本文主要是介绍前嗅教程:采集表格/列表页中的数据(翻页),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以孔夫子旧书网的最近出版板块为例(http://www.kongfz.com/1004/)为例,采集列表页的所有数据:
第一步:新建任务
①击左上角“加号”新建任务,如图1:
![]()
【图1】
②在弹窗里填写采集地址,任务名称如图2:

【图2】
③点击下一步,选择进行数据抽取还是链接抽取,本次采集需要采集当前板块的列表页所有内容,所以只需要在同一个模板中进行翻页链接抽取以及数据抽取即可。此处需要勾选“抽取链接”-“普通翻页”以及“抽取数据”,如图3:

【图3】
第二步:创建/选择表单
在ForeSpider爬虫中,表单是可以复用的,所以可以在数据表单出直接选择之前建过的表单,也可以通过表单ID来进行查找并关联数据表单。此处使用的是的旧书网的表单,如图4
方法一:通过下拉菜单或表单ID选择已有表单
方法二:点击创建表单进入快速建表页面,新建表单

【图4】
方法三:点击“采集配置”-“数据建表”,点击采“采集表单”后面的 如图5

【图5】
第三步:配置表单
根据所需内容,配置表单字段(即表头),此处配置了包括标题、作者、价格三个字段,表单如图6
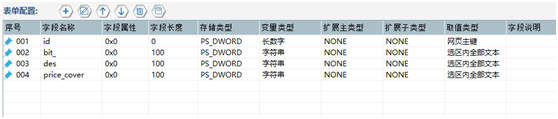
【图6】
第四步:字段取值
取值方法:由于此处活取的是列表页的数据,所以可以应用“识别列表”功能,直接取到列表数据,操作方法如下:
①点击“数据抽取-旧书网”,按住ctrl+鼠标左键点击任意一部分内容,如图7,选中标题

【图7】
②按住Shift+鼠标左键继续点击,直到点击到选中整个第一条数据,如图8

【图8】
③在软件的右下角可以看到“识别列表”按钮 ,此时点击“识别列表”,如图9,此时列表中的内容都已经选中。

【图9】
③对每个字段进行取值,方法依然是:按住Ctrl+鼠标左键,进行区域选择,按住Shift+鼠标左键,扩大选择区域。
如:price-cover字段
首先在左侧点到price-cover字段上,在浏览器中对该字段进行取值.
<1>按住ctrl+鼠标左键,点击“新书”
<2>按住shift+鼠标左键继续点击,直到选中图10中的全部内容
<3>点击右下角“确认选区”

【图10】
第五步:模板预览
①标右键点击“数据抽取”,然后点击“模板预览”,如图11

【图11】
②预览结果如图12

【图12】
第六步:应用定位过滤,过滤翻页链接
①标点击“链接抽取-普通翻页”,内置浏览器拉到最底端找到翻页,如图13

【图13】
②按住Ctrl+鼠标左键点击第一页,按住shift+鼠标左键,扩大选区,直到选中整行,如图14

【图14】
③点击“确认选区”
④点击“采集预览”查看链接过滤是否完全,此处由于只有一个模板,所以链接和数据在同一个预览框里,直接点击预览的结果如图15

【图15】
⑤点击“链接信息数目”,查看对应的链接,如图16,由于第9页之后直接就是第15页,如果怕中间页数取不到,可以双击第9页试试看

【图16】
第七步:采集预览
双击任意一页链接,点击“旧书网”均可得到对应的列表数据如图17

【图17】
这篇关于前嗅教程:采集表格/列表页中的数据(翻页)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






