本文主要是介绍论文阅读:《Neural Machine Translation by Jointly Learning to Align and Translate》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
重磅专栏推荐:
《大模型AIGC》
《课程大纲》
《知识星球》
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
https://blog.csdn.net/u011239443/article/details/80521026
论文地址:http://pdfs.semanticscholar.org/071b/16f25117fb6133480c6259227d54fc2a5ea0.pdf
摘要
神经机器翻译是最近提出的机器翻译方法。与传统的统计机器翻译不同,神经机器翻译的目标是建立一个单一的神经网络,可以共同调整以最大化翻译性能。最近提出的用于神经机器翻译的模型经常属于编码器 - 译码器族,并且将源句子编码成固定长度的矢量,解码器从该矢量生成翻译。在本文中,我们推测使用固定长度向量是提高这种基本编码器 - 解码器架构性能的瓶颈,并且建议通过允许模型自动(软)搜索零件来扩展它的源句子与预测目标词相关,而不必将这些部分明确地形成为硬分段。采用这种新方法,我们实现了与现有最先进的基于短语的系统相媲美的英文到法文翻译的翻译性能。此外,定性分析显示模型发现的(软)对齐与我们的直觉非常吻合。
1. 介绍
最近由Kalchbrenner和Blunsom(2013),Sutskever(2014)和Cho(2014b)提出的神经机器翻译是一种新兴的机器翻译方法。 与传统的基于短语的翻译系统(参见Koehn等人,2003)不同,它由许多分开调谐的小型子部件组成,神经机器翻译尝试构建和训练单个大型神经网络读取一个句子并输出正确的翻译。
大多数提出的神经机器翻译模型属于一个编码器 - 解码器家族,每种语言都有一个编码器和一个解码器,或者涉及一种语言特定的编码器,然后将这些编码器应用于每个句子,然后将其输出进行比较。 编码器神经网络将源信号读取并编码为固定长度的矢量。 解码器然后从编码矢量输出翻译。 整个编码器 - 译码器系统由编码器和语言对的译码器共同训练,以最大化给定源句子的正确译文的概率。
这种编码器 - 解码器方法的一个潜在问题是神经网络需要能够将源语句的所有必要信息压缩成固定长度的向量。 这可能使神经网络很难处理长句,特别是那些比训练语料库中的句子更长的句子。 Cho等人 表明,当输入句子的长度增加时,基本编码器 - 译码器的性能的确会迅速恶化。
为了解决这个问题,我们引入了一个扩展到编码器 - 解码器模型,学习联合对齐和翻译。 每次提出的模型在翻译中生成一个单词时,它(软)会在源句子中搜索一组位置,其中最相关的信息是集中的。 该模型然后基于与这些源位置和所有先前生成的目标词相关联的上下文向量来预测目标词。
在本文中,我们表明,所提出的联合学习对齐和平移的方法实现了比基本编码器 - 解码器方法显着提高的翻译性能。 用更长的句子来改进这种改进更为明显,但可以用任何长度的句子来观察。 在英文到法文翻译的任务中,所提出的方法通过单一模型实现了与传统的基于短语的系统相当或接近的翻译性能。 此外,定性分析表明,所提出的模型发现源语句和相应的目标语句之间在语言上可信(软)对应。
2. 背景:神经机器翻译
从概率的角度来看,翻译等同于找到一个目标句子y,它使给定源句子x的y的条件概率最大化,即 a r g m a x y p ( y ∣ x ) arg max_y p(y | x) argmaxyp(y∣x)。 在神经机器翻译中,我们拟合参数化模型,以使用并行训练语料库来最大化语句对的条件概率。 一旦通过翻译模型学习了条件分布,给定源句子,可以通过搜索使条件概率最大化的句子来生成相应的翻译。
最近,一些论文提出使用神经网络直接学习这种条件分布。这种神经机器翻译方法典型地由两部分组成,其中第一部分编码源句子x,第二部分解码为目标句子y。 例如,(Cho等,2014a)和(Sutskever等,2014)使用两个循环神经网络(RNN)将可变长度的源语句编码成固定长度的向量并将该向量解码为一个可变长度的目标语句。
尽管是一种相当新颖的方法,神经机器翻译已经显示出有希望的结果。 Sutskever报告说,基于长期短期记忆(LSTM)单位的RNNs的神经机器翻译实现了接近传统的基于短语的机器翻译系统在英语到法语翻译任务上的最新性能。 例如,将现有翻译系统的神经元件添加到短语表中或对候选翻译进行重新排名,可以超越以前的最新性能水平。
2.1 RNN编码器 - 解码器
在这里,我们简要地描述由Cho和Sutskever提出的称为RNN编码器 - 解码器的底层框架,我们在该框架上构建了一种能够同时对齐和翻译的新颖架构。
在编码器 - 解码器框架中,编码器将输入句子(向量 x = ( x 1 , . . . , x T x ) x =(x_1,...,x_{T_x}) x=(x1,...,xTx)的序列)到向量c中。最常见的方法是使用RNN:

和
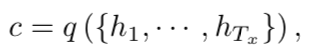
其中 h t ∈ R n h_t∈R_n ht∈Rn是时刻t的隐藏状态,c是隐藏状态序列产生的向量。 f和q是一些非线性函数。例如,Sutskever等人 (2014)使用LSTM作为f和 q ( h 1 , . . . , h T ) = h T q({h_1,...,h_T})= h_T q(h1,...,hT)=hT。
解码器通常被训练来预测给定上下文向量c和所有先前预测的词 y 1 , . . . , y t ′ − 1 {y_1,...,y_{t'-1}} y1,...,y
这篇关于论文阅读:《Neural Machine Translation by Jointly Learning to Align and Translate》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








