本文主要是介绍SQL性能优化 ——OceanBase SQL 性能调优实践分享(3),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相比较之前的两篇《连接调优》和《索引调优》,本篇文章主要是对先前两篇内容的整理与应用,这里不仅归纳了性能优化的策略,也通过具体的案例,详细展示了如何分析并定位性能瓶颈的步骤。
SQL 调优
先给出性能优化方法和分析性能瓶颈步骤的文字描述:
性能优化的方法
- 开启并行执行等机制(简单),可以参考:《OceanBase 并行执行技术》。这篇博客内容过多(实际应该像性能调优系列拆成多篇发的),从 4.2 版本开始,OB 已经支持了 auto dop,如果用户不熟悉并行度的设置规则,可以设置 parallel_degree_policy 为 AUTO,让优化器帮忙自动选择合适的并行度,推荐使用。auto dop 的相关内容可以直接在上面这篇博客中搜索 parallel_degree_policy 关键字,或者参考官网文档。
- 创建合适的索引(简单),可以参考:《索引调优 —— OceanBase SQL 性能调优系列 1》。
- 调整连接方式(比较简单),可以参考:《连接调优 —— OceanBase SQL 性能调优系列 2》
- 调整连接顺序(难度较大),这里指的是:例如有 t1,t2,t3 三个表做连接, 假设 OB 的优化器认为 t1,t2 两个表先做连接,再与 t3 做连接,是一个比较好的计划。但是实际可能是 t1 和 t3 先做连接,再和 t2 做连接是更优的计划。此时可以通过 hint 告诉优化器正确的连接顺序来优化 SQL 的性能(参考官网文档),在一些复杂场景下,需要丰富的经验支持才能通过调整连接顺序来优化 SQL 执行效率,有兴趣的同学可以自行研究和尝试。
- 检查 OB 是否做了错误的查询改写 / 缺少合适的查询改写机制(难度较大)。
分析性能瓶颈的步骤
- 利用 SQL 执行计划去分析具体哪些步骤(哪几个算子)的执行时间慢。个人经验是可以通过把大 SQL 拆分成小 SQL 去分析这一步。
- 充分利用已有的脚本和工具来简化分析过程。这里我理解主要是通过一些字典视图,例如 oceanbase.GV$SQL_PLAN_MONITOR。
分析 SQL 性能瓶颈的例子
举一个真实的 SQL 性能分析和优化的例子:下面这条 SQL 执行了 2.43 秒,接下来开始分析性能瓶颈并进行优化。

看到优化器生成计划是让 bbtr 表先与 cte 表做 merge join,再与 btr 表做 nest loop join。
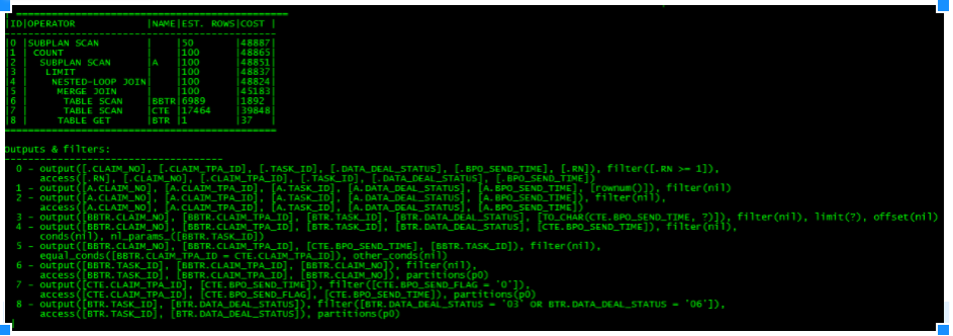
在上面的计划中,从 4 号算子到 8 号算子是三张表的 join 是这个计划最核心的部分,大概率也是性能的瓶颈点,我们先从这里开始分析。
=============================
|ID|OPERATOR |NAME|
-----------------------------
|4 |NESTED-LOOP JOIN | |
|5 |├─MERGE JOIN | |
|6 |│ └─TABLE SCAN |BBTR|
|7 |│ └─TABLE SCAN |CTE |
|8 |└─TABLE GET |BTR |
=============================要分析出计划里哪里是瓶颈,首先得查一下每个表的数据量,先看最内层进行 merge join 的两张表 cte 和 bbtr,merge join 的代价是扫描出 cte 数据的代价 + 扫描出 bbtr 的代价 + 归并的代价:
cte 表在 7 号算子中的过滤条件是 cte.bpo_send_flag = '0',过滤之后返回数据量是 1638 行,扫描耗时 2.13 秒(这个时间明显不太对)。

类似地,bbtr 表的数据在 6 号算子返回的数据量是 40 多万行,没有过滤条件,扫描耗费 0.19 秒。
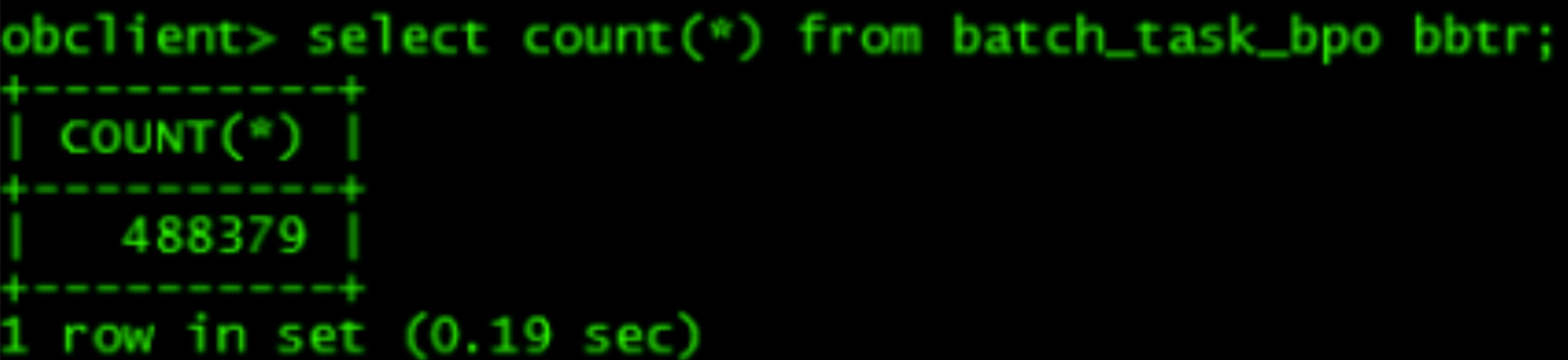
然后上层的 NLJ 要拿 merge join 的结果当做驱动表(左表),对右表 btr 进行 table get。
这条 SQL 一共执行了 2.43 秒,但仅仅是 merge join 中 cte 表的扫描代价就已经高达 2.13 秒了,所以这条 SQL 的瓶颈点就是 cte 表的扫描。
可以看到 cte 表上有一个过滤条件 bpo_send_flag = '0',所以我们可以通过在 cte 表的列 bpo_send_flag 上建一个索引来优化它的查询性能。如果考虑到计划中的 7 号算子还需要拿 cte 表中的 bpo_send_time 列和 claim_tpa_id 列的数据向上吐行,还可以考虑在(bpo_send_flag, bpo_send_time, claim_tpa_id)上创建联合索引来消除索引回表的性能消耗。
创建索引之后的计划预期大概会长这样:
=================================
|ID|OPERATOR |NAME |
---------------------------------
|4 |NESTED-LOOP JOIN | |
|5 |├─MERGE JOIN | |
|6 |│ └─TABLE SCAN |BBTR |
|7 |│ └─TABLE SCAN |CTE(idx)|
|8 |└─TABLE GET |BTR |
=================================假如上面排查下来发现 cte 表的扫描并不是瓶颈,那么应该做进一步的分析。例如尝试去单独去执行 bbtr 和 cte 两个表的连接,查看它的执行结果的行数和 btr 表的行数关系。4 号 NLJ 算子的左支返回的行数(merge join 结果的行)和右支返回的行数(btr 通过 8 号算子中 filter 过滤之后的行)如果没有明显的大小表关系(左支行数 / 右支行数 < 20),则意味着 4 号算子选择 Hash Join 的方式会比选择 NLJ 的方式更优。那么就可以通过使用 hint /*+ leading(bbtr cte btr) use_hash(btr) */ 来修改 4 号算子的连接方式,将 Nested_Loop Join 改成 Hash Join。
hint 和 outline
使用 hint 生成指定计划
官网上写的很详细,这里不再赘述,详见 OB 官网中的 hint 部分:
使用 outline 进行计划绑定
官网上写的很详细,这里不再赘述,详见 OB 官网中的计划绑定部分:
这篇关于SQL性能优化 ——OceanBase SQL 性能调优实践分享(3)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





