本文主要是介绍Kafka性能调优实战:同等资源配置性能提升20几倍的秘诀2021-06-21,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
掌握一到两门java主流中间件,是敲开BAT等大厂必备的技能,送给大家一个Java中间件学习路线,助力大家实现职场的蜕变。
Java进阶之梯,成长路线与学习资料,助力突破中间件领域
1、抛出问题
笔者最近在折腾数据异构体系,在实现MySQL增量数据同步到MQ(Kafka、RocketMQ),本文的故事就从这里开始。
众所周知,为了提高写入端的并发性能,通常会采用多线程并发机制,提高写入端的性能,接下来基于MySQL增量同步到Kafka为例,阐述一下第一版的架构方案。
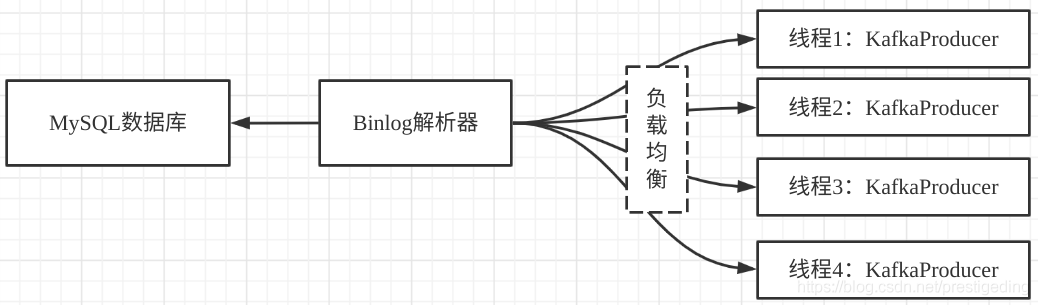
真实的数据同步架构设计复杂性远比上面复杂,上图旨在阐述Kafka的使用特点:
为了提高性能,通常会引入多线程,故组内同事直接采用多线程,通过创建多个线程,每一个线程单独创建一个KafkaProducer对象,然后binlog解析器后,按照分区键进行负载均衡。
但发现,性能非常低下,为什么呢?该如何处理呢?
2、多线程在Kafka这里为啥不好使了
当发现性能比较慢,然后又按照 Kafka性能优化指南进行调优,对linger.ms,batch.size等参数进行调优,但发现毫无用处,这是为啥呢?

Kafka的高吞吐率设计的核心要点之一是批处理,即kafka在消息发送端引入了一个双端队列,应用程序通过KafkaProducer的send方法时,会将消息先放入到双端队列,然后kafka使用一个异步线程从队列中成批发送消息。
为了确保sender线程能一次发送较多数据,kafka在客户端引入了一个参数linger.ms,默认为200ms,即小心进入到缓存区后不会立即被send线程发送,而是等待一定时间,这样能提高send线程的发送效率,提高吞吐率。
再回到上述到场景,将视角切换到单个线程,在单个线程内,应用方调用KafkaProducer后,消息会在缓存区中等待200ms,但由于是数据同步场景,消息发送使用的是同步发送,这样就会导致不管send线程等多久,永远只会有一条消息被发送,每条消息发送还要无缘无故的增加200ms的延迟,tps怎能上去?
第一个优化点:还是基于多线程发送,当多线程共同持有一个KafkaProducer对象,这样在同一时间会有更多数据到达KafkaProducer的缓存区,Sender线程就可以实现一次发送多条消息,实现批量发送到效果,从而提升Kafka的吞吐率,实现高TPS,其效果如下图所示:

关键点:对于单个线程,由于要保证消息都顺序性,使用的是同步发送模式。
3、“大杀器”异步发送也能保证顺序
众所周知,在数据异构的架构体系中,通常需要将分库分表的mysql数据库中的数据同步到es,从而实现跨库join等复杂查询功能。
数据同步为了确保数据的最终一致性,通常必须保证顺序。但其维度可以为表级别、数据行级别,通常只需要保证同一行数据的不同事件(新增、更新、删除)等事件必须顺序执行,所以在上述的架构中采用的是同步发送。
有没有可能使用异步发送,但同时满足顺序语义呢?
答案当然是可以的,**其设计思路为:将消息分批处理,该批次内部消息并发执行,各个批次顺序执行。**示意图如下:

将消息分成批次,批次1必须要先与批次2执行,但在执行一个批次的时候,如果这个批次中的消息的key(例如id)不相同,那这批消息内部其实是无需保证其顺序的,就可以将这批消息异步发送,使每条消息并发发送,大大提高其并发度,TPS将得到进一步提升。
温馨提示:如果一个批次中的消息存在相同的key,需要将这些消息进行分割,确保一个并发批次没有重复key。
同步转异步,如果目标端是RocketMQ,其优化效果会更加显著。
好了,本文就介绍到这里了,一键三连(关注、点赞、留言)是对我最大的鼓励。
掌握一到两门java主流中间件,是敲开BAT等大厂必备的技能,送给大家一个Java中间件学习路线,助力大家实现职场的蜕变。
Java进阶之梯,成长路线与学习资料,助力突破中间件领域
最后分享笔者一个硬核的RocketMQ电子书,您将获得千亿级消息流转的运维经验。

获取方式:私信回复RMQPDF即可获取。
个人网站:https://www.codingw.net
这篇关于Kafka性能调优实战:同等资源配置性能提升20几倍的秘诀2021-06-21的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






