本文主要是介绍最新张量补全论文收集【8篇】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1、利用张量子空间先验:增强张量补全的核范数最小化和
2、基于可学习空间光谱变换的张量核范数多维视觉数据恢复
3、用于图像补全的增强型低秩和稀疏 Tucker 分解
4、多模态核心张量分解及其在低秩张量补全中的应用
5、 低秩张量环的噪声张量补全
6、 视觉数据鲁棒张量补全的粗到精两阶段方法
7、 张量-序列格式下三阶张量补全的秩估计
8、具有缺失条目的平滑非负张量因子分解的新惩罚准则
1、利用张量子空间先验:增强张量补全的核范数最小化和
Ge, L., Jiang, X., Chen, L., Liu, X., & Haardt, M. (2024). Leveraging Tensor Subspace Prior: Enhanced Sum of Nuclear Norm Minimization for Tensor Completion. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 7655-7659). Seoul, Korea, Republic of. https://doi.org/10.1109/ICASSP48485.2024.10447654.
摘要:张量补全在信号处理、计算机视觉和生物医学工程中引起了越来越多的关注。利用核范数最小化,张量补全问题可以转化为凸规划,并具有矩阵补全的性质。低秩性质已被广泛应用于张量/矩阵补全。然而,先验子空间信息也可以被利用,但在现有的公式中被忽略,并没有充分发挥其作用。在本文中,我们提出了一个新的框架利用张量子空间先验核范数(SNN)最小化和,它支持一系列张量分解。利用自先验(SP)/非自先验(NSP)的知识,进一步设计一种基于交替方向乘子法(ADMM)的高效算法,可以提高张量补全的性能。大量的数值实验验证了该方法的优越性。


2、基于可学习空间光谱变换的张量核范数多维视觉数据恢复
Liu, S., Leng, J., Zhao, X.-L., Zeng, H., Wang, Y., & Yang, J.-H. (2024). Learnable Spatial-Spectral Transform-Based Tensor Nuclear Norm for Multi-Dimensional Visual Data Recovery. IEEE Transactions on Circuits and Systems for Video Technology, 34(5), 3633-3646. https://doi.org/10.1109/TCSVT.2023.3316279.
摘要:近年来,基于变换的张量核范数(TNN)方法作为一种强大的多维视觉数据(彩色图像、视频和多光谱图像等)恢复工具受到越来越多的关注。特别是基于冗余变换的TNN获得了满意的恢复效果,其中沿谱模式的冗余变换可以显著增强张量的低秩性。但是,由于冗余变换导致的计算开销较大。本文提出了一种可学习的基于空间-光谱变换的多维视觉数据恢复TNN模型,该模型不仅具有较好的低秩能力,而且可以设计伴随的快速算法。更具体地说,我们首先通过沿空间模式的可学习半正交变换将大尺度原始张量投影到小尺度本征张量。其中,半正交变换作为关键的构建块,可以提高空间低秩性,求解小尺度问题,为设计快速算法铺平道路。其次,为了进一步提高低秩性,我们对小尺度本征张量进行沿谱模式的可学习冗余变换。为了解决所提出的模型,我们采用了一种有效的基于邻域交替最小化的算法,该算法具有理论的收敛性保证。在真实世界数据(彩色图像、视频和多光谱图像)上的大量实验结果表明,所提出的方法在评估指标和运行时间方面优于最先进的对比方法。
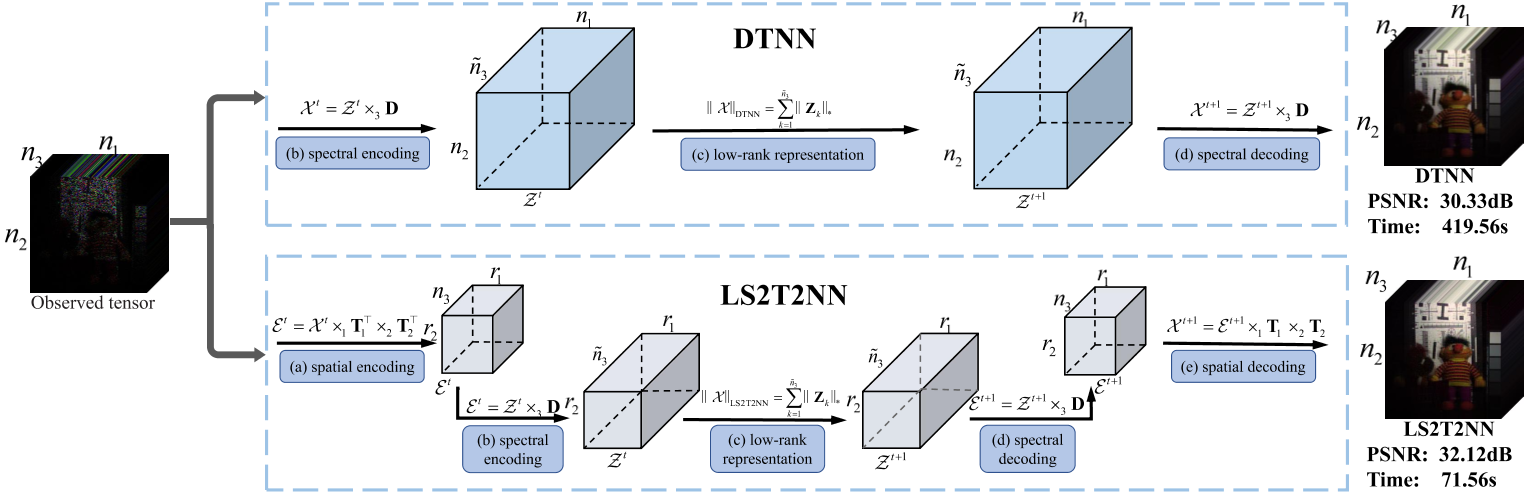
(a)沿空间模态对Xt进行可学习的半正交变换,得到小尺度张量et。(b)利用可学习的冗余变换,沿谱模式对E - t进行谱编码。(c)对Zt的每个额片进行低秩表示操作。(d)利用可学习的冗余变换,沿谱模式对Zt+1进行谱解码。(e)利用可学习的半正交变换,沿空间模式对et +1进行空间解码。
3、用于图像补全的增强型低秩和稀疏 Tucker 分解
Gong, W., Huang, Z., & Yan, L. (2024). Enhanced Low-Rank and Sparse Tucker Decomposition For Image Completion. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2425-2429). Seoul, Korea, Republic of. https://doi.org/10.1109/ICASSP48485.2024.10448445.
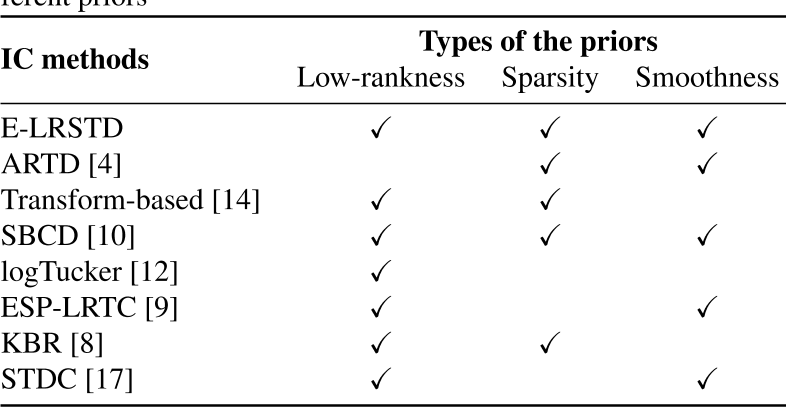
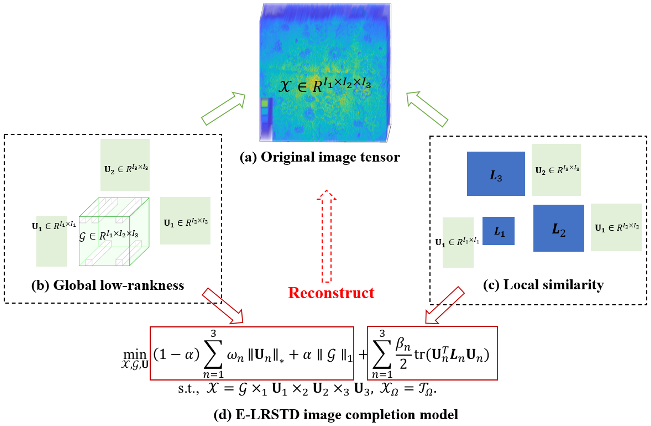
摘要:低秩张量测量的最新进展解决了张量补全的挑战,特别是在图像补全(IC)任务中。然而,目前的低秩通常是基于展开矩阵的秩和。此外,它忽略了局部相似度或对图像数据进行了过度平滑正则化,这在高级损坏恢复中可能是不可靠的。本文提出了一种新的基于塔克的模型来考虑成像中的全局和局部信息。其中,利用加权因子矩阵秩和核心张量稀疏度对全局低秩进行编码,利用图正则化对局部相似度进行表征。本文提出了一种易于求解子问题的线性化交替方向法(LADM)。大量的实验证明了我们的建议的准确性,即使在极端情况下,如99%的缺失场景。
4、多模态核心张量分解及其在低秩张量补全中的应用
Zeng, H., Xue, J., Luong, H. Q., & Philips, W. (2023). Multimodal Core Tensor Factorization and its Applications to Low-Rank Tensor Completion. IEEE Transactions on Multimedia, 25, 7010-7024. https://doi.org/10.1109/TMM.2022.3216746.
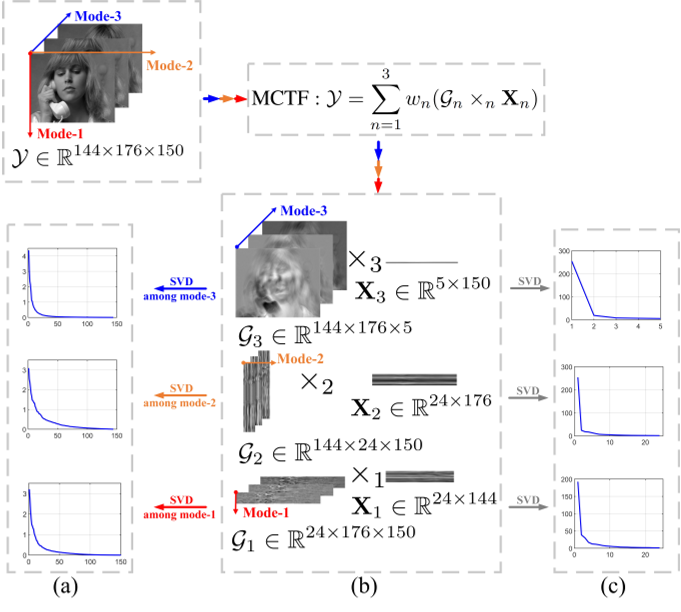
摘要:低秩张量补全在计算机视觉和机器学习中有着广泛的应用。本文提出了一种新的多模态核心张量分解(MCTF)方法,该方法结合了张量低秩测度及其较好的非凸松弛形式(NC-MCTF)。所提出的模型对Tucker和T-SVD提供的一般张量的低秩洞察进行编码,因此有望同时在多个方向上对光谱低秩进行建模,并基于少量观测条目准确地恢复本征低秩结构的数据。在此基础上,研究了MCTF和NC-MCTF正则化最小化问题,设计了一种有效的块连续上界最小化(BSUM)算法。从理论上证明了所提模型生成的迭代收敛于坐标极小集。这个高效的求解器可以将MCTF扩展到各种任务,如张量补全。包括高光谱图像、视频和MRI完成的一系列实验证实了该方法的优越性能。

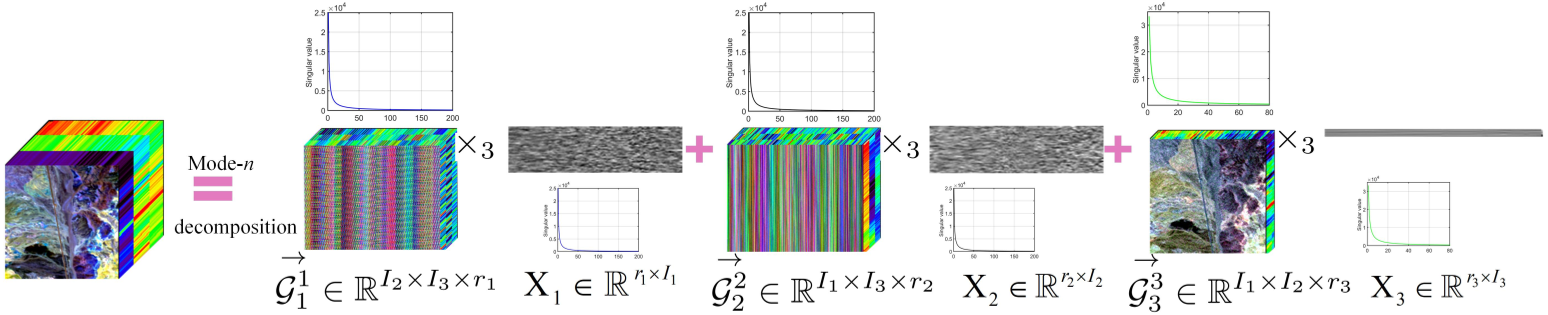


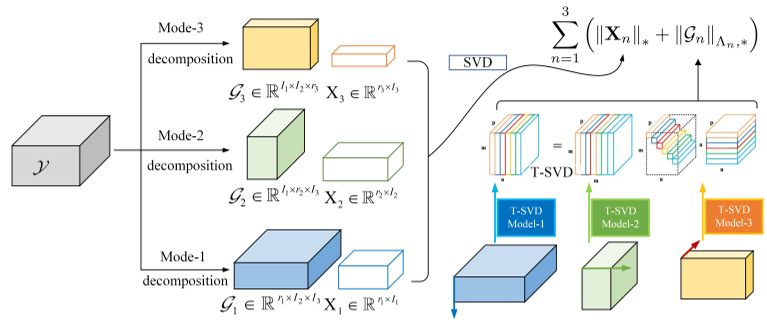
5、 低秩张量环的噪声张量补全
Qiu, Y., Zhou, G., Zhao, Q., & Xie, S. (2024). Noisy Tensor Completion via Low-Rank Tensor Ring. IEEE Transactions on Neural Networks and Learning Systems, 35(1), 1127-1141. https://doi.org/10.1109/TNNLS.2022.3181378
摘要:张量补全是不完整数据分析的基本工具,其目标是从部分观测中预测缺失的条目。然而,现有的方法往往会明确或隐含地假设观测条目是无噪声的,从而为准确恢复缺失条目提供理论上的保证,这在实践中具有很大的局限性。
为了弥补这一缺陷,本文提出了一种新的噪声张量补全模型,弥补了现有研究在处理高阶和噪声观测退化方面的不足。具体而言,采用张量环核范数(TRNN)和最小二乘估计量分别对底层张量和观测项进行正则化。此外,给出了估计误差的非渐近上界来描述所提估计器的统计性能。为了解决具有收敛保证的优化问题,提出了两种有效的算法,其中一种算法专门针对大规模张量的优化问题,在异构张量分解框架中,将原始张量的TRNN的最小化等价地替换为更小的TRNN的最小化。在合成数据和实际数据上的实验结果表明,与现有的张量补全模型相比,该模型在恢复有噪声的不完全张量数据方面是有效的。

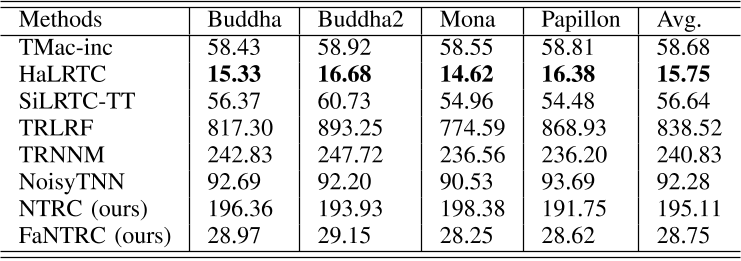
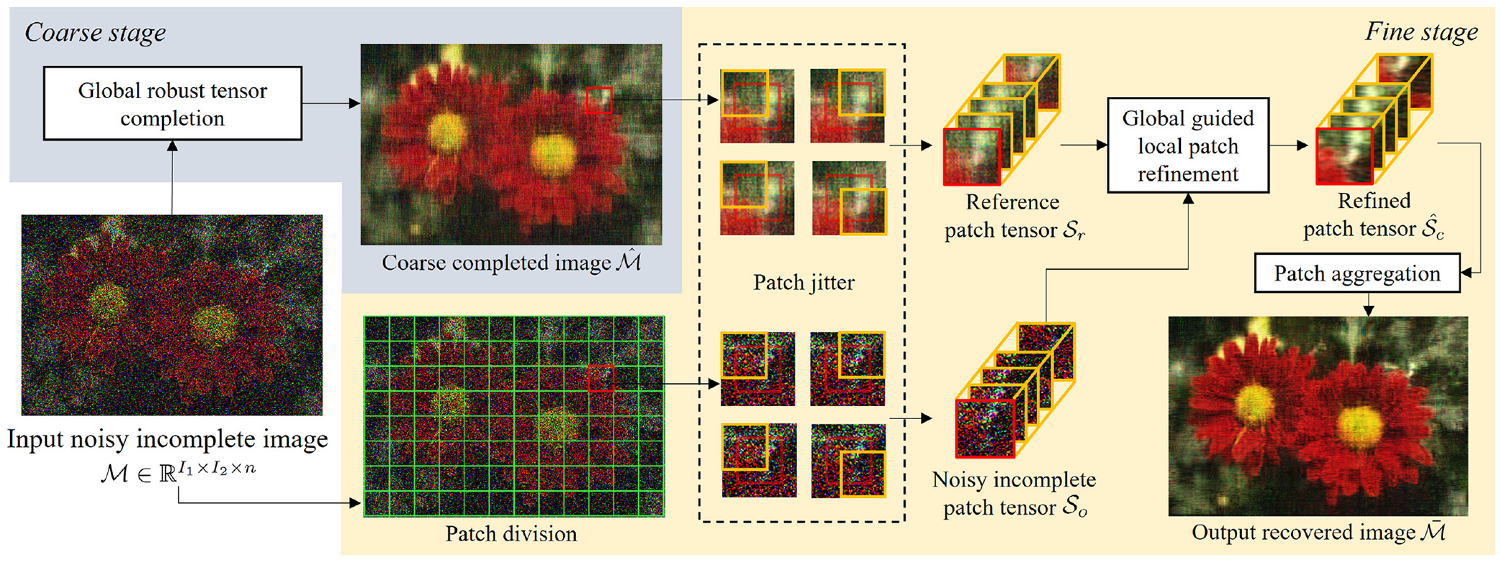
6、 视觉数据鲁棒张量补全的粗到精两阶段方法
He, Y., & Atia, G. K. (2024). Coarse to Fine Two-Stage Approach to Robust Tensor Completion of Visual Data. IEEE Transactions on Cybernetics, 54(1), 136-149. https://doi.org/10.1109/TCYB.2022.3198932
摘要:张量补全是从部分观察到的数据中估计高阶数据的缺失值的问题。由于普遍存在的异常值导致的数据损坏对传统的张量补全算法提出了重大挑战,这促使了鲁棒算法的发展,以减轻异常值的影响。然而,现有的鲁棒方法大多假设异常值是稀疏的,而这在实践中可能并不成立。在本文中,我们开发了一种两阶段的鲁棒张量补全方法,以应对具有大量粗糙污染的视觉数据的张量补全问题。提出了一种新的从粗到细的框架,该框架使用全局粗略补全结果来指导局部补丁的细化过程。为了有效减轻大量异常值对张量恢复的影响,我们开发了一种基于M估计的新鲁棒张量环恢复方法,该方法可以自适应地识别异常值并在优化中减轻其负面影响。实验结果表明,所提出的方法在张量补全方面的性能优于最新的鲁棒算法。
7、 张量-序列格式下三阶张量补全的秩估计
Vermeylen, C., Olikier, G., Absil, P.-A., & Van Barel, M. (2023). Rank Estimation for Third-Order Tensor Completion in the Tensor-Train Format. In 2023 31st European Signal Processing Conference (EUSIPCO) (pp. 965-969). Helsinki, Finland. https://doi.org/10.23919/EUSIPCO58844.2023.10289827
摘要:对于有界张量列秩的三阶张量变化张量补全问题,提出了一种求秩上界的充分值的数值方法。该方法的灵感来自于Kutschan(2018)导出的切锥参数化。给出了一个相关的低秩张量逼近问题上界的充分性证明,并定义了一个估计秩,将结果推广到低秩张量补全问题。在合成数据上的实验表明,该方法具有较好的鲁棒性,如对数据噪声的抑制能力。
8、具有缺失条目的平滑非负张量因子分解的新惩罚准则
Durand, A., Roueff, F., Jicquel, J.-M., & Paul, N. (2024). New Penalized Criteria for Smooth Non-Negative Tensor Factorization With Missing Entries. IEEE Transactions on Signal Processing, 72, 2233-2243. https://doi.org/10.1109/TSP.2024.3392357
摘要:张量分解模型在化学计量学、心理计量学、计算机视觉、通信网络等领域有着广泛的应用。现实生活中的数据收集经常会出现错误,导致数据丢失。在这里,我们的重点是理解这个问题应该如何处理非负张量分解。我们研究了在缺少某些项的情况下用于非负张量分解的几个准则。特别地,我们展示了平滑惩罚如何补偿缺失值的存在,以确保最优的存在。这导致我们提出了新的准则与有效的数值优化算法。数值实验证明了我们的观点。


这篇关于最新张量补全论文收集【8篇】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






