本文主要是介绍语音降噪算法库介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.语音降噪技术方向介绍
软件上进行语音降噪目前主要是两个方向:传统降噪算法和AI降噪算法,他们各有千秋,目前看他们各有千秋,有各自适用场景。
推荐一个不错的人工智能学习网站,通俗易懂,内容全面,作为入门科普和学习提升都不错,分享一下给大家:前言 – 人工智能教程
1.两者的对比:
传统降噪算法:
**原理**:传统降噪算法通常基于信号处理的理论,如滤波器设计、频谱分析和信号建模等。它们通过分析信号的统计特性或频谱特性来去除噪声。
**实现方式**:传统降噪算法通常包括低通滤波器、高通滤波器、带通滤波器、谱减法、维纳滤波器和自适应滤波器等。这些算法通常需要手动调整参数以适应不同的噪声环境。
**效果**:传统降噪算法在处理简单或已知的噪声类型时效果较好,但对于复杂的噪声环境或非平稳噪声,效果可能有限。
**计算复杂度**:传统降噪算法的计算复杂度相对较低,可以在较低性能的硬件上运行。
AI降噪算法:
**原理**:AI降噪算法基于机器学习和深度学习的技术,通过训练神经网络来识别和去除噪声。这些算法可以从大量的数据中学习噪声的特征,并自动调整参数以适应不同的噪声环境。
**实现方式**:AI降噪算法通常使用卷积神经网络(CNN)、循环神经网络(RNN)或变换器(Transformer)等深度学习模型。这些模型可以自动提取信号的特征,并通过非线性变换来去除噪声。
**效果**:AI降噪算法在处理复杂的噪声环境和非平稳噪声时效果更好,因为它们可以从数据中学习噪声的复杂特征,并自动适应不同的噪声类型。
**计算复杂度**:AI降噪算法的计算复杂度较高,通常需要较高的性能硬件支持,如GPU。
对比总结:
**适应性**:AI降噪算法具有更好的适应性,能够自动调整参数以适应不同的噪声环境。
**效果**:AI降噪算法在处理复杂的噪声环境时效果更好,但需要大量的训练数据和较高的计算资源。
**计算资源**:传统降噪算法通常需要较低的计算资源,适合在资源受限的设备上运行。
**实现复杂度**:AI降噪算法的实现复杂度较高,需要专业的机器学习和深度学习知识。
二.降噪算法开源算法库
1.传统降噪算法库
(1)RNNoise:
这是一款由http://Xiph.Org基金会开发的神经网络语音降噪库。它使用神经网络模型来进行语音降噪,可以在实时对讲和非实时批处理两种模式下工作。该库支持C,C++和Python接口,并且性能很好。
(2)Speex:
这是一个开源的语音编解码库,它包含一个降噪模组,可以使用多种滤波算法进行语音降噪,比如谱减法、决策导向算法等。Speex支持C,C++接口,广泛应用于VoIP产品中。
(3)WebRTC:
这是一个开源的实时通信框架,它包含了一个高性能的降噪引擎,基于神经网络模型,可以对音频采样进行降噪。WebRTC支持C,C++,Objective-C,Java和JavaScript等多语言接口,应用十分广泛。
2.AI降噪算法库
(1)Anthropic Deep Noise Cancellation (DNC):
这是一个开源的深度学习语音降噪模型,由Anthropic开发。它是一个Keras实现的卷积神经网络模型,通过训练获得很高的降噪效果。该模型可以导出为TensorFlow, PyTorch和ONNX格式,支持多种语言和框架进行部署。
(2)NSNet:
这是一个开源的实时神经网络语音降噪系统,支持单声道和多声道信号降噪。它由两个神经网络模型组成,一个检测器网络和一个降噪网络,可以有效移除 stationary 和 non-stationary 噪声。NSNet支持TensorFlow和PyTorch部署。
(3)一个在线的AI降噪处理网站
https://audo.ai/api
三.WebRTC降噪模块
网上有人把WebRTC的噪声抑制模块提取出来,也做了一些细节优化,目前可以支持8k、16k采样率的pcm数据,实际测试效果还是挺不错的,可以看下测试对比图片:
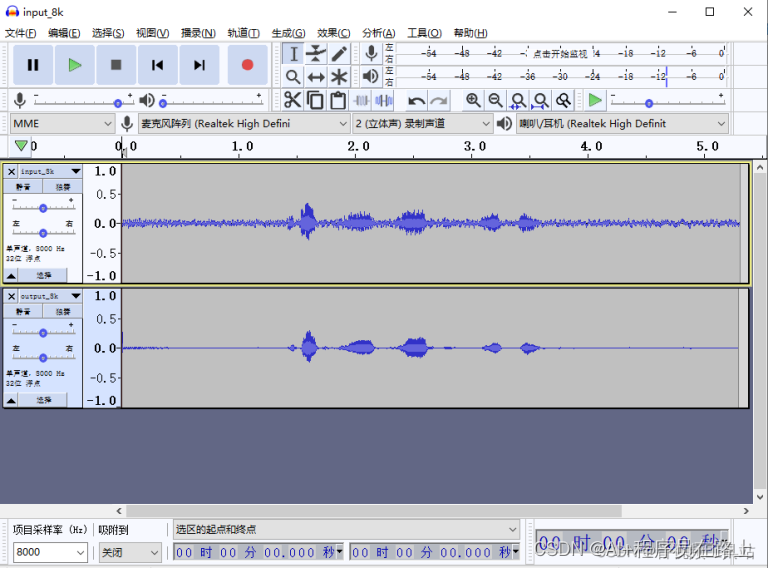
目前这个算法可以应用到多种平台,像windows、linux、android、ios、arm平台都可以支持,效果基本差别不大。
下载地址:https://download.csdn.net/download/unique_no1/82328350
这篇关于语音降噪算法库介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







