本文主要是介绍kafka集群内外网分流方案——筑梦之路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
在现代分布式系统架构中,Kafka作为一款高性能的消息队列系统,广泛应用于大数据处理、实时流处理以及微服务间的异步通信场景。特别是往往企业级应用中,业务网段和内网通信网段不是同一个网段,内网的机器想要访问业务数据只能基于现有业务网卡的机器才能访问,此时想要kafka集群内外网都可以通信,即内网的走内网IP,外网的走外网ip,互不影响,同时,也要确保集群内部通信高效、安全,充分利用内网资源,避免不必要的外网流量消耗。就需要引入kafka的listener.security.protocol.map配置项,可以设置两个不同的侦听器,分别对应内网IP和外网IP。PLAINTEXT则表示使用明文协议进行通信,虽然简单但足够直观地展示了如何区分内外网流量的处理方式。通过这样的配置,Kafka能够清晰地区分请求来源,内网通信利用高效的内网IP进行,保证了数据传输速度和安全性,而外网业务请求则通过外网IP接口接入,实现了内外网的逻辑隔离和资源优化。
系统拓扑
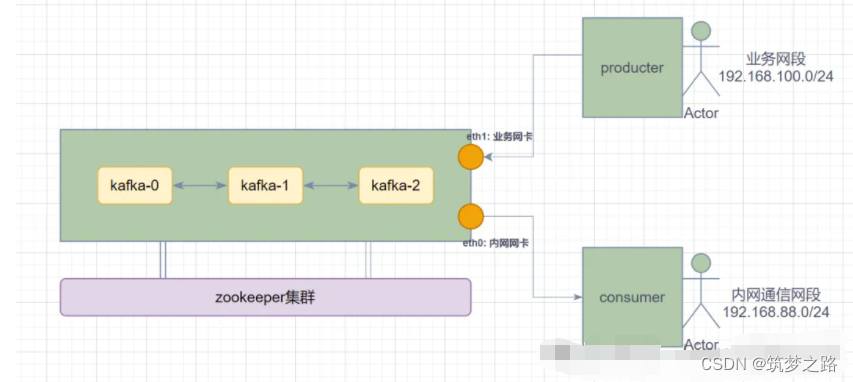 上图中的kafka集群有两张网卡,需要内网段192.168.88.0/24访问,也需要外网段192.168.100.0/24访问,如何实现内外网分流?
上图中的kafka集群有两张网卡,需要内网段192.168.88.0/24访问,也需要外网段192.168.100.0/24访问,如何实现内外网分流?
实现过程
1. 配置kafka
(关键部分)
vim config/server.propertieslistener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
# 配置监听内外网地址
listeners=INTERNAL://192.168.88.12:9092,EXTERNAL://192.168.100.104:19092
#
advertised.listeners=INTERNAL://192.168.88.12:9092,EXTERNAL://192.168.100.104:19092 inter.broker.listener.name=INTERNAL2. 验证测试
分别在内外网进行验证测试,这里省略。
3. NAT模式下配置
上面用到的Kafka的两个配置参数,一个是listeners,用于指定当前节点监听本机的哪个IP地址,另一个是advertised.listeners,用于指定客户端可以通过哪个IP访问到当前节点。假设机器没有外网网卡(即上服务器是没有eth1网卡的),外网通信地址基于转发或映射出来的IP,那么,我们的Kafka配置就应该改成这样配置。
listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
listeners=INTERNAL://192.168.88.12:9092,EXTERNAL://192.168.88.12:19092
advertised.listeners=INTERNAL://192.168.88.12:9092,EXTERNAL://192.168.100.104:19092
inter.broker.listener.name=INTERNAL参考资料:
https://juejin.cn/post/6893410969611927566
这篇关于kafka集群内外网分流方案——筑梦之路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






