本文主要是介绍Scrapy爬虫工程设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近做了一些爬虫的工作,并涉及到了工程的部署和自动化,借此机会整理一下,工程结构如图:
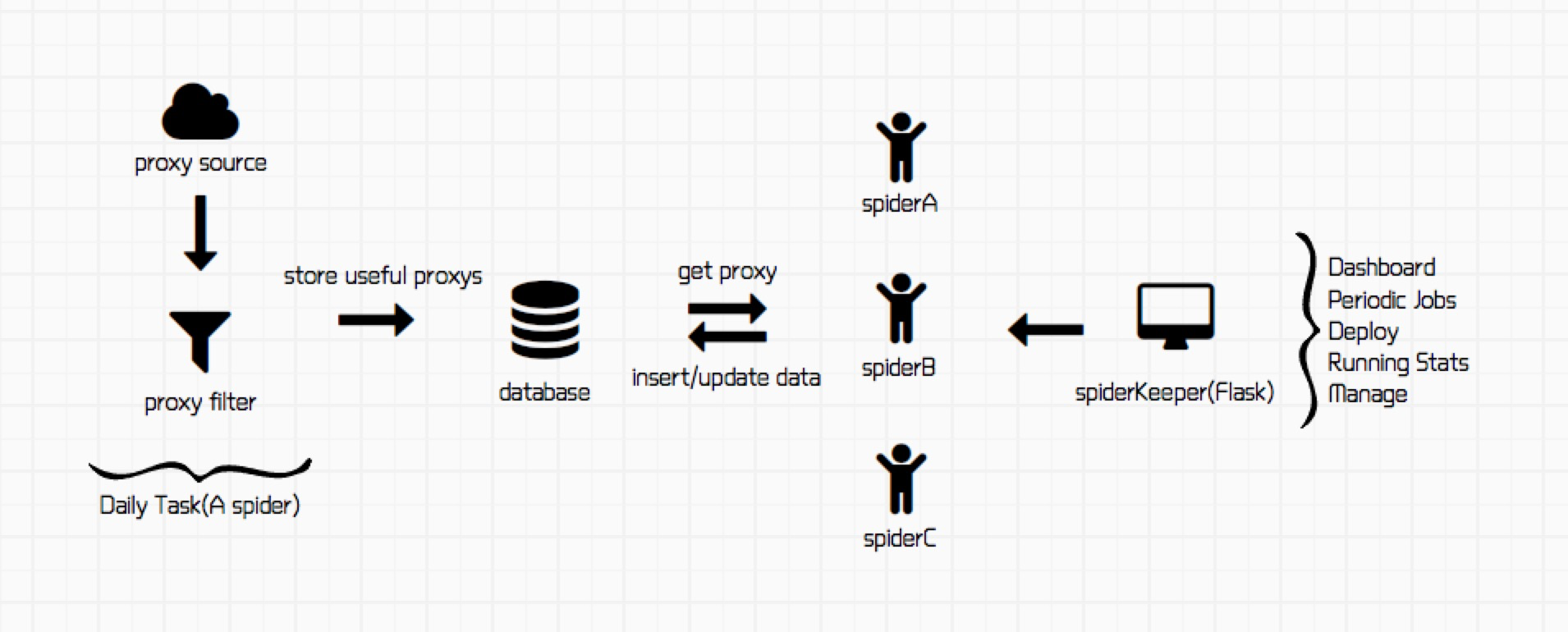
image.png
工程主要包含4个部分:
- 获取有效代理ip
- 数据管理
- 不同任务的spider
- spider在线调度和管理
1.获取有效代理ip
代理IP可从国内的几个网站爬取,如西刺。可以肯定免费的代理IP大部分都是不能用的,不然别人为什么还提供付费的(不过事实是很多代理商的付费IP也不稳定,也有很多是不能用)。所以采集回来的代理IP不能直接使用,需要写一个过滤程序去用这些代理访问目标网站,看是否可以正常使用。我的项目里所有爬虫任务都是每日定时开启的,所以爬取和过滤的过程被设计在了一个spider中,主任务开启的前三个小时执行 ,因为检测代理是个很慢的过程。
以西刺网站为例,创建任务spider:
class Proxy(Spider):name = "scrapy_proxy"#设置custom_settings,执行爬取代理ip的任务时不使用代理 custom_settings = {'DOWNLOADER_MIDDLEWARES' : {'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 543,}}base_url = "http://www.xicidaili.com/nn/"def __init__(self, *a , **kw):super(Proxy, self).__init__(*a, **kw)self.sql = SqlHelper()#数据管理方法self.create_proxyurl_table()#创建存储有效代理ip的tabledef create_proxyurl_table(self):command = ("CREATE TABLE IF NOT EXISTS {} (""`id` INT(8) NOT NULL AUTO_INCREMENT,""`url` TEXT(20) NOT NULL ,""`create_time` DATETIME NOT NULL,""PRIMARY KEY(id)"") ENGINE=InnoDB".format(config.proxy_url_table))self.sql.create_table(command)
爬取前10页的IP:
def start_requests(self):for i in range(1,10):url = self.base_url + str(i)yield Request(url = url,headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Encoding': 'gzip, deflate, sdch','Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6','Connection': 'keep-alive','Host': 'www.xicidaili.com','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:51.0) Gecko/20100101 Firefox/51.0',},callback = self.parse_all,errback = self.error_parse)
解析内容,验证IP有效性,并存储
def parse_all(self,response):proxys = response.xpath("//table[@id='ip_list']/tr").extract()for i ,proxy in enumerate(proxys):if i==0 :continuesel = Selector(text = proxy)ip = sel.xpath("//td[2]/text()").extract_first()port = sel.xpath("//td[3]/text()").extract_first()speed = sel.xpath("//td[7]/div[@class='bar']/@title").extract_first().replace('秒','')connect = sel.xpath("//td[8]/div[@class='bar']/@title").extract_first().replace('秒','')proxy = str(ip) + ':'+str(port)self.validateIP(proxy)def validateIP(self,proxy):try:requests.post('目标网站地址',proxies={"http":proxy},timeout=10)except:util.log(proxy + ' connect failed')else:util.log("grab ip :%s" % (proxy))dt = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")msg = (None,proxy,dt)command = ("INSERT IGNORE INTO {}""(id,url,create_time)""VALUES(%s,%s,%s)".format(config.proxy_url_table))self.sql.insert_data(command, msg)
2.数据存储
创建一个工具类,包含常用的建表,查询,插值等操作
#-*- coding: utf-8 -*-import logging
import mysql.connector
import utils
import configfrom singleton import Singletonclass SqlHelper(Singleton):def __init__(self):self.database_name = config.development_database_nameself.init()def init(self):self.database = mysql.connector.connect(**config.development_database_config)self.cursor = self.database.cursor()self.create_database()self.database.database = self.database_namedef create_database(self):try:command = 'CREATE DATABASE IF NOT EXISTS %s DEFAULT CHARACTER SET \'utf8\' ' % self.database_nameutils.log('sql helper create_database command:%s' % command)self.cursor.execute(command)except Exception, e:utils.log('SqlHelper create_database exception:%s' % str(e), logging.WARNING)def create_table(self, command):try:utils.log('sql helper create_table command:%s' % command)self.cursor.execute(command)self.database.commit()except Exception, e:utils.log('sql helper create_table exception:%s' % str(e), logging.WARNING)def insert_data(self, command, data):try:#utils.log('insert_data command:%s, data:%s' % (command, data))self.cursor.execute(command, data)self.database.commit()except Exception, e:utils.log('sql helper insert_data exception msg:%s' % str(e), logging.WARNING)def execute(self, command):try:utils.log('sql helper execute command:%s' % command)data = self.cursor.execute(command)self.database.commit()return dataexcept Exception, e:utils.log('sql helper execute exception msg:%s' % str(e))return Nonedef query(self, command):try:#utils.log('sql helper execute command:%s' % command)self.cursor.execute(command)data = self.cursor.fetchall()return dataexcept Exception, e:utils.log('sql helper execute exception msg:%s' % str(e))return Nonedef query_one(self, command):try:utils.log('sql helper execute command:%s' % command)self.cursor.execute(command)data = self.cursor.fetchone()return dataexcept Exception, e:utils.log('sql helper execute exception msg:%s' % str(e))return None3. Spiders
关于Scrapy相关的基础知识,请查阅Python系列文章
4.Spider在线调度和管理
SpiderKeeper是一个scrapy的管理后台,基于Scrapyd和Flask。界面如下:
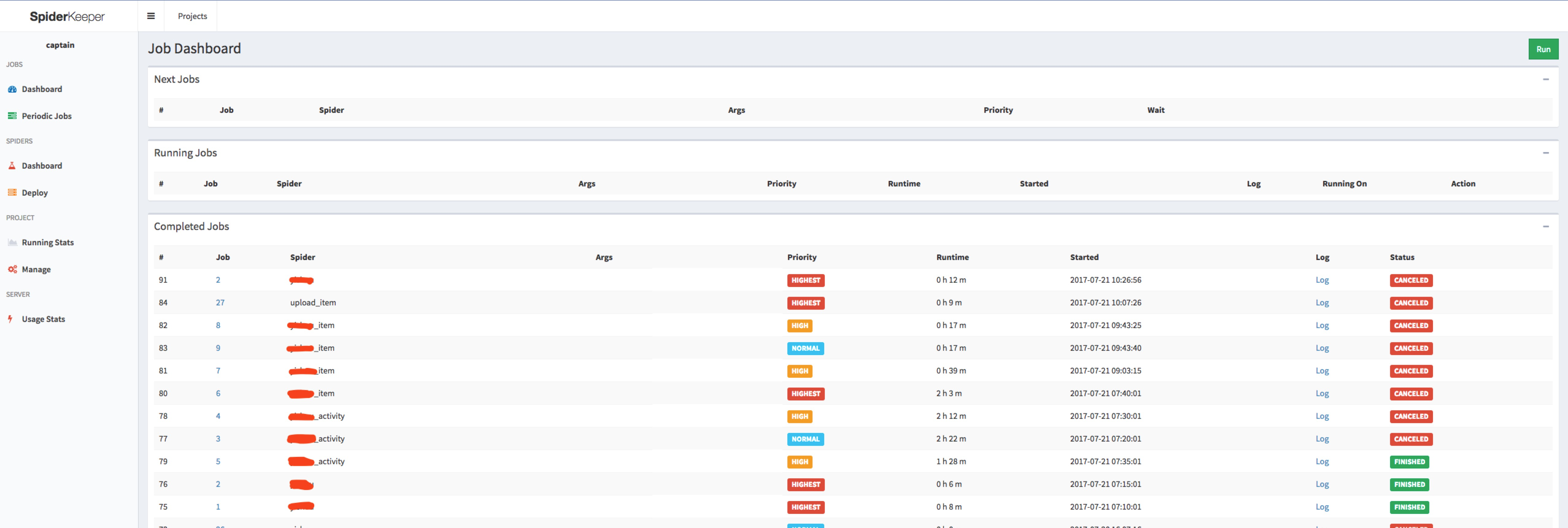
image.png
主要功能包括:
- Job Dashboard
- Periodic Jobs
- Deploy
- Running Stats
- Manage
作者:SamDing
链接:https://www.jianshu.com/p/b360f53930e7
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这篇关于Scrapy爬虫工程设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








