本文主要是介绍⌈ 传知代码 ⌋ 微表情识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 核心逻辑
- 🍞三. 使用方式
- 🫓总结
💡本章重点
- 微表情识别系统
🍞一. 概述
面部表情图像预处理是面部表情识别的重要步骤,主要目的是在于提取特征之前排除一切与面部表情无关的干扰因素。例如,环境光照、姿势和不同背景等。在干扰排除后,将人类面部直接与公共参考系相对接、使每个面部特征对应的语义位置精准无误。人脸检测、人脸对齐、数据增强、人脸一是实现面部表情图像预处理的主要方法
🍞二. 核心逻辑
人脸检测:
# 初始化字典,并保存Haar级联检测器名称及文件路径
detectorPaths = {"face": "haarcascade_frontalface_default.xml"
}
'''
加载Haar级联检测器:
创建一个空字典detectors,用于存储加载的检测器。
使用cv2.CascadeClassifier()加载XML文件,并将检测器存储在detectors字典中。
'''
# 初始化字典以保存多个Haar级联检测器
print("[INFO] loading haar cascades...")
detectors = {}# 遍历检测器路径
for (name, path) in detectorPaths.items():# 加载Haar级联检测器并保存到mappath = os.path.sep.join([args["cascades"], path])
detectors[name] = cv2.CascadeClassifier(path)
'''
图像处理:
从磁盘读取输入图像,使用imutils.resize函数将图像宽度调整为500像素。
将图像转换为灰度图以便进行人脸检测。
'''
# 从磁盘读取图像,缩放,并转换灰度图
print(args['image'])
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
'''
执行面部检测:
使用人脸检测器执行面部检测,得到面部的边界框坐标。
'''
# 使用合适的Haar检测器执行面部检测
faceRects = detectors["face"].detectMultiScale(gray, scaleFactor=1.05, minNeighbors=5, minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE)
'''
眼睛和嘴巴检测:
对于每个检测到的面部,分别在面部ROI中应用眼睛和嘴巴检测器,得到相应的边界框坐标。
'''
# 遍历检测到的所有面部
for (fX, fY, fW, fH) in faceRects:# 提取面部ROIfaceROI = gray[fY:fY + fH, fX:fX + fW]# 在面部ROI应用左右眼级联检测器eyeRects = detectors["eyes"].detectMultiScale(faceROI, scaleFactor=1.1, minNeighbors=10,minSize=(15, 15), flags=cv2.CASCADE_SCALE_IMAGE)# 在面部ROI应用嘴部检测smileRects = detectors["smile"].detectMultiScale(faceROI, scaleFactor=1.1, minNeighbors=10,minSize=(15, 15), flags=cv2.CASCADE_SCALE_IMAGE)
多人脸检测:
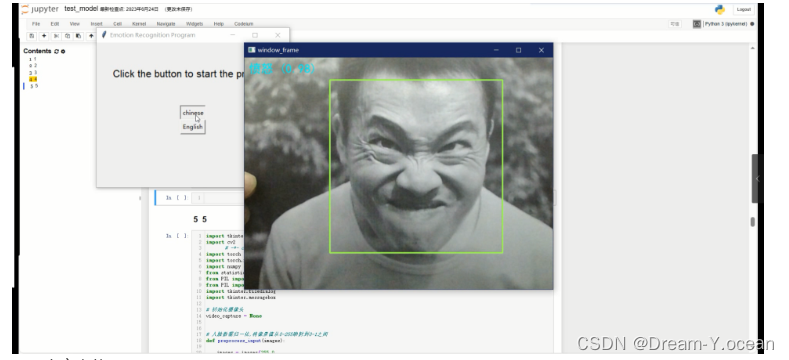
Haar是一种特征描述,随着时代的进步Haar也从Haar Basic的三种简单特征扩展到了Haar-Like以及到现在的Haar Extended。但是万变不离其宗,我们笼统得把他们分成三类:中心特征,线性特征, 边缘特征。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况

Haar原来就是一些固定的特征模型,在人脸识别这个特助的领域中可以局部的契合图像特征。
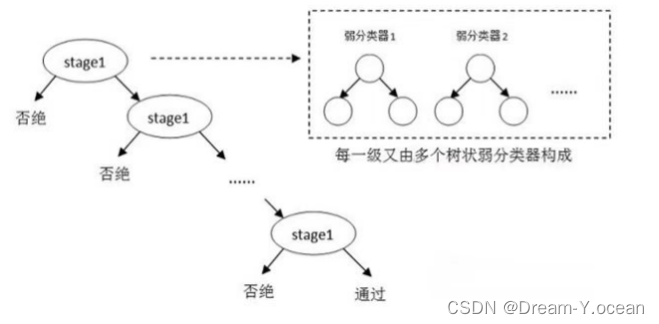
级联示意图:
卷积神经网络,FaceCNN 类:
初始化:定义了一个包含卷积层、批量归一化、RReLU激活函数、池化层和全连接层的卷积神经网络结构。
前向传播方法 (forward):定义了模型的前向传播过程。

🍞三. 使用方式
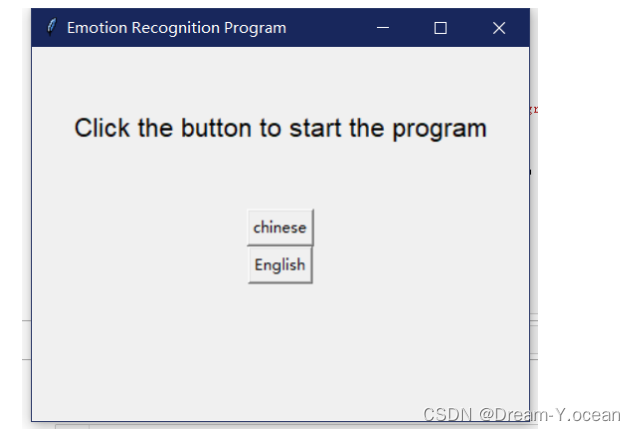
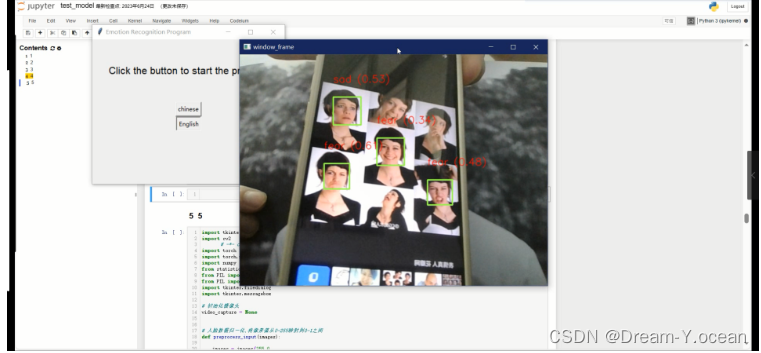
功能分别是中文显示识别结果以及用英文显示识别结果以及相应的置信度计算结果展示。
设置中文字体
font = cv2.FONT_HERSHEY_SIMPLEX
font_chinese = cv2.FONT_HERSHEY_SIMPLEX
指定中文字体文件路径,替换成你自己的中文字体文件路径
font_path = ''
font_chinese = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText()
确保你已经下载并设置好中文字体文件路径。
text = f"{} ()"
cv2.putText()
将 cv2.putText 函数的 font 参数替换为 font_chinese,以确保使用中文字体。
置信度计算:

🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】

加粗样式
这篇关于⌈ 传知代码 ⌋ 微表情识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






