本文主要是介绍创新实训2024.06.02日志:SSE、流式输出以及基于MTPE技术的MT-SSE技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. Why SSE?
之所以要做SSE,是因为在开发、调试以及使用我们开发的软件时,我发现消息的响应时间会很长。之所以会这样最主要的原因是,MTPE这项基于CoT的技术,本质上是多个单一的提示工程有机地组合在一起对大模型生成回答的能力进行增强。多步提示工程就延长了大模型思考、整理、融合检索到的知识的时间(也就是说我们拿时间换来了更强的大模型的能力)
1.1. 技术选型
因此我一直在探索一种能大幅缩短大模型响应时间的方法。最终我将目光投向了两种现有的比较成熟的技术:
- websocket:ws协议是一种基于长连接的协议。它能够在客户端与服务端之间建立起一条长连接,服务端不必等待客户端的请求,可以主动向客户端发送消息。ws协议打破了web服务中原有的请求-响应模式。客户端与服务端本质上是对等的。
- SSE:全称Server Sent Event。SSE本质上也是属于请求-响应模式的,但他支持基于事件的响应,当服务端产生一个事件,他会打断当前服务端的程序,向客户端产生一个响应。但服务端本身并没有能力在不具备一个前置请求的情况下向客户端主动发送消息。


1.2. 为什么SSE更好
那么我们的web应用适合使用哪种技术呢?在AI领域有一条很重要的原则:
用户体验:设计提示时要考虑用户体验,确保对话流畅自然,避免让用户感到困惑或沮丧。
那么向websocket这种能够让服务器向客户端主动发送消息的协议,就不太适用于这条原则。因为开发人员需要考虑到更多的安全性问题来保证服务端不会在用户并没有提出一个请求的时候向客户端发送消息(大模型对于某一问题的回答)。
而SSE更适合的原因是:SSE的基于事件的响应机制完美契合了大模型生成回答的过程。我们指导LLM生成回答时的单位是token,当大模型产生一个token,我们可以认为是出发了一个事件,并将这个token利用SSE机制发送到客户端。
可以说,SSE就是LLM及其软件应用最好的网络通讯手段。而且SSE并不建立一个直到某一方(服务端/客户端)退出的长连接,而是在请求-响应后即断开连接,这使得我们的服务器在维护通讯连接时的开销变得很低,能够容纳更多的并发量。
2. SSE的效果以及实现
2.1. 视觉效果与响应速度的提升
那么使用SSE,我们想做到一种什么效果呢?这一点现在大部分已有的大模型应用中我们可以找到答案,例如kimi:
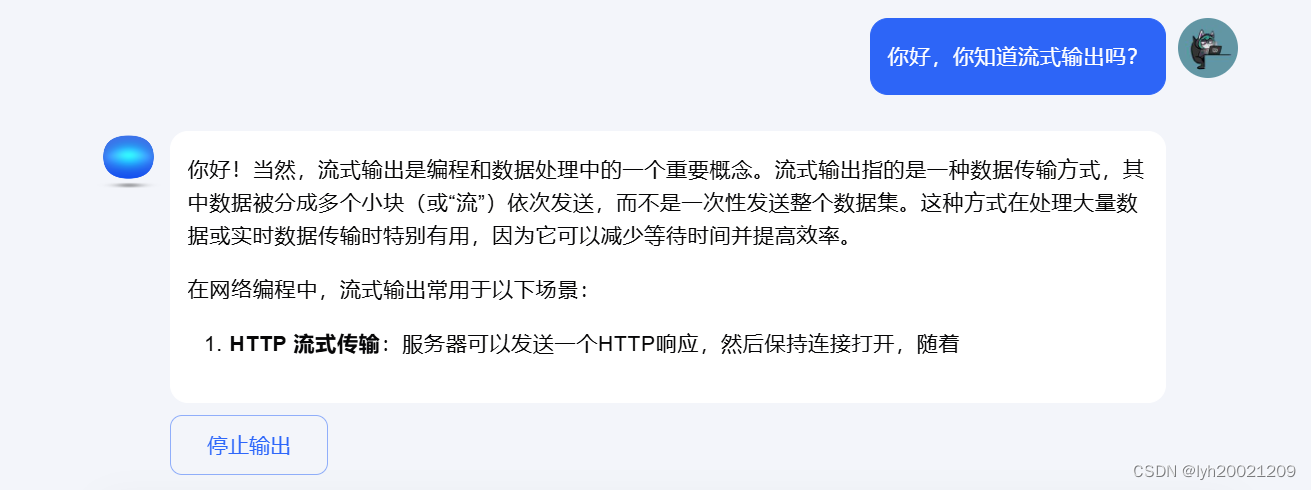
在你向它抛出一个问题时,它会逐字地把生成地回答返回给你。正如同图中它对流式应用的介绍一样:“数据被分成多个小块(或”流“)依次发送,而不是一次性发送整个数据集。这种方式在处理大量数据或试试数据传输时特别有用,因为它可以减少等待时间并提高效率。”
这样的好处是:
- 用户可以提前看到响应的部分内容并开始阅读,减少阅读和理解大模型回答的时间。
- 假设大模型生成第一个token的时间是p,大模型生成完整回答的时间是q,响应返回到客户端并进行回显的时间是r,那么SSE流式输出的响应时间为p,而非流式输出的响应时间为p+q+r。利用SSE进行流式输出,可以将实时响应时间缩短(q+r)的时间,这一点尤其在生成长文本时效果显著,因为生成长文本的代价q将会非常大。
2.2. 何以实现?
这里我以之前我开发过的知识库对话为例,讲解如何落地实现SSE。
对于之前的响应,我采用的是python的requests库:
return await request(url=KB_CHAT_ARGS["url"], request_body=request_body, prefix="data: ")当大模型的所有回答结束后,内核的web接口将返回完整的大模型回答。随后回显到客户端。
现在我们要做的是,大模型每生成一个token,就触发一次响应时间,服务端把当前生成的token返回到客户端。
基于迭代器:AsyncIterable的响应
Starlette是支持FastAPI这一python web框架的底层组件之一,它和Pydantic、Uvicorn并列为FastAPI的三大开源合作社区。在Starlette中,提供了这么一个响应类:
class StreamingResponse(Response):body_iterator: AsyncContentStream里面的其他函数我们就不看了,光看这个成员变量已经能说明一些事情了。body_iterator,本质上是对响应体的遍历,而AsyncContentStream类支持对于响应的Content的异步流,也就是说,所有的响应的”数据块“,或者说响应流,会以一个迭代器的方式存在。
那么我们要做的,就是提供一种对这个迭代器遍历的逻辑(对于每一个”数据块“,我们都要做什么事情),并将这个函数句柄传递给StreamingResponse,这样就能实现用户自定义的、对于响应流的处理逻辑了。
获取响应流的迭代器
现在我们知道了如何对响应流的迭代器进行处理了,那么目前的重中之重就是获取这个迭代器。这一点,我们可以通过aiohttp这一python的依赖库,来制造一个异步http会话,并对服务端提供的接口进行请求:
async def forward_request_to_kernel(url: str, request_body: dict) -> AsyncIterable:async with ClientSession() as session:async with session.post(url, json=request_body) as response:if response.status != 200:raise Exception(f"Failed to get response from knowledge base: {response.text()}")async for chunk in response.content:line = chunk.decode()if line.startswith("data: "):# 提取data字段后面的内容,并去除尾部的换行符json_data = line[len("data: "):].strip()# 产生JSON数据yield json.loads(json_data)这里我们基于aiohttp.ClientSession的工厂类创建一个实例session,随后调用其中的post/get/put/delete等等方法,这个根据服务端接口的请求方式来就行。
对于响应的Content,这里我是直接处理成json了。而在python中,yield 是一个关键字,用于在函数中产生一个值,同时记住上一次的执行状态。使用 yield 的函数被称为生成器(generator)。生成器是一种特殊的迭代器,它们用于在迭代操作中逐个产生元素,而不是一次性产生所有元素。
因此我借助于yield关键字,将所有json对象放入了最终返回的AsyncIterable的迭代器中,之后的处理函数只要逐个的从这个迭代器中取值即可。
大模型响应的流式输出的处理逻辑
对于迭代器中的每个json元素,我们直接响应给客户端即可:
async def generate_sse():async for data in forward_request_to_kernel(url, request_body):event_data = json.dumps(data)yield f"{event_data}\n\n"设置响应流处理逻辑回调句柄
最后,只需要在StreamingResponse类的实例初始化时,设置上这个处理逻辑,响应类就会知道应该以何种处理逻辑处理响应了。
response = StreamingResponse(generate_sse(), media_type="text/event-stream")response.headers["Cache-Control"] = "no-cache"response.headers["Connection"] = "keep-alive"视觉效果
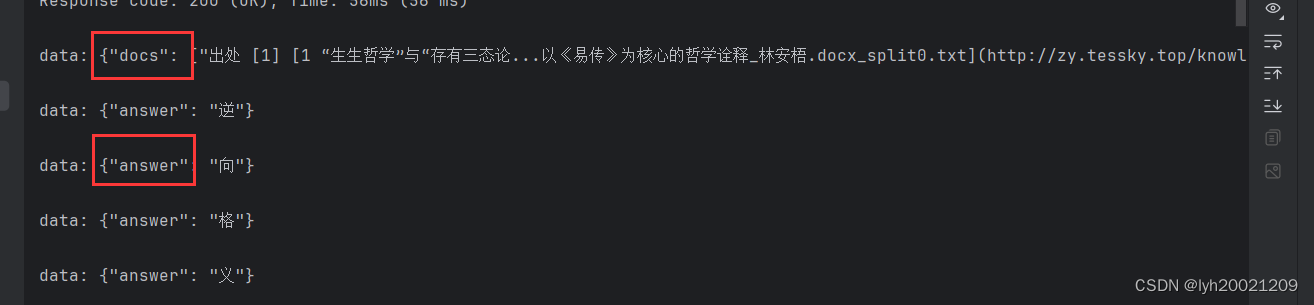
可以看到,docs被先行返回,随后返回的是各个token。
3. 基于MTPE技术的MT-SSE技术
3.1. MTPE技术对于大模型响应速度的减益
在之前的一篇有关大模型能力增强的博客中,我提到了一种基于CoT(由Google AI团队提出的idea)的MTPE(Multi-Turn Prompt Engineering)技术:创新实训2024.05.28日志:记忆化机制、基于MTPE与CoT技术的混合LLM对话机制-CSDN博客
这项技术可以很好地提升大模型的回答的质量。但缺点是响应时间变得更长。如下图所示:
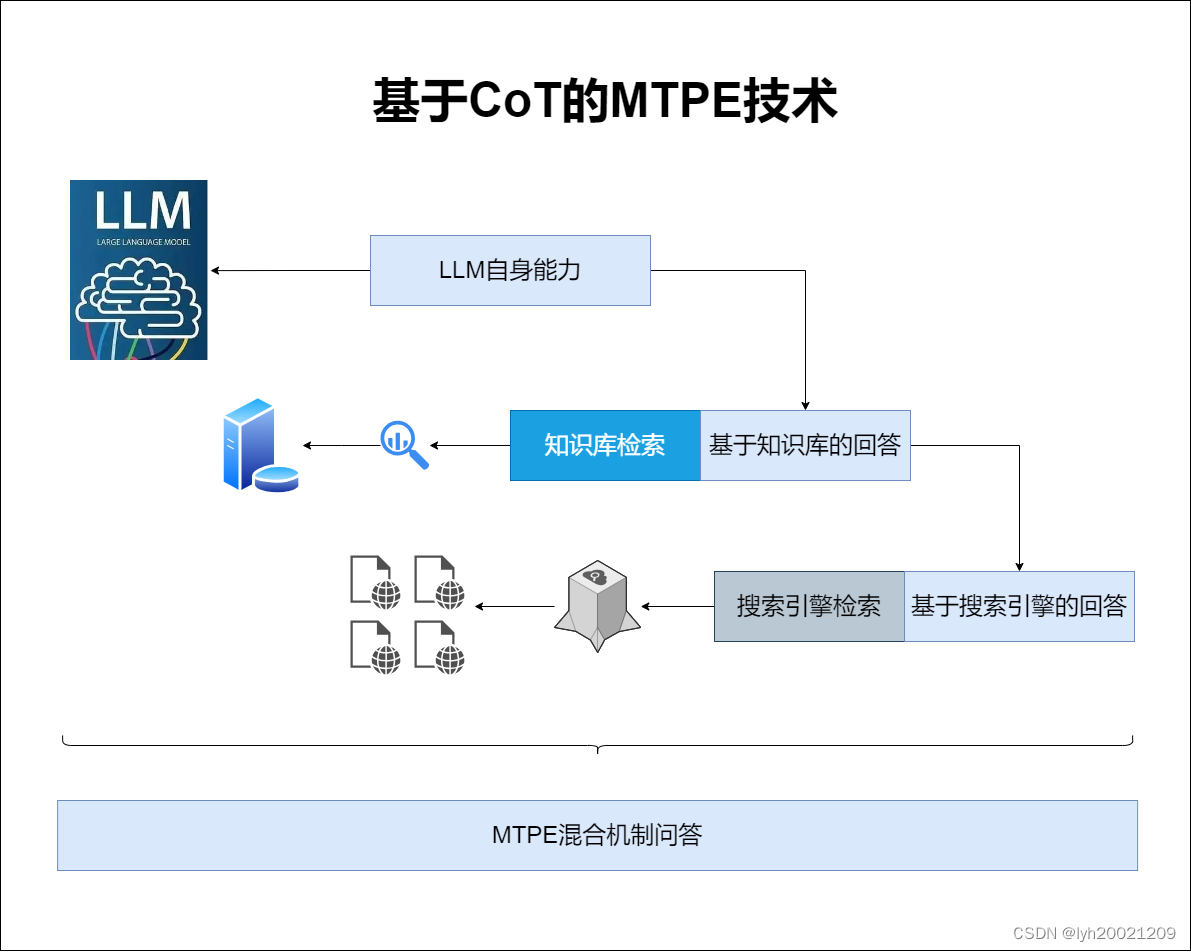
MTPE的四个阶段
在我们的项目架构中,MTPE被分为了四个阶段:
- 第一阶段:LLM自身能力问答阶段。此时仅仅与微调训练过后的LLM本身进行对话。
- 第二阶段:知识库问答阶段。此时为LLM接入知识库,根据检索到的知识进行问答
- 第三阶段:搜索引擎问答阶段。此时为LLM接入搜索引擎,允许检索互联网上的资源进行参考。
- 第四阶段:融合阶段。此时将前三阶段的问答作为Prompt与History,再次让LLM进行融合、整理、回答。
我们可以看到,在MTPE的过程中,回答阶梯式地渐增、完善。而渐增和完善的过程需要时间。这么一套增强、优化下来,用户可能已经等的不耐烦了。如果某一两个问题响应时间那还好,但如果个个问题响应时间都很长,那么很可能会因此流失用户。
3.2. 基于MTPE技术的MT-SSE技术
MT-SSE的idea
基于MTPE技术,我们提出了MT-SSE这项对于SSE机制增强的技术,用来大幅缩短大模型的响应时间。
可以注意到,在知识库检索和搜索引擎检索的过程中,会产生一些检索结果,并根据这些检索结果生成回答。
那么在生成并融合问答的同时,我们可以把这些检索结果通过SSE先行响应给用户,让用户能看到一些相关知识或者是网页,更好地帮助用户解决问题的同时,也更快地响应了用户的问题。如下图所示:
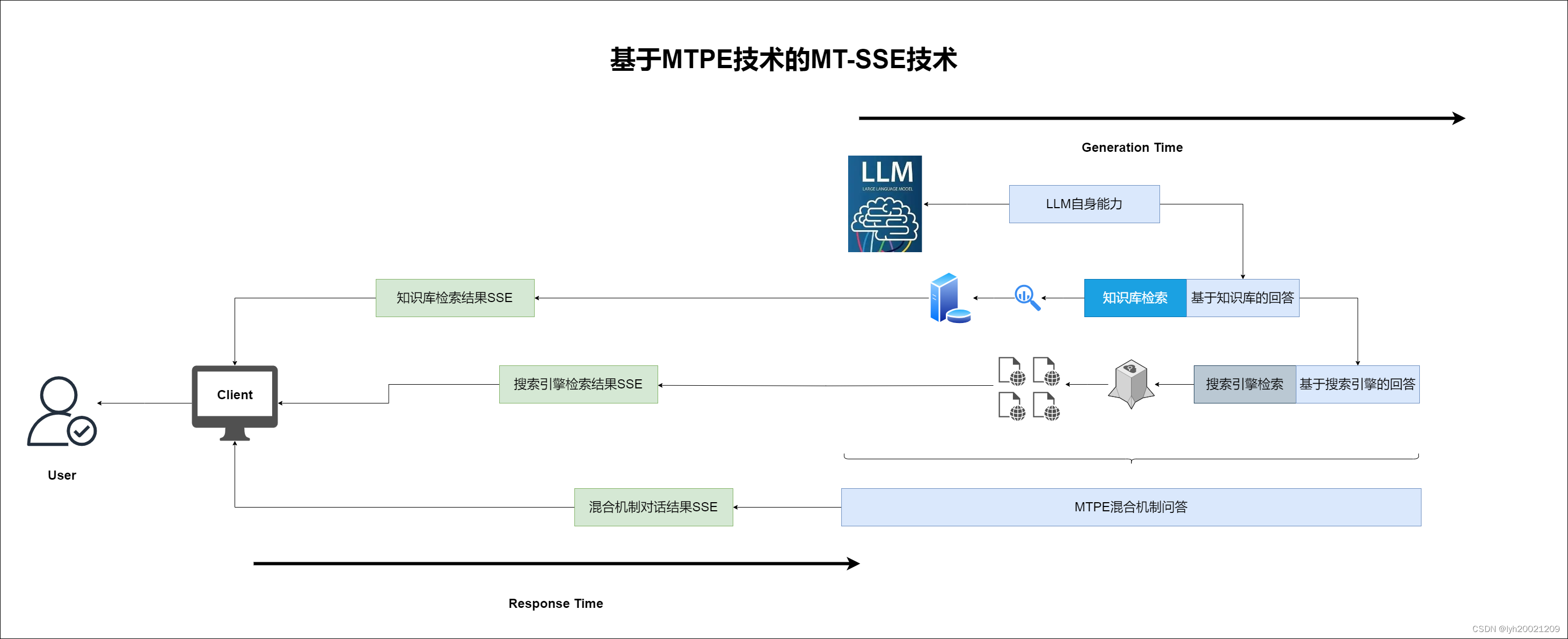
- 在知识库问答阶段,我们加入了对知识库检索结果的sse响应
- 在搜索引擎问答阶段,我们加入了对搜索引擎检索结果的sse响应
- 在最终混合机制回答阶段,我们加入了对大模型增强回答的sse响应
也就是说,原先全部都要等到第四阶段才能响应的结果,现在最早在第二阶段开始就可以得到响应了。
MT-SSE技术的落地实现
首先我们没必要对第一阶段的结果进行SSE。因为这一阶段的回答也不会响应给用户。
# 先请求大模型以自身能力给出解答llm_response = await request_llm_chat(LLMChat(query=mc.query, conv_id=mc.conv_id))if not llm_response["success"]:return BaseResponse(code=500, msg="大模型请求失败", data={"error": f'{llm_response["error"]}'})到了第二阶段,也即MT-SSE的第一阶段,属于知识库问答。
对于知识库对话,向量知识库和大模型会给出两个响应:
- key为docs的向量数据库检索结果
- key为answer的大模型生成的对话
以下代码来自于内核的knowledge_base_chat接口:
if stream:yield json.dumps({"docs": source_documents}, ensure_ascii=False)async for token in callback.aiter():# Use server-sent-events to stream the responseyield json.dumps({"answer": token}, ensure_ascii=False)因此我们要做的就是如果是docs,那么直接响应给客户端,如果是answer,那么保存下来,作为混合机制问答时的模板:
async def generate_multi_turn_sse():# ... 其他代码async for data in forward_request_to_kernel(KB_CHAT_ARGS["url"], kb_request_body):if "docs" in data:event_data = json.dumps(data)kb_docs = data# print(kb_docs)yield f"{event_data}\n\n"elif "answer" in data:kb_response["data"]["answer"] = kb_response["data"]["answer"].join(data["answer"])对于混合机制问答,首先我们生成prompt模板,随后请求大模型,然后将结果再次sse到客户端:
# 生成prompt模板prompt = get_mix_chat_prompt(question=mc.query, history=await gen_history(mc.conv_id),answer1=llm_response["data"]["text"], answer2=kb_response["data"]["answer"],answer3="") # answer3=online_llm_response["data"]["answer"]# 请求大模型mix_request_body = {"query": prompt,"conversation_id": mc.conv_id,# "history_len": CHAT_ARGS["history_len"],"history_len": -1,"model_name": CHAT_ARGS["llm_models"][0],"temperature": CHAT_ARGS["temperature"],"prompt_name": mc.prompt_name,"stream": True}ma = ""async for data in forward_request_to_kernel(CHAT_ARGS["url"], mix_request_body):event_data = json.dumps(data)ma = ma + data["text"]yield f"{event_data}\n\n"最后,把这次的问答记录到数据库:
# 确保问题和回答原子性地入库with record_lock:add_record_to_conversation(mc.conv_id, mc.query, False)add_record_to_conversation(mc.conv_id, json.dumps({"answer": ma, "docs": kb_docs}, ensure_ascii=False),True)像上文描述的一样,设置好sse响应的迭代器处理逻辑即可。
sse = StreamingResponse(generate_multi_turn_sse(), media_type="text/event-stream")sse.headers["Cache-Control"] = "no-cache"sse.headers["Connection"] = "keep-alive"return sseMT-SSE的效果
最终效果如下图:
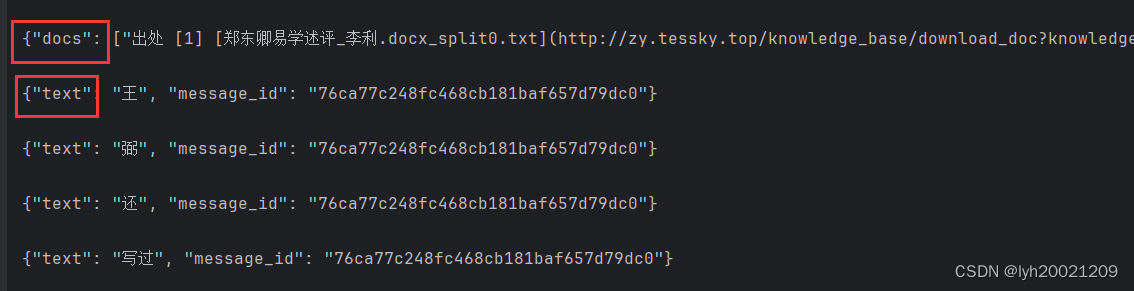
其中docs是知识库问答阶段响应的,text是最后的混合机制对话阶段响应的。
经过我们的实测,MT-SSE技术可以将我们的大模型应用的对话响应时间从5-7秒缩短至2-4秒。
这篇关于创新实训2024.06.02日志:SSE、流式输出以及基于MTPE技术的MT-SSE技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







