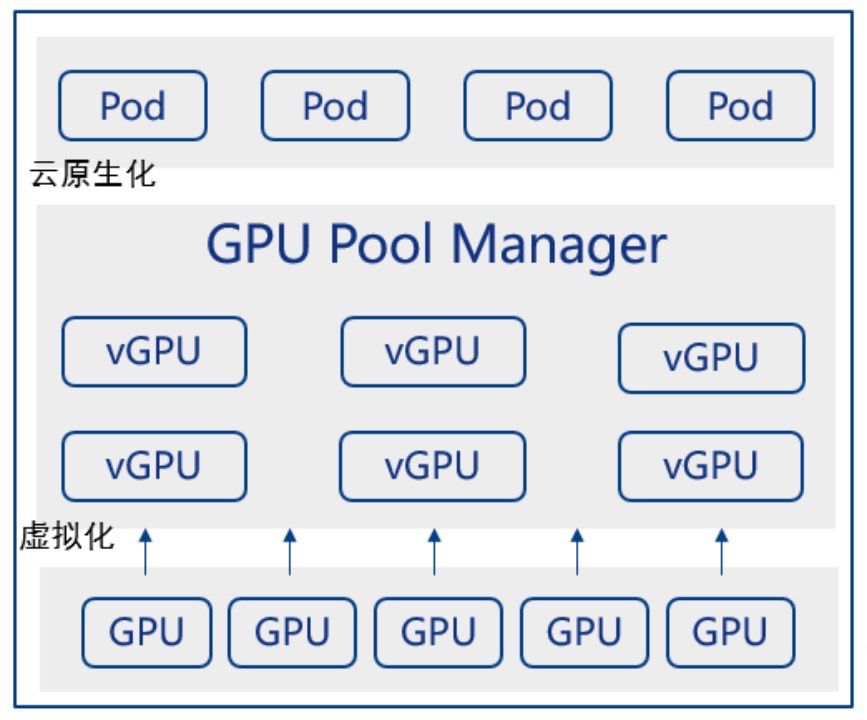
由于云原生应用的大量部署,GPU算力资源池化需要支持云原生部署能力,比如说支持Kubernetes、Docker服务,通过K8s Pod绑定由GPU资源池按需虚拟出来的 vGPU,执行Pod中的应用。不管是英伟达的GPU卡或者是国产GPU,所有的卡都在算力资源池中,当前可以将不同的卡进行分类,不同框架的应用按需调度到合适的分类GPU算力池上。从而提升资源管理效率。
算力资源池同样需要实现相应的资源、资产管理和运行监控和可观测性,优化调度能力,减少GPU资源碎片。随着AI应用需求的迅速增长,算力资源池化在未来一段时间内将是企业关注的重要的一个方面。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
这篇关于揭秘GPU技术新趋势:从虚拟化到池化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!