本文主要是介绍[学习笔记](b站视频)PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】(ing),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
视频来源:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
前面P1-P5属于环境安装,略过。
5-6.Pytorch加载数据初认识
数据文件: hymenoptera_data
# read_data.py文件from torch.utils.data import Dataset
from PIL import Image
import osclass MyData(Dataset):def __init__(self, root_dir, label_dir):self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir, self.label_dir)self.img_path = os.listdir(self.path)def __getitem__(self, idx):img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)img = Image.open(img_item_path)label = self.label_dirreturn img, labeldef __len__(self):return len(self.img_path)root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)train_dataset = ants_dataset + bees_dataset
1.在jupytrer notebook中,可以使用
help(xxx)或者xxx??来获取帮助文档。
2.__init__方法主要用于声明一些变量用于后续类内的方法。
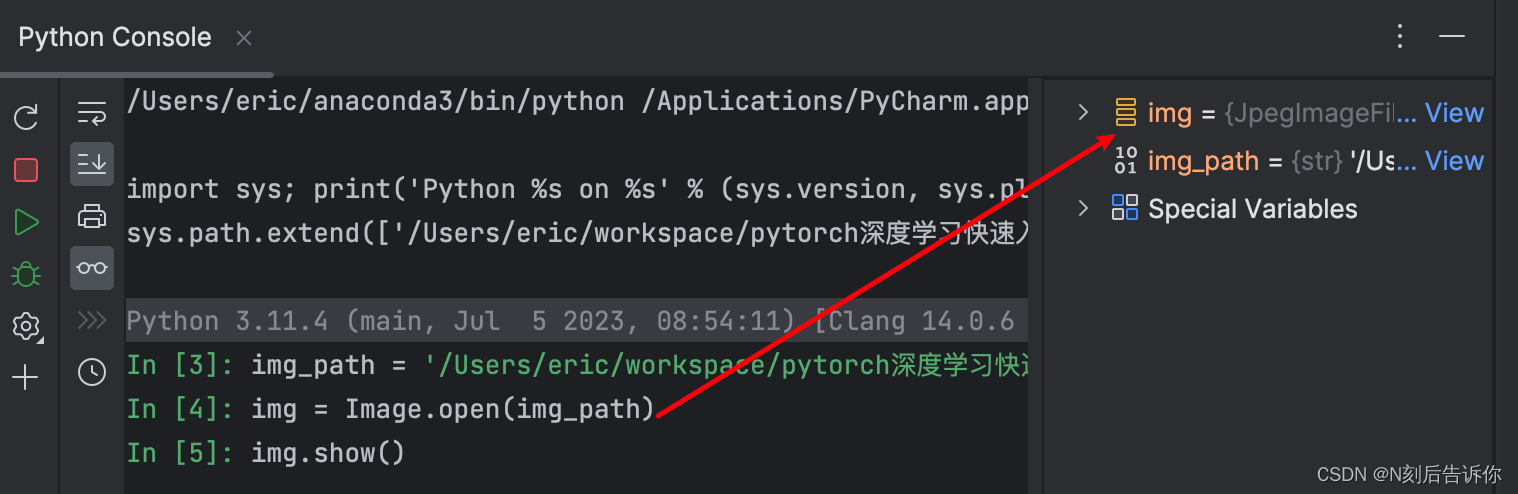
3.python console可以显示变量的值,所以建议使用它来进行调试。
x.使用os.path.join()来拼接路径的好处是:适配windows和linux。
7-8.TensorBoard的使用
add_scalar
# tb.pyfrom torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("logs")for i in range(100):writer.add_scalar("y=x", i, i)writer.close()
不要以
test+其他字符作为.py文件的文件名(test.py是可以的),这会导致报empty suite(没有测试用例)。
详细参考:笔记19:在运行一个简单的carla例程时,报错 Empty Suite
SummaryWriter(log_dir, comment, ...)实例化时,log_dir是可选参数,表示事件文件存放地址。comment也是可选参数,会扩充事件文件的存放地址后缀。
add_scalar(tag, scalar_value, global_steap)调用时,tag是标题(标识符),scaler_value是y轴数值,gloabl_step是x轴数值。
# shell
tensorboard --logdir=logs --port=6007
一般上述命令打开6006端口,但如果一台服务器上有好几个人打开tensorboard,会麻烦。所以
--port=6007可以指定端口。
如果两次写入的scalar写入的tag是相同的,那么两次scalar会在一个图上。
add_image
# P8_Tensorboard.py
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as npwriter = SummaryWriter("logs")
image_path = 'dataset/train/ants/0013035.jpg'
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)writer.add_image('test', img_array, 1, dataformats='HWC')writer.close()
add_image(tag, img_tensor, global_steap)调用时,img_tensor需要是torch.Tensor, numpy.ndarray或string等。
add_image默认匹配的图片的大小是(3, H, W),如果大小是(H, W, 3),需要添加参数dataformats='HWC'
9-13.Transforms的使用
# P9_Transformsfrom PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsimg_path = 'dataset/train/ants/0013035.jpg'
img = Image.open(img_path) # 得到PIL类型图片
# 这里也可以通过cv2.imread()读取图片,转化为nd.arraywriter = SummaryWriter('logs')tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) # ToTensor支持PIL、nd.array图片类型作为输入writer.add_image('Tensor_img', tensor_img)writer.close()
对于一个模块文件,如transforms.py,可以借助pycharm的Structure快速了解其中定义的class类。
pip install opencv-python之后才能import cv2
Image.open()返回的是PIL类型的图片。cv2.imread()返回的是nd.array类型的图片。

常见的Transforms
类里面的__call__方法的作用是:使得实例化对象可以像函数一样被调用。
ToTensor
作用:将PIL,nd.array转化为Tensor类型。
这个对象的输入可以是PIL图像,也可以是np.ndarray。
Normalize
作用:对tensor格式的图像做标准化。需要多通道的均值和多通道的标准差。
这个对象的输入必须是tensor图像。
Resize
作用:变更大小。如果size的值是形如(h, w)的序列,则输出的大小就是(h, w)。如果size的值是一个标量,则较小的边长变成该标量,另一个边长成比例缩放。
这个对象的输入可以是PIL图像,也可以是np.array
(这意味着cv2.imread得到的ndarray也可以作为输入)。(之前的版本只能是PIL图像)
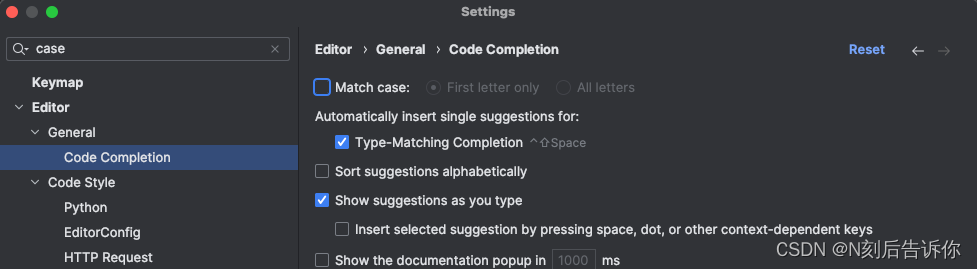
设置大小写不敏感的代码补缺:通过搜索settings->Editor->General->Code Completion,取消对Match Case的勾选
Compose
作用:组合各种transforms.xx
RandomCrop
作用:随机裁剪
代码实现
# P9_Transforms.pyfrom PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsimg_path = 'dataset/train/ants/0013035.jpg'
img = Image.open(img_path)writer = SummaryWriter('logs')# ToTensor
trans_totensor = transforms.ToTensor()
tensor_img = trans_totensor(img) # ToTensor支持PIL图片类型作为输入
writer.add_image('Tensor_img', tensor_img)# Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(tensor_img) # 标准化
writer.add_image('Normalize', img_norm)# Resize
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> resize -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image('Resize', img_resize, 0)# Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image('Resize', img_resize_2, 1)# RandomCrop
trans_random = transforms.RandomCrop(50)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):img_crop = trans_compose_2(img)writer.add_image('RandomCrop', img_crop, i)writer.close()
总结:
主要关注输入和输出。
多看官方文档
关注方法需要的参数
14.torchvision中的数据集使用
本节介绍如何将torchvision的数据集和transforms结合起来。
# P10_dataset_transformsimport torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsdataset_transform = transforms.Compose([transforms.ToTensor()])train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True
)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True
)writer = SummaryWriter("p10")
for i in range(10):img, target = test_set[i]writer.add_image("test_set", img, i)writer.close()
15.DataLoader的使用
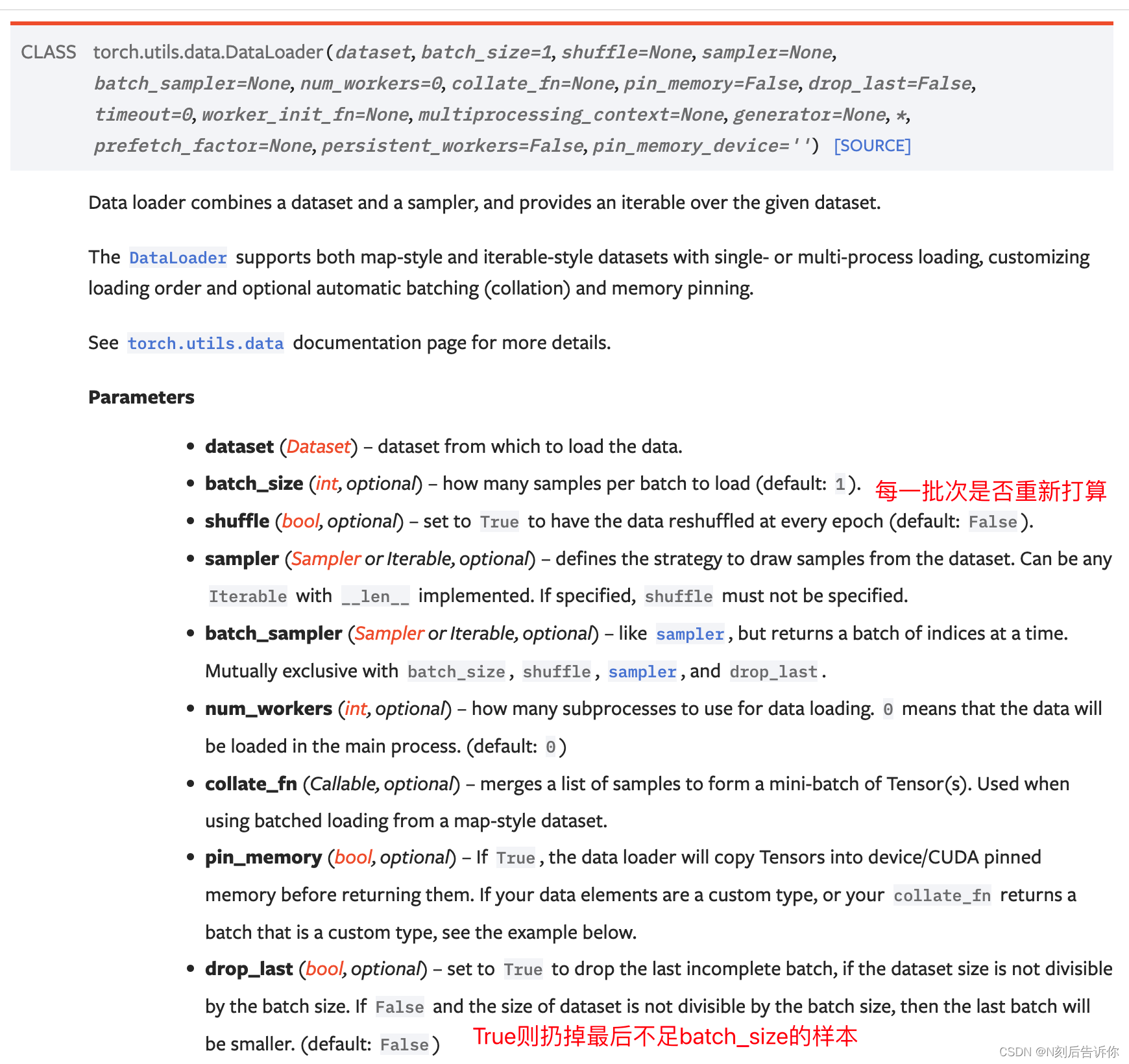
参考资料:torch.utils.data.DataLoader
# dataloaderimport torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWritertest_data = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor())test_loader = DataLoader(test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)# 测试数据集中第一张图片及target
img, target = test_data[0]
# print(img.shape) # (3, 32, 32)
# print(target) # 3writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:imgs, targets = data# print(imgs.shape) # (4, 3, 32, 32)# print(targets) # [2, 7, 2, 2]writer.add_images('test_data', imgs, step) # 多张图片用add_imagesstep += 1writer.close()
16.神经网络的基本骨架-nn.Module的使用

按照上面的模版,定义模型名,继承Module类,重写forward函数。下面写一个例子。(这一节比较简单)
import torch
from torch import nnclass Tudui(nn.Module):def __init__(self, *args, **kwargs) -> None:super().__init__(*args, **kwargs)def forward(self, input):output = input + 1return outputtudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
17.卷积
第17个视频主要通过torch.nn.functional.conv2d来介绍stride和padding。这里略过。
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True
)dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super().__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return xtudui = Tudui()
for data in dataloader:imgs, targets = dataoutput = tudui(imgs)print(imgs.shape)print(output.shape)
这篇关于[学习笔记](b站视频)PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】(ing)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



