本文主要是介绍iotdb时序库在火电设备锅炉场景下的实践【原创文字,IoTDB社区可进行使用与传播】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.概述
1.1 说明
本文章主要介绍iotdb数据库在电站锅炉工业场景下,对辅助智能分析与预警的使用介绍。
【原创文字,IoTDB社区可进行使用与传播】
1.2 项目背景
随着人工智能算法在电力领域的发展,以及燃煤锅炉设备精细化调整需求的增加,利用大数据算法开展锅炉关键设备全参数预测和预警,实现基于机理的设备工况分析和性能分析,开展设备健康状态评价和故障诊断研究,进而为深度调峰操作调整提供指导,为运行监盘提供预警,为检修维护提供参考。
此过程中面临诸多痛点:
设备种类繁多、协议众多、数据类型众多
时序数据特别是高频数据,数据量巨大
海量时序数据下的读写速度无法满足业务需求
现有时序数据管理组件无法满足各类高级应用需求
而选取IoTDB作为智能运维平台的存储数据库后,能稳定写入多频及高频采集数据,覆盖钢铁全工序,并采用复合压缩算法使数据大小缩减10倍以上,节省成本。IoTDB 还有效支持超过10年的历史数据降采样查询,帮助企业挖掘数据趋势,助力企业长远战略分析。
1.3 iotdb
Apache IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。 Apache IoTDB 采用轻量式架构,具有高性能和丰富的功能,并与Apache Hadoop、Spark和Flink等进行了深度集成,可以满足工业物联网领域的海量数据存储、高速数据读取和复杂数据分析需求。
具有它具有以下特点:
1.体量轻
2.性能高
3.易使用的特点
二 案例介绍
2.1 项目案例
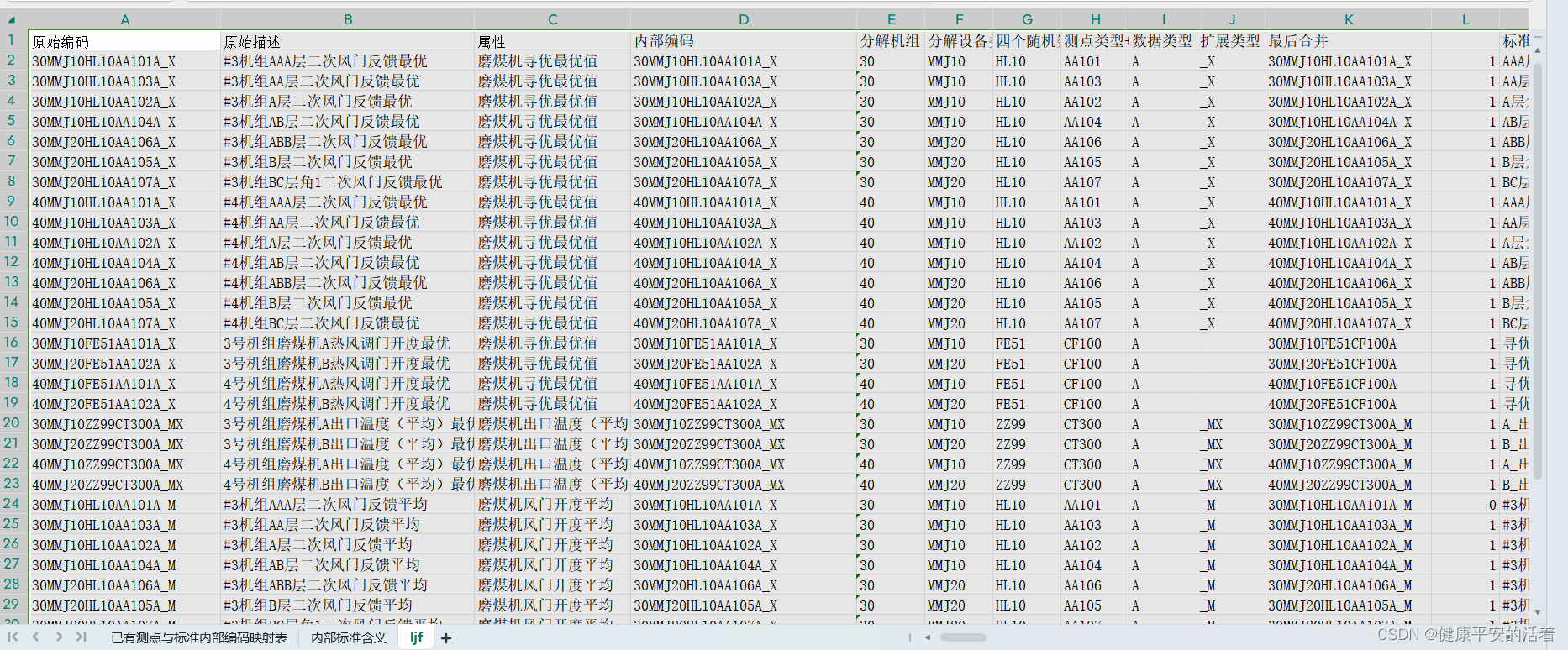
2.1.1 数据测点
数据采集层负责分别从采集点采集数据,目前3#、4#机组每分钟采集约5.2万个测点的实时生产数据,每分钟计算约10万次。
2.1.2 架构图
1.边缘侧:为推送给平台测区域的部分,一般是某具体电厂使用的系统或者博望推送数据的服务器机器。
2.平台接入测:这台服务器部署工业处理X平台,在X平台配置测点,资产树等信息;使用网络通信框架mina和其他电厂系统进行数据对接,将接入到的数据进行解码并安装配置好的测点信息,推送到x平台上;实时数据存储到iotdb中。

2.1.3 功能接口案例
1工况预警页面,通过查询iotdb数据库,显示磨煤机工况预警统计信息,如下图:

2.iotdb连接线程池工具类,如下图:

3.对应的iotdb核心代码 :

2.1.4 其他案例场景iotdb的sql用法
1.命令启动iotdb服务
| #启动 (前台启动) sbin/start-server.sh #nohup后台启动,输出启动日志到nohup.log文件 nohup sbin/start-server.sh >> nohup.log 2>&1 & #nohup后台启动,不输出启动日志 nohup sbin/start-server.sh >/dev/null 2>&1 & #停止 sbin/stop-server.sh |
2).iotdb导出脚本语句
sh export-csv.sh -h 127.0.0.1 -p 6667 -u root -pw root -td /root/export-data0328 -f 30KYQ20AA00CT001A_M.csv -q "select 30KYQ20AA00CT001A_M from root.iot_point.tenant_system where time >= 2022-03-25 05:00:00 and time <= 2022-03-25 06:00:00"
3).查看 iotdb 库中测点 30MMJ10FC10CT303A 的正常数据。
a)sql语句
select 30MMJ10FC10CT303A as 30MMJ10FC10CT303A from root.iot_point.tenant_systemorder by time desc limit 10
b)截图如下:
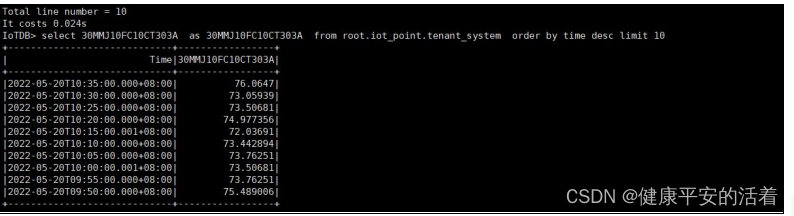
c.观察后这里将测点 30MMJ10FC10CT303A 的模拟值设置:
将前一个时刻值设置 78.5001
将当前时刻值设置 73.5001
时间间隔为:60s
计算: (78.5001-73.5001)/60=0.0833
2.1.5 注意事项
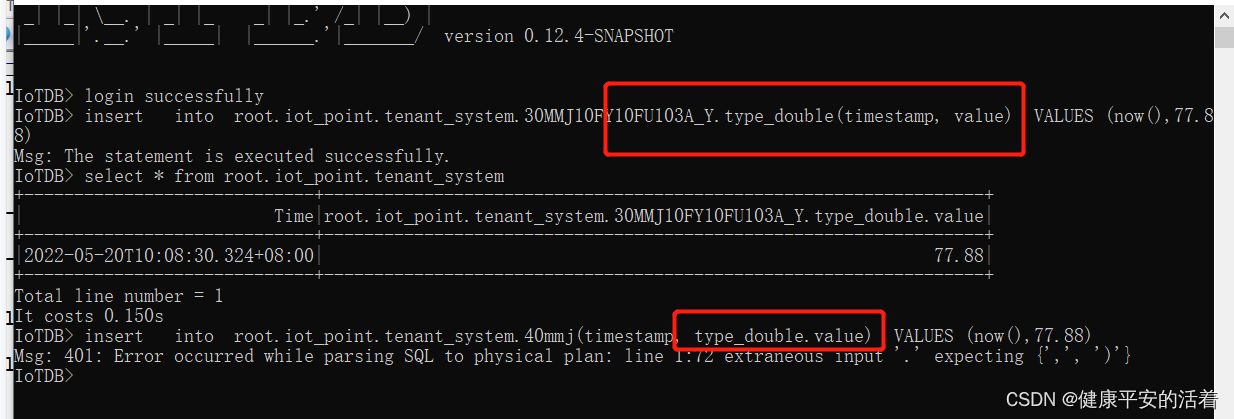
在执行dml命令添加数据的时候,insert into xxxx values(y) ;xxxx只能到设备层,values里面只能有列名。如下图所示:
这篇关于iotdb时序库在火电设备锅炉场景下的实践【原创文字,IoTDB社区可进行使用与传播】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





