本文主要是介绍排序-希尔排序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
希尔排序属于那种没有了解过的直接看代码一脸懵逼的,
所以同学们尽量不要直接看代码,仔细阅读本篇博客内容。
插入排序本来算是一个低效排序,
一次只可以挪动一个数据,
但是,它的强来了!!!
---Donald Shell(希尔)

对插入排序进行了优化
将插入排序提升了不止一个档次
甚至可以和快速排序平起平坐!
基本思想
先选定一个整数,把待排序文件中所有记录分成个
组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工
作。当到达=1时,所有记录在统一组内排好序。希尔排序法又叫做缩小增量法。
其本质就是对固定间隔组成的序列进行插入排序,
然后此固定间距步步缩小,最后进行直接插入排序
先进行预排序,再进行直接插入排序
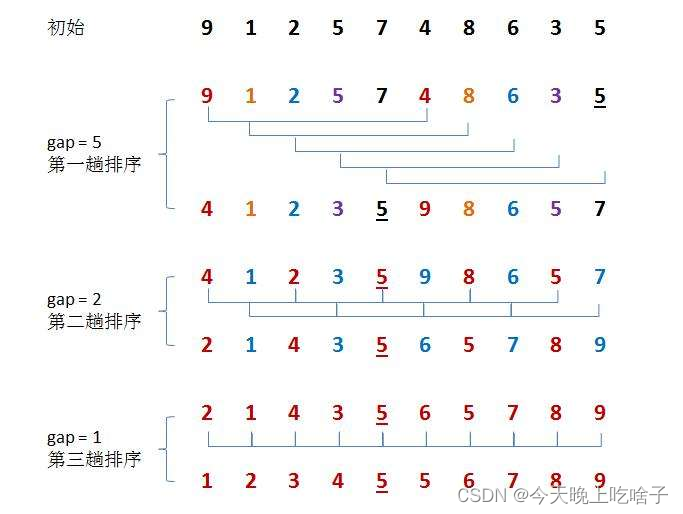
根据上图,明显看出,进行预排序过后的数列,已经有了基本的顺序,
大大缩小了大数字在前,小数字在后还需要一个一个挪动的尴尬局面
代码实现
void ShellSort(int* a, int n)
{
// 1、gap > 1 预排序
// 2、gap == 1 直接插入排序int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1; // +1可以保证最后一次一定是1
// gap = gap / 2;
for (int i = 0; i < n - gap; ++i)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
这是多组同时进行间隔gap排序
gap的取值
gap的取值方法有很多种.
但是每一种gap的取值都满足:
先大后小原则
也就是我们的预排序不止排序一次
gap会由大变小,常见的取值有:
gap=n/2 (n为数组长度)gap=n/3 (n为数组长度)
同时取值时一定要确保最后一个值为1收尾
不过对于gap到底取什么值最合适,到现在也没有定论,因为快排的横空出世,再怎么研究希尔也比不过快排,也就没了意义
特性总结
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,
可以达到优化的效果。我们实现后可以进行性能测试的对比。
3. 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的
希尔排序的时间复杂度都不固定:《数据结构(C语言版)》--- 严蔚敏
《数据结构-用面相对象方法与C++描述》--- 殷人昆
4. 稳定性:不稳定


这篇关于排序-希尔排序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![O(n)时间内对[0..n^-1]之间的n个数排序](/front/images/it_default.gif)
