本文主要是介绍轻松产出创新点!多元时间序列最新可参考成果,高性能高精度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天给大家推荐一个好挖创新点的研究方向:多元时间序列。
多元时间序列是我们解决复杂系统分析和预测问题的重要工具。它通过综合分析多个相关时序数据,可以给我们提供更精准的预测结果,非常适合处理涉及多个变量和多个时间点数据的场景,比如交通预测、金融市场分析等,因此拥有广泛的应用范围,创新潜力十分可观。
比如川大、港科大、北理工联合发表的多元时间序列预测新工作MSGNet,使用频域分析和自适应图卷积捕获多个时间尺度上的变化序列间相关性,性能超越时序分析五边形战士TimesNet。
除此之外,今年多元时间序列相关的研究新进展也有不少,我简单整理了15篇给同学们作参考,开源代码已附,方便各位复现。
论文原文以及开源代码需要的同学看文末
MSGNet: Learning Multi-Scale Inter-Series Correlations for Multivariate Time Series Forecasting
方法:本文介绍了一种新的深度学习模型MSGNet,MSGNet的关键组成部分包括:尺度学习和转换层、多重图卷积模块和时间多头注意力模块。通过频域分析和自适应图卷积来捕捉不同时间尺度上的不同序列之间的相关性。MSGNet在5个数据集上实现了最佳性能,在2个数据集上实现了次佳性能。在Flight数据集上,MSGNet超过了当前的最佳模型TimesNet。
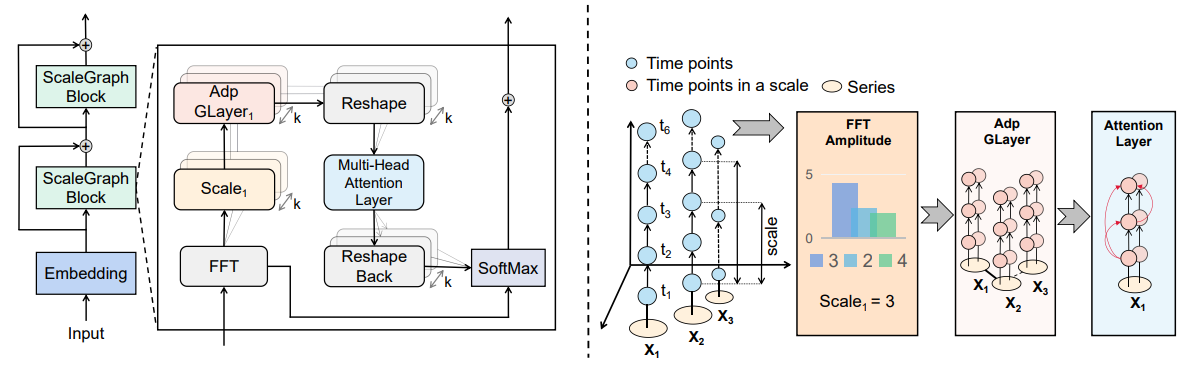
创新点:
-
MSGNet设计的多尺度自适应图卷积模块:MSGNet通过自适应图卷积模块学习多尺度间的复杂关系,有效捕捉多尺度间的变化的跨时间序列的相关性。
-
多头自注意力机制:MSGNet利用多头自注意力机制捕捉序列内部的时间依赖关系,通过对序列进行多尺度的表示学习,从而更好地预测多变量时间序列。

Fully-Connected Spatial-Temporal Graph for Multivariate Time-Series Data
方法:论文提出一种用于多变量时间序列(MTS)数据的表示学习方法,该方法能够全面模拟和捕捉MTS数据中的时空依赖关系,通过构建全连接的时空图和引入移动池化GNN层来实现这一目标,并通过与现有方法的比较和消融实验验证其有效性。

创新点:
-
提出了完全连接的时空图(Fully-Connected Spatial-Temporal Graph)来明确建模多个时间戳之间和每个时间戳中传感器之间的相关性。通过设计基于时间距离的衰减矩阵,改进了构建的图,有效地建模了MTS数据中的时空依赖关系。
-
提出了移动池化图神经网络层(Moving-Pooling GNN Layer),用于有效捕捉构建的图中的时空依赖关系,从而学习到有效的表示。它引入了移动窗口来考虑局部的时空依赖关系,然后进行时序池化操作以提取高级特征。
-
FC-STGNN在C-MAPSS数据集的RUL预测任务中实现了11.62的RMSE,在UCI-HAR数据集上实现了95.81%的准确率,在ISRUC-S3数据集上实现了80.87%的准确率,显著优于其他先进方法,并在模型复杂度方面展现了较低的计算需求和训练时间,证明了其在实际系统部署中的实用性。

SiMBA: Simplified Mamba-based Architecture for Vision and Multivariate Time series
方法:本文提出了一种名为EinFFT的新颖的频域信道混合方法,解决了Mamba中的稳定性问题,并在时间序列和ImageNet数据集上验证了该方法;同时,还提出了一种名为SiMBA的经过优化的Mamba架构,SiMBA是为了处理视觉和多元时间序列数据而设计的。

创新点:
-
EinFFT是一种新的频域信道建模技术,通过使用Einstein矩阵乘法来解决Mamba中的不稳定性问题。EinFFT利用复数表示的频率分量,有效地捕捉图像块数据中的关键模式,并具有全局视图和能量压缩。该技术不仅适用于图像数据,还适用于其他序列数据模态,如时间序列、语音和文本数据。
-
SiMBA是一种优化的Mamba架构,用于CV任务。它使用EinFFT进行信道建模和Mamba进行令牌混合,以处理归纳偏差和计算复杂性。SiMBA是第一个在ImageNet数据集和六个标准时间序列数据集上与最先进的基于注意力的Transformer模型相媲美的SSM。

HDMixer: Hierarchical Dependency with Extendable Patch for Multivariate Time Series Forecasting
方法:论文提出了一种名为 HDMixer 的新型深度学习模型,旨在通过层次化的依赖关系和可扩展的补丁(patches)来增强模型对多元时间序列数据的预测性能。HDMixer通过引入可扩展长度的分块策略和层级依赖探索器(HDE),来捕捉不同维度间的交互作用。

创新点:
-
长度可扩展的分区器(LEP):针对时间序列数据,引入了适应性扩展分区长度的LEP,以丰富时间序列分区的边界语义信息。这种策略可以避免峰值或周期的信息丢失,并且通过引入Patch Entropy Loss作为创新的分区指导,确保分区的准确性。
-
分层依赖性探测器(HDE):HDE由多个堆叠的Mixer组成,每个Mixer都包含三个MLP来捕捉长期依赖、短期依赖和跨变量交互。HDE使用纯MLP实现,可以保持计算效率和易于实现的优势。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“多元时序”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏
这篇关于轻松产出创新点!多元时间序列最新可参考成果,高性能高精度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




