本文主要是介绍爬虫概要,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.爬虫的概念
通过编写程序模拟浏览器操作,让其在互联网爬取/获取数据的过程
2.爬虫的分类
通用爬虫:获取一整张页面的数据(是浏览器"抓取系统"的一个重要组成部分)
聚焦爬虫:爬取页面中指定的内容(必须建立在通用爬虫的基础上)
增量式爬虫:通过监测网站数据的更新情况,只怕取最新的数据
3.反爬机制
通过技术手段阻止爬虫程序进行数据的爬取
4.反反爬策略
破解反爬机制的过程

- connection:closed 每当访问完数据之后就立即断开
5.爬虫的合法性
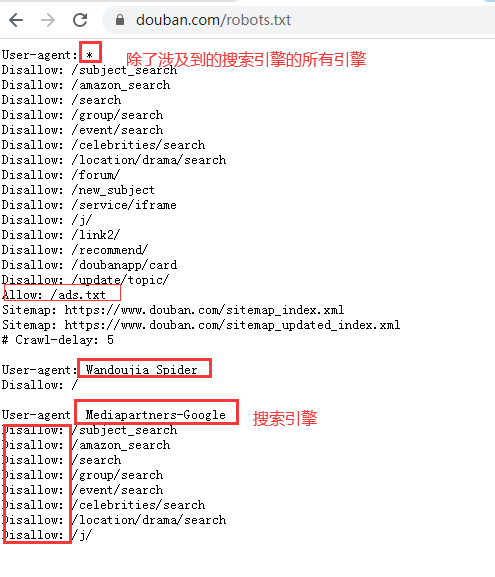
6.robots.txt
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取
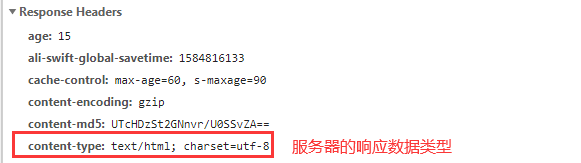
7.HTTP/HTTPS协议
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
8.数据加密的方式
- 对称密钥加密
客户端对请求数据进行加密,将加密信息和密钥一并发送给服务器端,他的缺点是密钥在传输的过程中可能会被窃听或信息挟持,存在安全隐患
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,比如客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患`
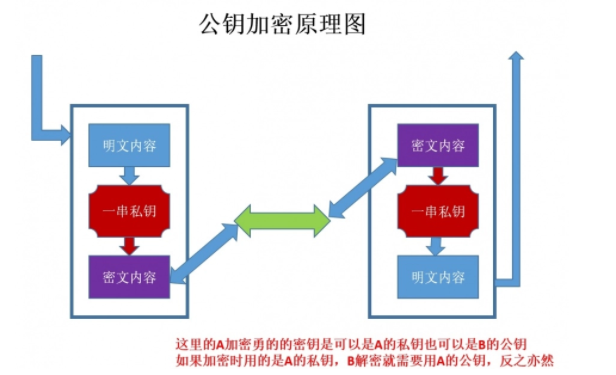
- 非对称密钥加密
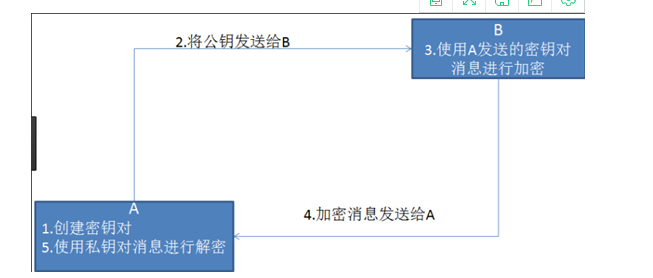
服务端创建密钥对,将公钥发送给客户端,客户端使用公钥对数据进行加密,服务器端用私钥进行解密
非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。
缺点:
1.如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险
2.非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
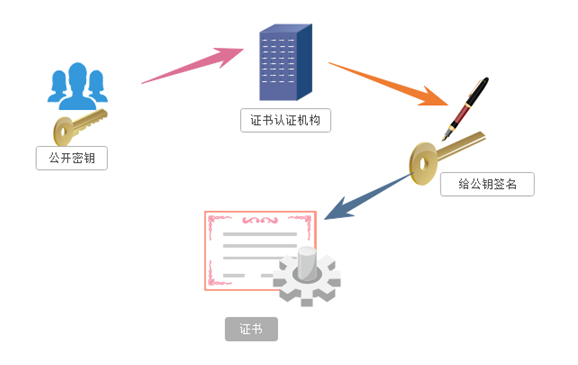
- 证书密钥加密
服务器端发送给客户端的公钥,进行第三方机构(权威)进行认证,没有认证的公司,客户端拒接
1.服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起
2.服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
这篇关于爬虫概要的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







