本文主要是介绍技术干货|内容风控中的视频分析技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着短视频时代的到来,互联网视频内容爆炸式增长。伴随着这一增长的是低俗、暴力等违规违禁内容的激增,这些内容不仅违反了平台规定,也可能对观看者产生负面影响。为了维护网络环境的健康,视频分析技术成为了内容风控领域的一项重要工具。
由于视频具有信息密集性特点,视频分析的智能化和自动化尤为重要。视频分析技术的突破会带来机器综合判断和理解能力的提升,能够进一步减少对人工审核的依赖,从而大幅提高审核的效率和准确性,更高效地保证平台内容的健康合规,这意味着内容风控机审水平可以向下一阶段迈进。
针对各类视频内容审核需求,一种直观的解决方案是,将视频截帧后,采用图像内容审核技术进行审核。这类方案能够完成对静态信息的识别,但无法有效捕捉或判别视频中的违规动态信息,例如舞蹈、打架动作等。在舞蹈场景中,无法通过单个图像帧判断舞蹈动作类型,如下示例中,视频 1 中的每一个静态帧都是正常样本,但实际上包含了扭胯,摸胸等低俗舞蹈动作;视频 2 中后半段的视频帧中衣着和姿势都相对性感,但实际为静止状态,没有进一步出现低俗动作。

图片来源于网络
我们在此应用场景上对比了图像分类和视频分类两种解决方案的分类效果,从表中可看出视频分类方案具有显著优势。相较于简单截帧和静态图像识别,视频维度的处理方式能够更好地捕捉视频中的动态信息和时间序列特征。从以下几个角度分析,视频算法技术在视频内容分析任务中具有必要性:
-
时间相关性:由于视频是由一系列连续的图像帧组成,因此视频维度的处理可以更好地捕捉到图像帧之间的时间相关性和变化趋势。
-
上下文信息:视频维度的处理方式可以提供更丰富的时空上下文信息,包括物体移动、视角变化、场景变化等,有助于更全面地理解视频内容。
-
动作识别:视频维度的处理方式能够有效地实现运动轨迹跟踪和动作识别,从而更准确地分析视频中的动态特征,进而判断行为方式。
-
事件检测:视频维度的处理方式能够更全面地分析视频中的事件发展,通过对视频片段进行整体处理,可以提高对复杂场景的理解和判断能力,从而可以更好地推断和识别视频中的事件。

图像分类和视频分类效果对比
由于视频算法技术在内容分析中具有重要意义,因此我们持续地在该方向上进行了技术研发投入,并取得了相关的业务结果。在接下来的文章中,我们将首先介绍视频分类、视频检索两类重要的视频算法技术的应用与创新,由于视频维度的处理方式往往会带来更大的计算开销,因此我们也将介绍视频加速相关的技术工作和实践效果,加速相关的技术能力将为视频算法技术的广泛应用带来契机。
《网易数智年度技术精选》完整版下载,戳我!

视频标签分类能力
技术方案
视频分类方法经过了从“2D 卷积+T”模式到3D卷积,再到 Transformer-based 方法的发展过程(如下图)。视频分类任务的核心在于理解视频中的动态模式和行为。传统的方法如 CNN 结合 RNN 或 3D 卷积网络,虽然能够处理视频数据,但在捕捉长期依赖和复杂时空关系方面存在局限。而 Transformer 架构的自注意力机制能够捕捉数据中的长距离依赖关系,这对于捕捉和理解视频中的动态信息十分有利。
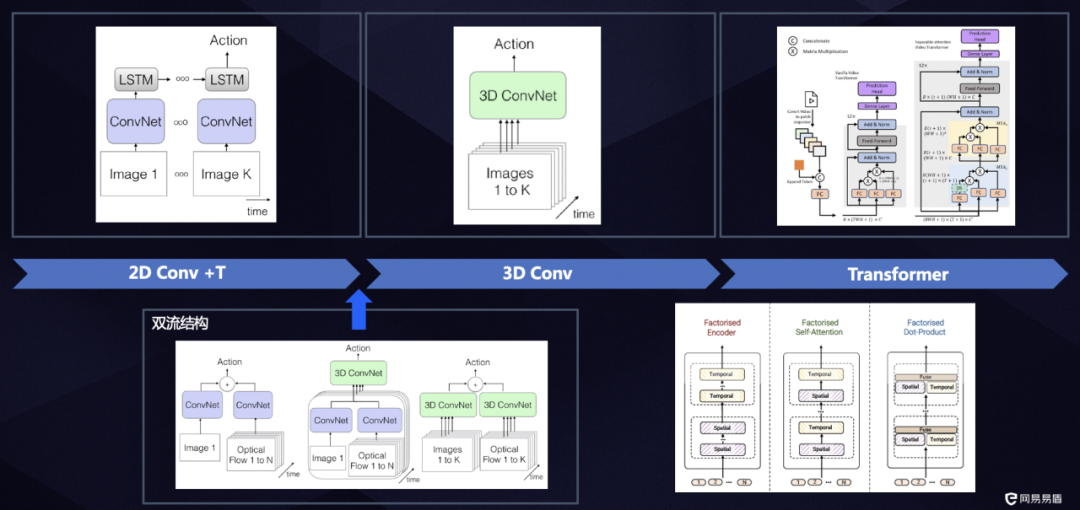
视频分类方法发展过程
因此我们参考了基于 Transformer 架构的 TimeSformer 模型(如下图),将视频帧作为输入序列的元素,通过多头自注意力机制捕捉帧与帧之间的动态关系,从而学习到视频中的动态特征。通过这种方式,能够同时处理空间和时间维度的信息。
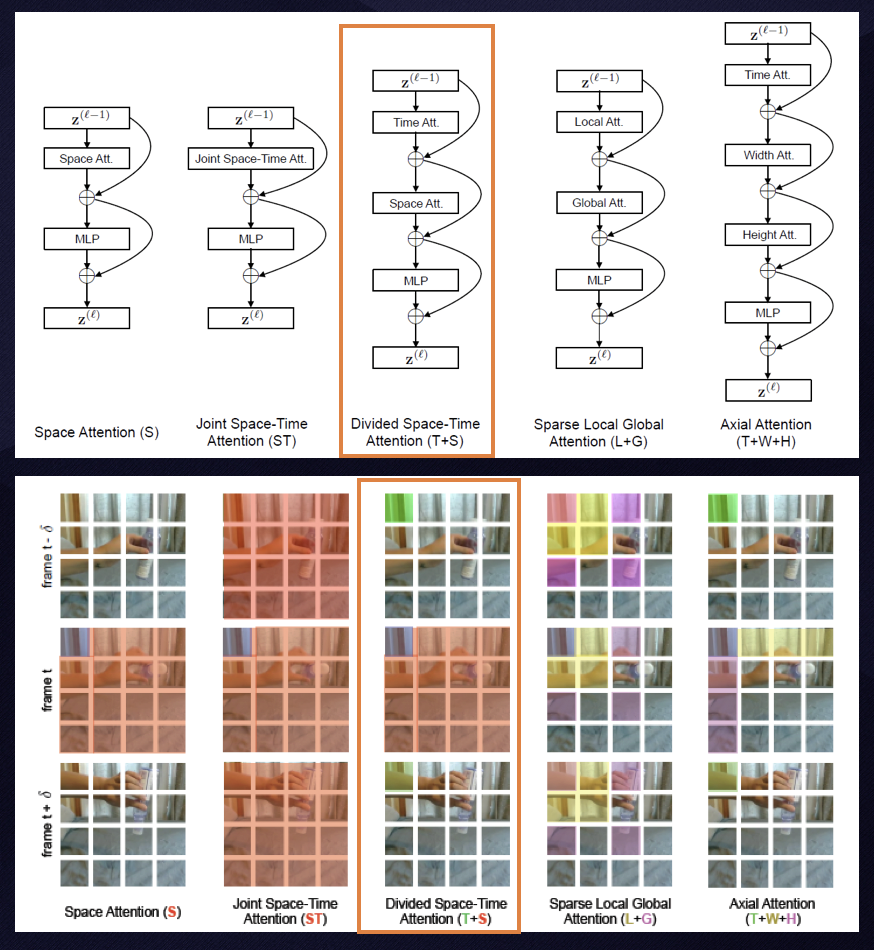
基于 Transformer 架构的 TimeSformer 模型(来源于 TimeSformer 论文 [1])
在传统的监督学习之外,我们进一步探索了视频半监督训练方法,使用针对视频时序信息的数据增强方法进行时序对比学习。依据“改变一段视频的播放速度,并不会改变动作类别”的原则,随机改变一段视频的播放速度,可以和原视频构成一对正样本对,而两段不同的视频则构成负样本对,来进行模型的时序对比学习。其中,除了分类任务常用的交叉熵损失函数外,我们还参考了 Group Contrastive Loss 来约束视频中不同时间戳的帧,使得同一视频中不同时间点的帧在特征空间中相互靠近,而不同视频中的帧在特征空间中相互远离。这样,模型学到的特征表示能更好地捕捉视频中的动作特征,有助于提高动作识别的性能。
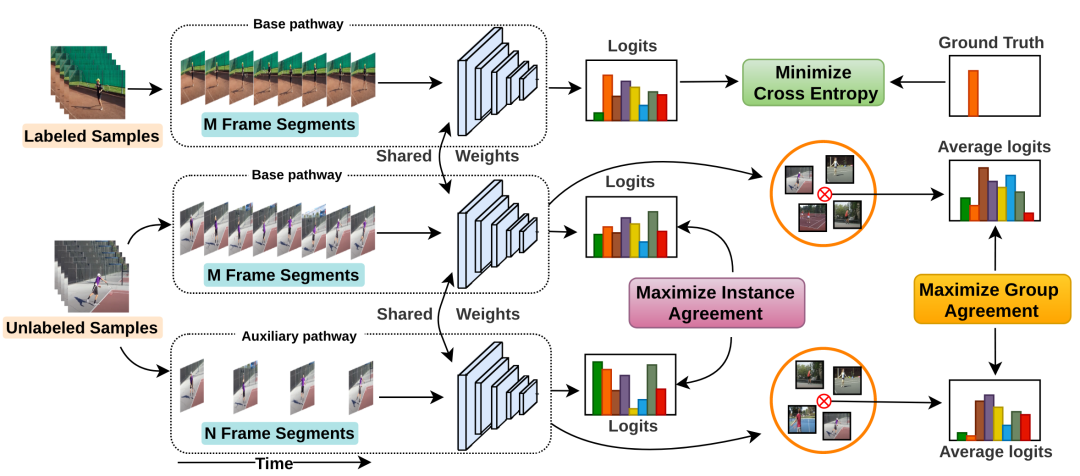
视频半监督训练方法示例(来源于 TCL 论文 [2])
实现效果
虽然 Transformer 结构通常被认为计算量较大,其应用于视频上的计算开支就更大了,但是 TimeSformer 中采用的 Divided Space-Time Attention 机制,将空间依赖关系与时间依赖关系进行分离计算,可以将计算复杂度从 O(NM)降到 O(N+M)。而且,由于 TimeSformer 结构在提取时序信息上具有优势,相比基于 3D 卷积的方法,能够按更大的采样间隔进行帧采样,同样长度的视频所需的模型前馈次数反而更少。因此,以低俗舞蹈识别任务为例,我们成功将视频服务耗时控制在 80ms 左右,并且在业务数据上的识别准确率能达到 85.7%。此外,虽然视频数据标注的成本远高于图像标注,但我们采用的时序对比学习和半监督训练方法能够实现对无标注数据的利用。

视频特征检索能力
技术方案
作为视频分类基础上的能力补充,视频检索是指根据视频库中的视频,检索相同或者相似的视频片段或完整视频。相比于普通的图片检索,视频检索有更高的技术难度和复杂度。一般方案通常基于视频特征进行相似度匹配,根据相似度匹配的颗粒度不同,主要可以分为 frame-level 和 video-level [3][4]。前者是指逐帧两两计算相似度,最后以某种机制,例如 Chamfer Similary,来计算两段视频的整体相似度;后者则是利用两段视频所对应的 video-level 特征,计算相似度。frame-level 视频检索通常精度高但是速度很慢,而 video-level 速度快但往往精度不高。此外,现有方法常常采用在视频分类任务上预训练的 2D 网络来逐帧提取空间特征,一方面特征提取网络的能力与视频检索任务目标不匹配,另一方面也忽略了视频帧间的时序相关性。
为了解决上述问题,我们自研的 3D-CSL 方法构建了一种全新的可端到端训练的 3D 视频检索网络架构 [5]。区别于一般方案中采用 2D 网络来逐帧提取空间特征的模式,我们采用了 TimeSformer 视频推理网络,直接以一个视频片段为输入,同时提取其中的空间与时间相关性,获得一个 clip-level 的 3D 特征。视频推理网络对于片段内时空信息的有效利用,有利于减少帧间信息的冗余,从而能够提取到比 frame-level 特征更简洁,但比 video-level 特征信息表达更充分的特征。因此,我们也摒弃了常见的 frame-level 或 video-level 的匹配策略,而是取两者之所长,使用 clip-level 的特征对固定长度的视频子片段计算相似度,最后采用 Chamfer Similary Score 来表示两段视频的整体相似度,这样既能够减少匹配次数,加快检索效率,又能避免单个特征向量不足以表征整段视频的问题。
为了训练这个全新的网络架构,我们提出了自监督的 3D 上下文视频相似度学习策略。我们对输入视频片段进行随机数据增强,例如随机裁剪、剪辑、加边框等(不包括水平翻转),经过变换后的视频片段与原视频为相似视频,可构成一对正样本对,而输入视频片段与来自其他视频的片段则构成多对负样本对,我们使用 Multi-Similarity Loss 作为训练目标损失,根据相似度进行难例样本挖掘,并鼓励模型使正样本对在特征空间内更加靠近,同时负样本对之间更加远离。
与此同时,我们受启发于视觉手性理论,即视频在水平翻转后与原视频在信息上存在差异,因此经过数据增强且水平翻转的视频片段与原片段的距离,应该大于未经过翻转的片段与原片段之间的距离,据此构建 FCS loss,用于进一步鼓励模型满足这一特性,这意味着模型能够提取到更准确的视觉特征。此外,在著名的 VideoMAE 无监督方法的基础之上,我们进一步以视频预测生成未来帧为辅助任务,对模型进行了无监督预训练,能够为具体的下游任务训练建立更好的初始化参数。
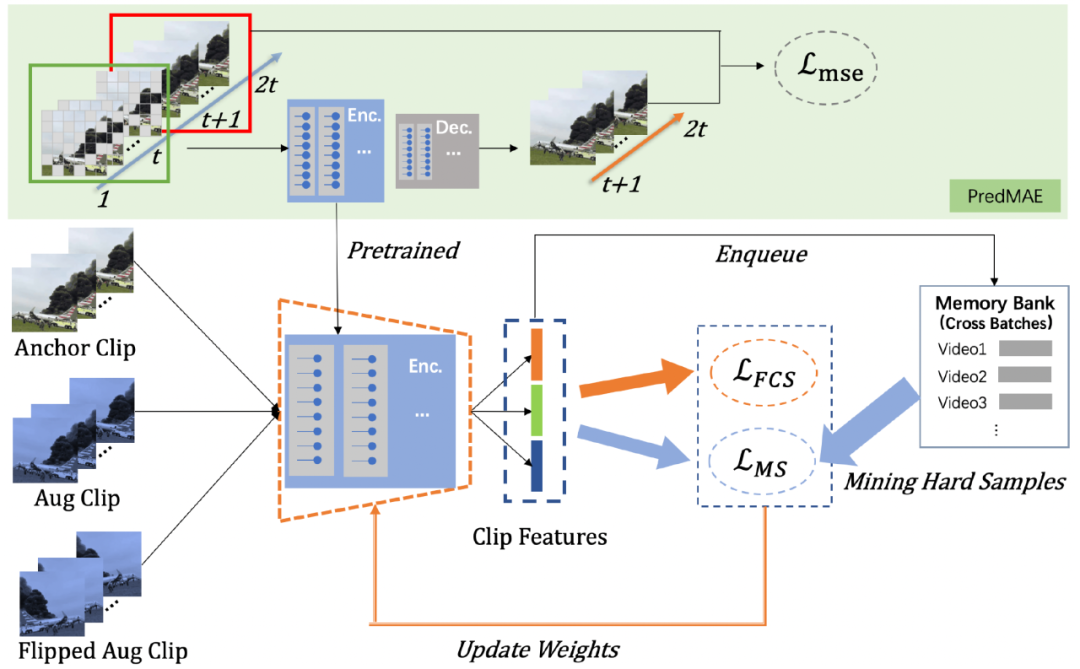
自监督的 3D 上下文视频相似度学习
实现效果
我们的方法在相似视频检索任务上获得了效果与效率上的最佳平衡,并且在两个通用数据集,FIVR-200K 和 CC_WEB_VIDEO 上均达到了 clip-level 视频检索精度的 SOTA 水平。相比于常见的集中快速视频级检索方法,我们的检索精度可提升 31%;相比于常见的帧级视频检索方法,我们的检索精度损失可控制在 3% 以内,但检索复杂度降低 64 倍,同时特征库存储量降低8倍。
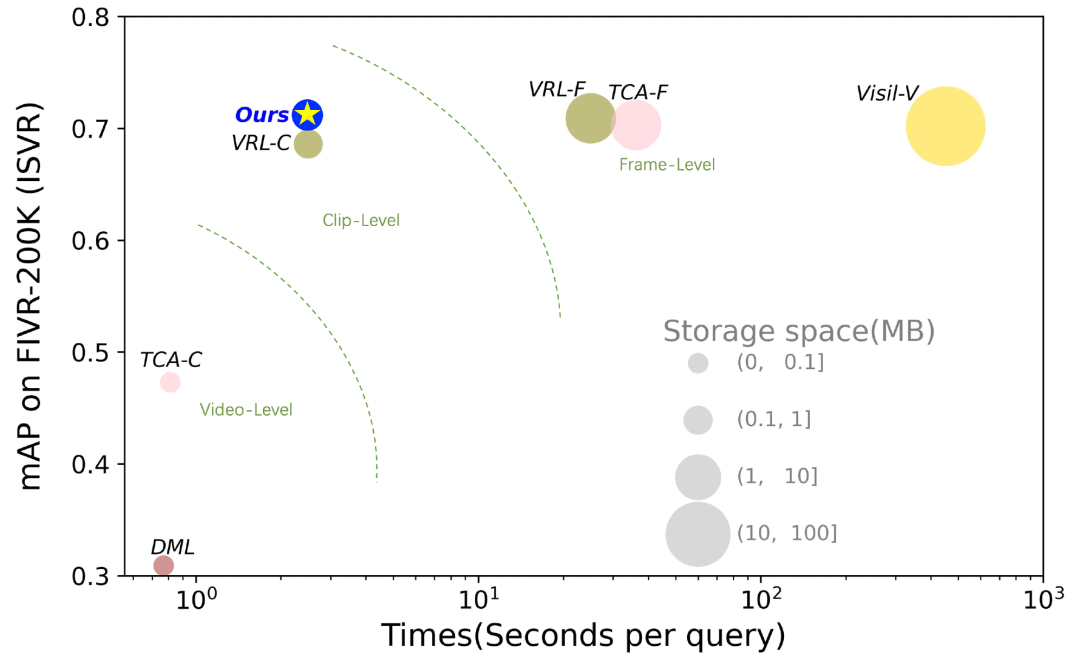
相似视频检索任务上效果与效率的平衡
此外,由特征可视化可以看出,通过在视频检索任务上的专门训练,我们的视频检索模型所提取到的特征与视频分类模型特征存在明显区别。视频分类网络主要关注画面中对于分类有效的目标主体,但是视频检索网络则会关注更宽泛的视觉特征,这些细节特征对于相似度匹配而言都是有效的。
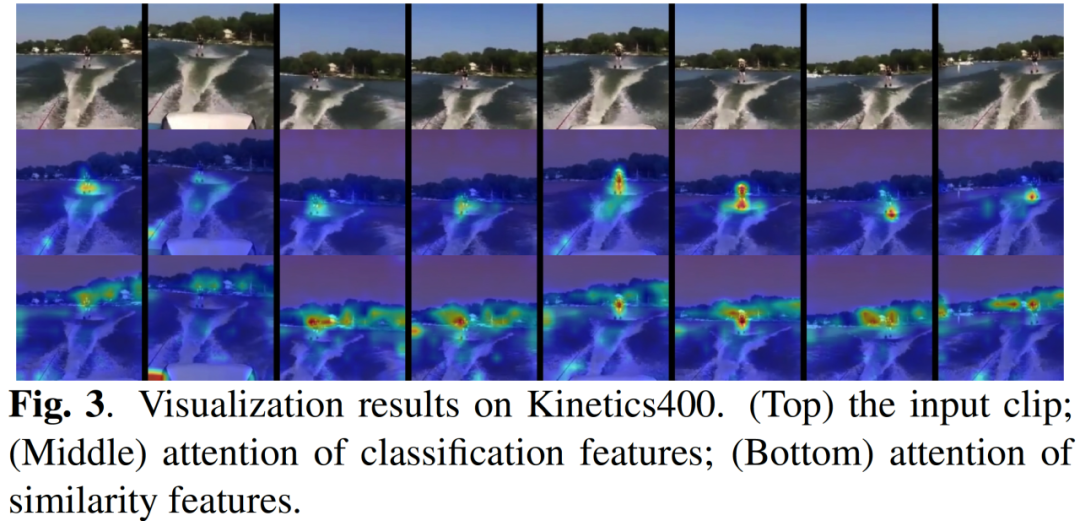
视频特征可视化
在业务场景的实践中,根据业务数据时长普遍较短,少量较长的情况,我们构建了灵活的二级多粒度检索方案。对入库视频分别提取视频级特征与片段级特征,构建两个不同粒度的特征库。对 Query 视频首先进行一级检索,即视频级粗粒度快速筛选,当相似度达到警戒阈值时,触发二级检索,进行片段级细粒度检索。针对每个入库视频,只需要存储片段级特征和 1 个视频级特征,存储空间占用相比业内常见的帧级特征库可减少约 7 倍;在我们的实践中,二级多粒度检索系统,相比帧级检索系统,特征存储量从 GB 级显著降低到 MB 级,平均每段视频的检索耗时从秒级突破至毫秒级。
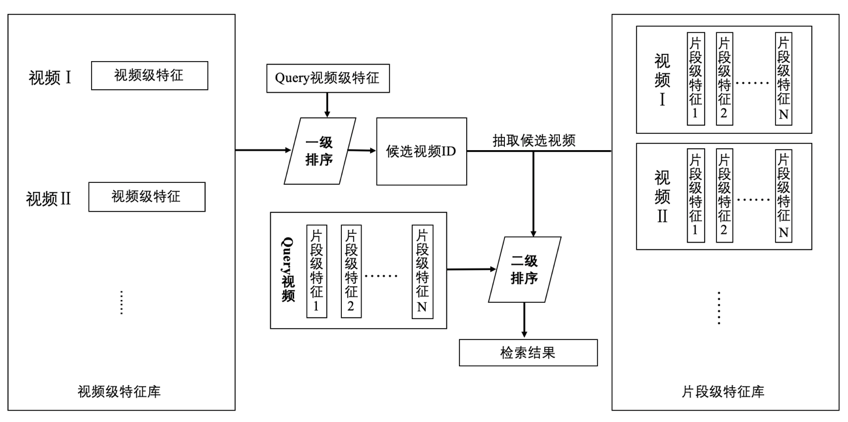
二级多粒度检索方案的简易流程图
《网易数智年度技术精选》完整版下载,戳我!

视频算法加速能力
技术方案
当前视频任务的处理耗时较长,许多工作致力于设计轻量化的模型结构或帧采样的数据抽取方式,以提升视频任务的效率 [6][7]。如下图下半部分所示,动态抽帧分析的策略尽管可以迅速降低视频任务的计算量,但同时带来的“信息丢失”与“信息冗余”双重问题不容忽视,并且从帧图像 2D 来分析视频 3D 数据也是视频任务中的“次优选项”,会从根本上导致对视频数据时空一体特性的丢失。
为了提升视频任务的效率,我们自研了一种基于“token 早停(halting)”的动态视频 transformer 结构——HaltingVT,如下图上半部分所示,我们的方案创新地引入了数据特征自适应的 token halting 机制 [8]。不需要额外训练决策网络,模型通过一次端到端训练,就能同时学到 token 筛选与视频分析能力:在 transformer 层中逐步减少 token 数量,兼顾整体效果和效率。
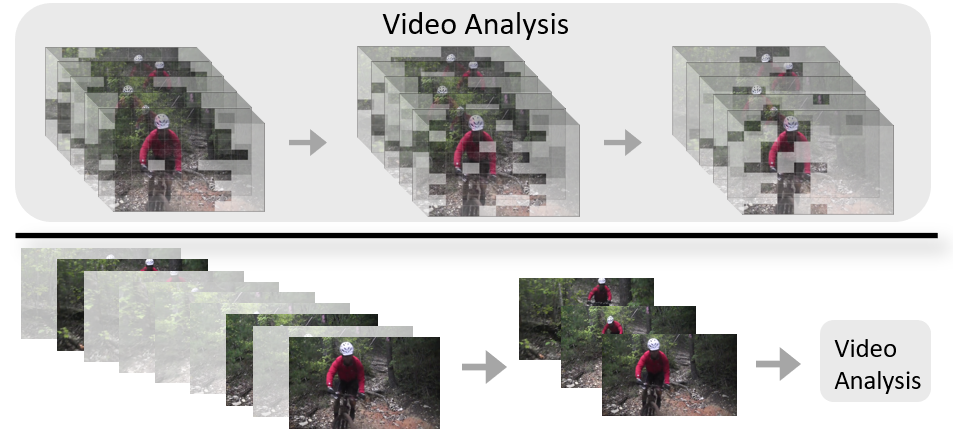
基于 token 筛选的 HaltingVT(上)与传统抽帧视频分析方案(下)的简化原理对比
此外,我们还为 HaltingVT 设计了 Glimpser 子网络模块与 Motion Loss 训练函数,以促使模型能更快、更好地达到训练效果。我们 HaltingVT 方法的整体流程如图所示:
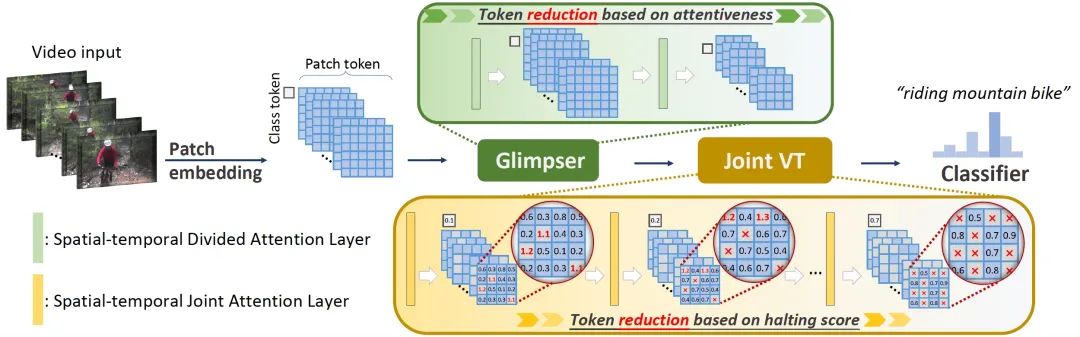
HaltingVT 算法的简易流程图
实现效果
得益于高效的“token halting”机制,HaltingVT 在极大地压缩视频 transformer 的计算资源的同时, 能保留对视频数据时空一体特征的捕捉与分析,从而高效地作出准确判断。
在 Mini-Kinetics 数据集上,HaltingVT 很好地实现了分析效果与计算效率的平衡:在 24.2 GFLOPs 计算量下,达到了 75.0% 的准确率(top1-ACC),而同领域的多数其他方法在同等计算消耗下准确率只能达到73%左右;尤其是在 9.9 GFLOPs 极低的计算量下,HaltingVT 的准确率也能突破性实现 67.9%,相比之下同领域其他方法在更高计算量 12.4 GFLOPs 的情况下只能达到 65.4%的准确率。我们的实验结果证明了 HaltingVT 在效果和效率方面的显著表现,为解决视频任务效率低下问题提供了突破性的解决方案。
《网易数智年度技术精选》完整版下载,戳我!

展望
当前 AIGC(AI 生成内容)、跨模态、大模型等前沿技术发展十分迅速,相关技术在文本内容分析、静态图像分析、音频内容分析等领域已经取得了一定的技术应用。AIGC、跨模态对齐等技术在视频分析算法中也有许多潜在的结合点,可以进一步提升视频分析算法的应用效果。以下是我们正在探索的技术结合点和提升效果的方式:
-
跨模态信息提示:通过跨模态对齐技术,将视频内容与其他模态数据(比如文本描述、语音指令)进行对齐,有助于提高视频分析算法对视频内容进行更深层次的理解和推理。
-
多模态特征融合:通过多模态技术,可以将来自不同模态(如文本、图像、音频)的信息进行统一和融合,使得视频分析算法能够更全面地理解视频内容,从而提高视频内容的分析和理解能力。
-
基于 AIGC 的视频内容增强:AIGC 技术可以用于视频内容的增强,包括视频去噪、视频修复、超分辨率重建等,从而提高视频内容的质量,有利于视频分析算法更准确地进行分析和识别。
综合来看,AIGC 和跨模态对齐技术可以通过提供更丰富的多模态信息、增强视频内容等方式,改善视频分析算法的理解能力,进一步提升视频分析算法的应用效果,促进视频内容的更全面、准确地分析和应用。我们也将继续跟进前沿人工智能技术发展,在视频\时序领域保持深入挖掘,提升算法服务的综合判断和理解能力,为内容风控机审能力向下一阶段迈进而努力。
参考资料
[1] "Is space-time attention all you need for video understanding?." ICML. Vol. 2. No. 3. 2021.
[2] "Semi-supervised action recognition with temporal contrastive learning." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[3] "Visil: Fine-grained spatio-temporal video similarity learning." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
[4] "Learn from unlabeled videos for near-duplicate video retrieval." Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2022.
[5] "3D-CSL: self-supervised 3D context similarity learning for Near-Duplicate Video Retrieval." 2023 30th IEEE International Conference on Image Processing (ICIP). IEEE, 2023.
[6] "Ocsampler: Compressing videos to one clip with single-step sampling." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[7] "D-step: Dynamic spatio-temporal pruning," in the British Machine Vision Conference (BMVC). 2022
[8] "HaltingVT: Adaptive Token Halting Transformer for Efficient Video Recognition", ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024.
码字不易,点赞收藏,关注我,更多干货内容等你来拿~
这篇关于技术干货|内容风控中的视频分析技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






