本文主要是介绍周三晚19:00 | 数据资源入表案例拆解,他们如何应对入表难点?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据资源入表的具体场景是怎样的?如何应对数据资源入表难点?
6月5日,即周三晚19:00,讲师-星光数智首席数据架构师 魏战松将继续带来关于《数据要素资产运营》的主题直播,为大家拆解数据资源入表的具体案例。

累计776条的福利材料——《数据要素相关政策及法规汇总》,时刻在直播间为大家准备着🙌
欢迎在惟客数据视X频X号X预约观看,领取福利哦👀👀👀
上期直播回顾

-
直播主题:数据要素价值化实现进程
-
分享人:魏战松
-
部分内容回顾:
1、数据产品和数据资产区别
数据产品:通过加工与分析数据资产所得到的,可以提供具体见解、解决方案或是者服务的工具与应用
数据资产:可以生成价值的数据模型,可以用于创造经济价值或者提供决策支持
2、数据产品化路径
产品规划→产品孵化→合规审查→产品上市→交易撮合→产品运营
-
数据产品规划:全面分析业务场景和痛点,基于要解决的业务需求,确定产品目标和价值
确定产品目标(优化某个流程、预测未来趋势、发现新机遇、提高客户体验等)
技术可行性评估(评估实现该产品的数据工程、数据分析建模、前后端架构,以及用到的计算资源、存储资源、软硬件架构等)
数据资源评估(1. 评估有哪些数据资源可用,比如客户数据、产品数据、交易数据、财务数据、设备数据等;2. 评估数据质量,完整性、准确性、最新性、隐私合规等方面)
-
数据产品孵化
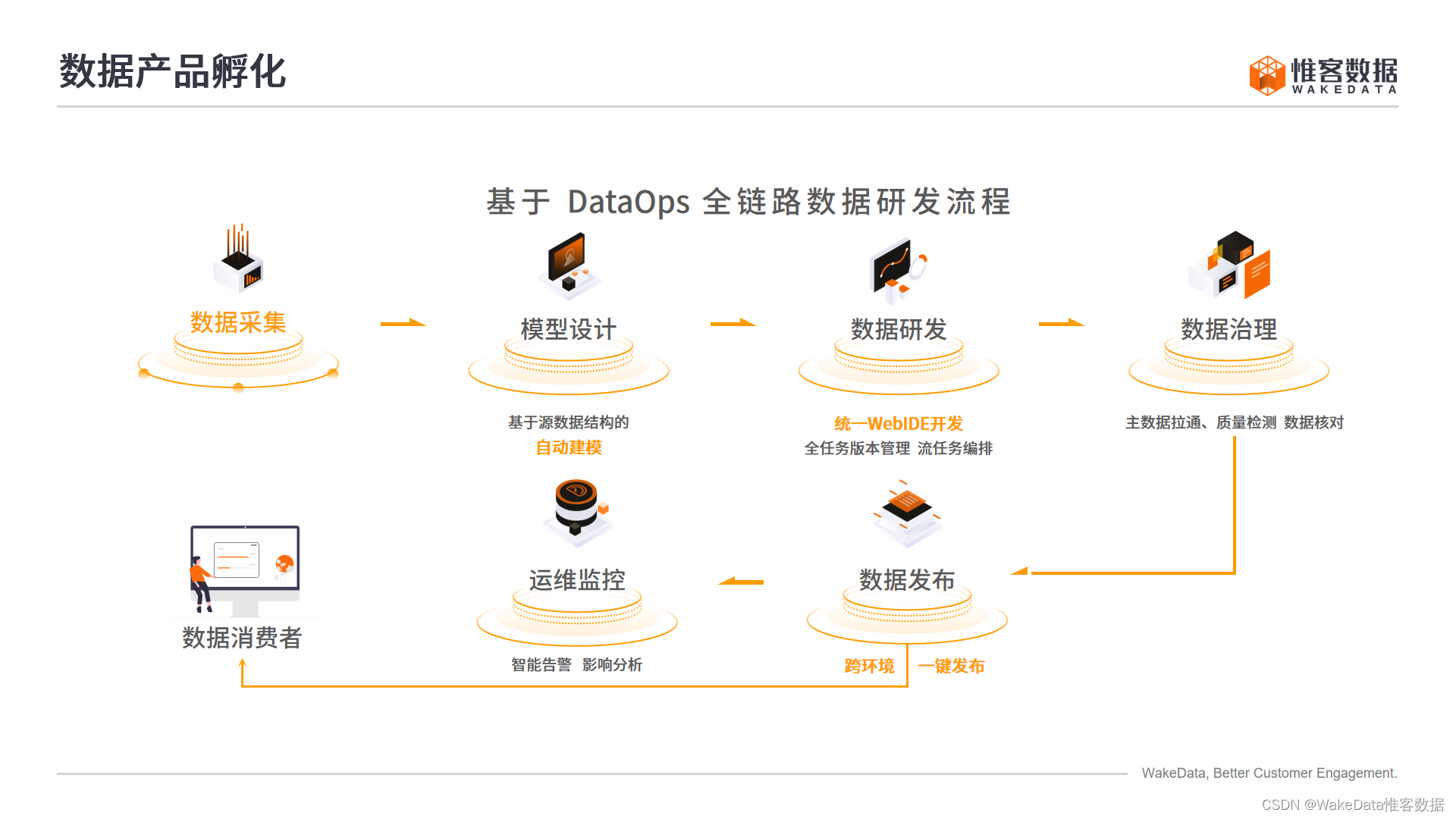
-
数据产品合规审查
数据来源合规(来源及收集方式)
数据权益合规(数据资源的持有权、数据加工使用权、数据经营权的权益)
数据应用场景合规(标签画像、自动化决策、营销推荐)
数据流转合规(外部流转、内部流转、权力转移)
数据处理合规(数据分级分类;数据资产管理体系;数据处理的合法性、正当性、必要性)
-
数据产品估值上市
成本因素(因素之首,考虑入账价值)
场景因素(先确定场景类型,再评估)
市场因素
质量因素(数据质量评价)
-
数据产品交易撮合
供需衔接机制、产业生态融合、合规保障、流通技术支撑
-
数据产品运营
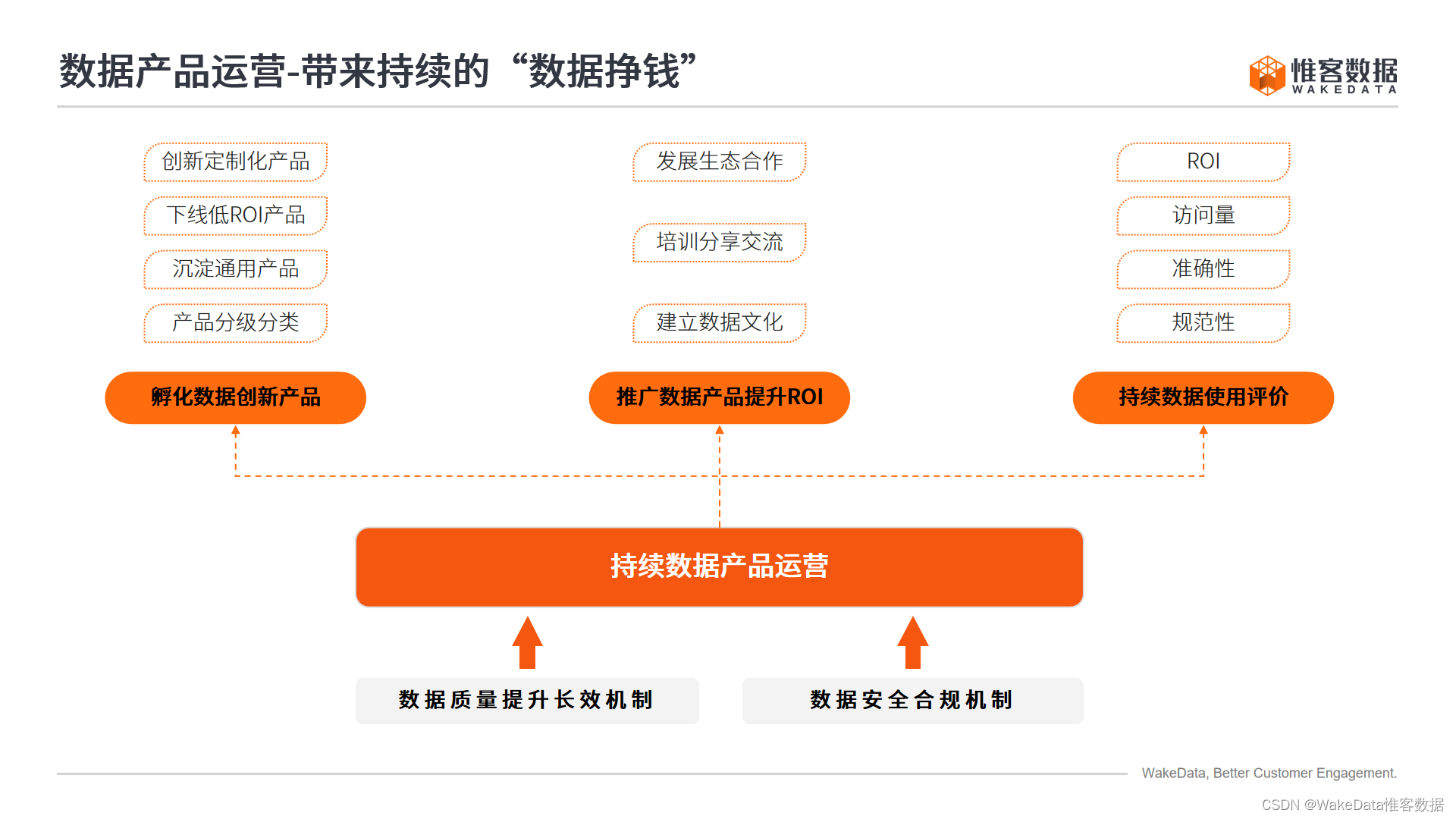
更多直播内容,欢迎扫码关注惟客数据视X频X号X,观看直播回放👇👇👇
关于星光数智
星光数智是WakeData惟客数据在“数据要素领域”的战略布局,专注于企业数据资产管理和价值变现的综合解决方案服务商。
星光数智希望帮助大中型企业在数据战略咨询、数据盘点、数据资产评估、数据资产流通交易等关键领域有所斩获,构建以数据资产为核心的创新模式。
这篇关于周三晚19:00 | 数据资源入表案例拆解,他们如何应对入表难点?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






