本文主要是介绍GEE 10m 全球 LULC 数据集 ESRI Land Cover,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

土地利用土地覆盖(LULC)地图在许多行业部门和发展中国家越来越成为决策者的重要工具。这些地图提供的信息有助于通过更好地理解和量化地球过程和人类活动的影响,从而制定政策和土地管理决策。
ESRI Land Cover 数据介绍
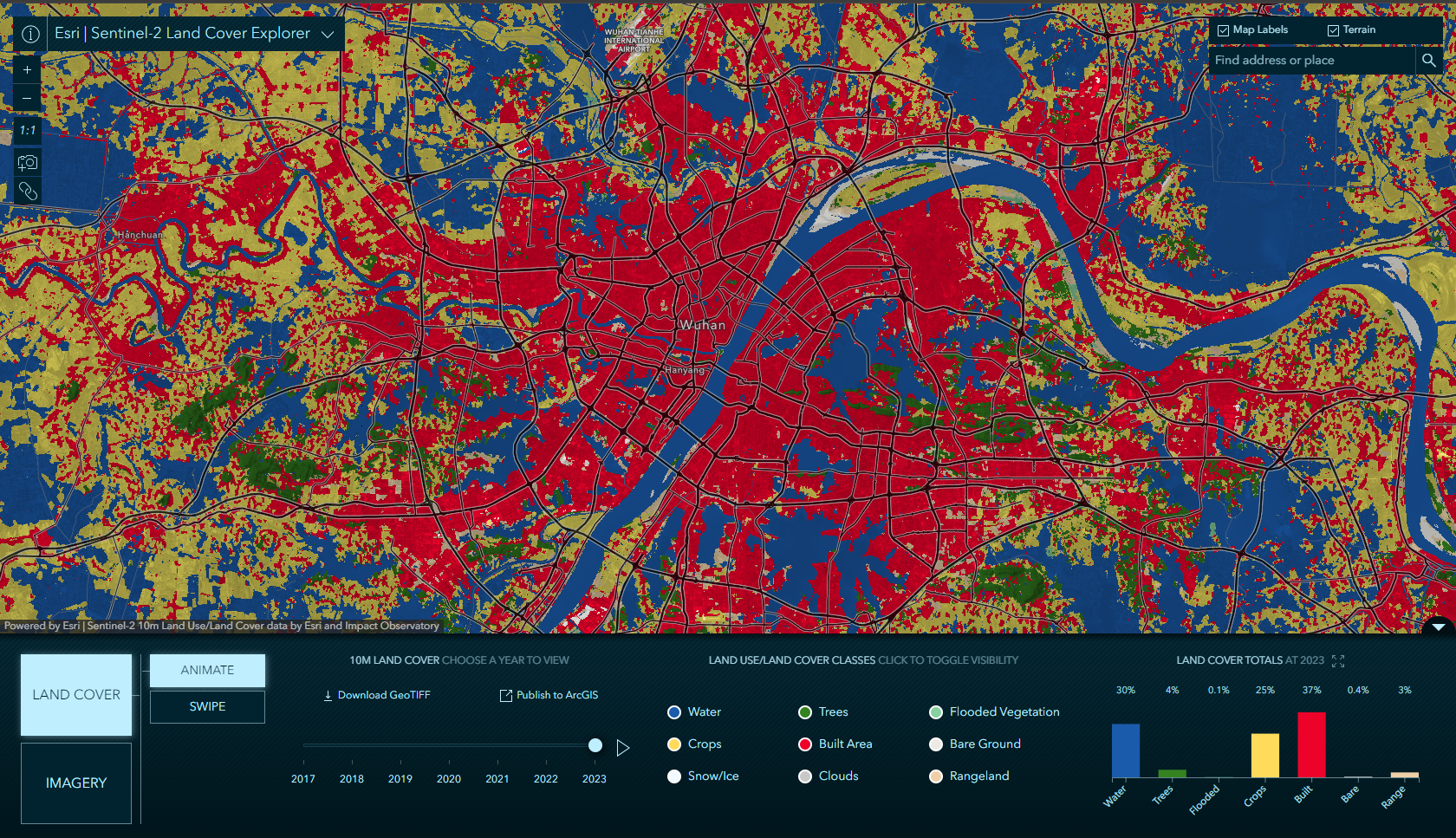
ArcGIS Living Atlas of the World 提供了详细、准确且及时的全球 LULC 地图。该数据是 Esri 和 Impact Observatory 合作的结果。有关数据的更多信息,请参阅 Sentinel-2 10 米土地利用/土地覆盖时间序列。
-
网站访问链接:
https://livingatlas.arcgis.com/landcoverexplorer/ -
土地利用/土地覆盖(LULC)地图的重要性:
- 土地利用/土地覆盖(LULC)地图是分析师和决策者在政府、民间社会、工业和金融领域中监测全球环境变化和衡量可持续生计与发展的风险时所需的基础地理空间数据产品。对高层次、自动化的地理空间分析产品有着强烈的需求,这些产品能够将像素转化为非地理空间专家可操作的见解。
-
Sentinel-2 卫星的优势:
- Sentinel-2 卫星自2015年中期首次发射以来,凭借其高空间分辨率、光谱分辨率和时间分辨率,成为 LULC 制图的优秀候选者。深度学习和可扩展的云计算进步如今提供了所需的分析能力,能够解锁全球卫星影像观测的价值。
-
利用深度学习创建全球 LULC 地图:
- 基于一个包含超过 50 亿个人工标记 Sentinel-2 像素的全新大型数据集,我们开发并部署了一种深度学习分割模型,以
10米分辨率在 Sentinel-2 数据上创建全球 LULC 地图。该地图实现了最先进的精度,并使时间序列观测的自动化 LULC 制图成为可能。
- 基于一个包含超过 50 亿个人工标记 Sentinel-2 像素的全新大型数据集,我们开发并部署了一种深度学习分割模型,以
数据研制流程
- 论文参考链接:
https://ieeexplore.ieee.org/document/9553499/
K. Karra, C. Kontgis, Z. Statman-Weil, J. C. Mazzariello, M. Mathis and S. P. Brumby, “Global land use / land cover with Sentinel 2 and deep learning,” 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 2021, pp. 4704-4707, doi: 10.1109/IGARSS47720.2021.9553499. keywords: {Deep learning;Industries;Image segmentation;Satellites;Time series analysis;Government;Geoscience and remote sensing;land use land cover;deep learning;segmentation;Sentinel 2},
1 训练数据
-
全球、地理平衡的训练数据集:
- 使用了超过
24,000个 5 公里 × 5 公里的图像片段。 - 图像片段被手工标记为十个类别:水、树木、草、被淹没的植被、农作物、灌木丛/灌木丛、建筑区域、裸露地面、雪/冰和云。
- 数据集采用随机分层抽样方法,从
14个主要生物群落中收集。
- 使用了超过
-
密集标记方法:
- 注释者使用密集标记方法代替单像素标签。
- 在场景中的各个要素类周围绘制矢量边界。
- 密集标记使深度学习算法能够探索图像的空间和光谱特征,并且比单像素注释更快地恢复每个像素的标签。

2. 模型开发
-
UNet 模型训练:
- 使用上述手工标记数据,从头训练了一个大型 UNet 模型。
- UNet 是一种卷积神经网络架构,最初为生物医学图像分割而开发,也被证明在卫星图像的语义分割任务中有效。
- 使用上述手工标记数据,从头训练了一个大型 UNet 模型。
-
分割任务:
- 将分割任务表述为一个逐像素分类问题。
- 包含前述的十个类别以及一个针对未标记像素的额外“无数据”类别。
- 利用分类交叉熵损失函数,并使用基于每个类别百分比比例的逆对数加权来处理数据集中的类别不平衡问题。

-
使用的 Sentinel-2 波段:
- 使用 Sentinel-2 L2A 表面反射校正影像的六个波段(红、绿、蓝、nir、swir1、swir2)。
- 每个波段都转换为浮点数并在 0 和 1 之间缩放。
-
数据增强:
- 通过随机垂直和水平翻转图像进行数据增强。
- 这样可以引入更多地理模式变化。
-
防止过度拟合:
- 在训练期间采用 dropout 技术,在每个批次中随机关闭 UNet 中
20%的神经元。dropout:一种防止神经网络过度拟合的技术,通过随机丢弃神经元来实现。
- 在训练期间采用 dropout 技术,在每个批次中随机关闭 UNet 中
-
训练过程:
- 该模型经过 100 个 epoch 的训练才收敛。
epoch:机器学习中完成一次训练数据集迭代的过程。
- 采用阶梯式学习率,在验证损失趋于稳定后,学习率会下降一个数量级。
- 该模型经过 100 个 epoch 的训练才收敛。
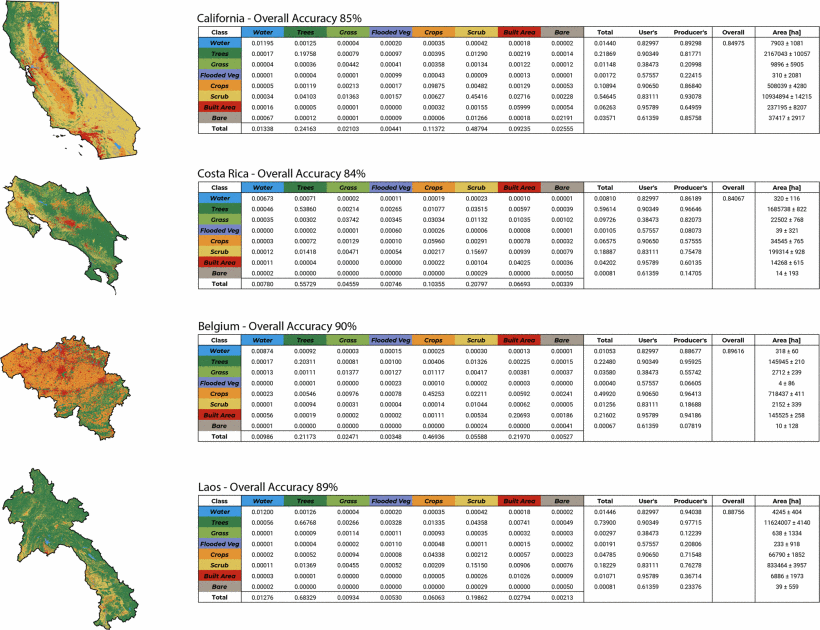
结果表明,借助强大的训练数据集和深度学习模型,可以创建分辨率为 10 米的全球一致的 LULC 地图。我们的模型在十个类别中实现了 85% 的整体准确度,并且考虑到主要混淆因素具有直观意义,我们相信全球地图具有科学依据且实用。未来仍有几个有希望的改进途径。例如,包括 Sentinel-1 辐射校正地面范围检测 (GRD) 数据可以帮助处理所有类别,特别是在区分被淹没的植被与农田以及裸露与灌木丛/灌木方面。此外,添加时间序列特征(如一年内植被健康状况的测量值)可以区分草地、农作物和灌木丛/灌木。
对于表现较差的类别(例如草地、被淹没的植被),额外收集手工标记的训练数据以提供更多跨地域的此类示例可能会提高准确率。我们还计划试验模型架构、类别权重和其他数据增强技术,以提高模型性能和泛化能力。
GEE 使用数据集
以武汉为显示中心,ESRI Global-LULC 10m显示如下:
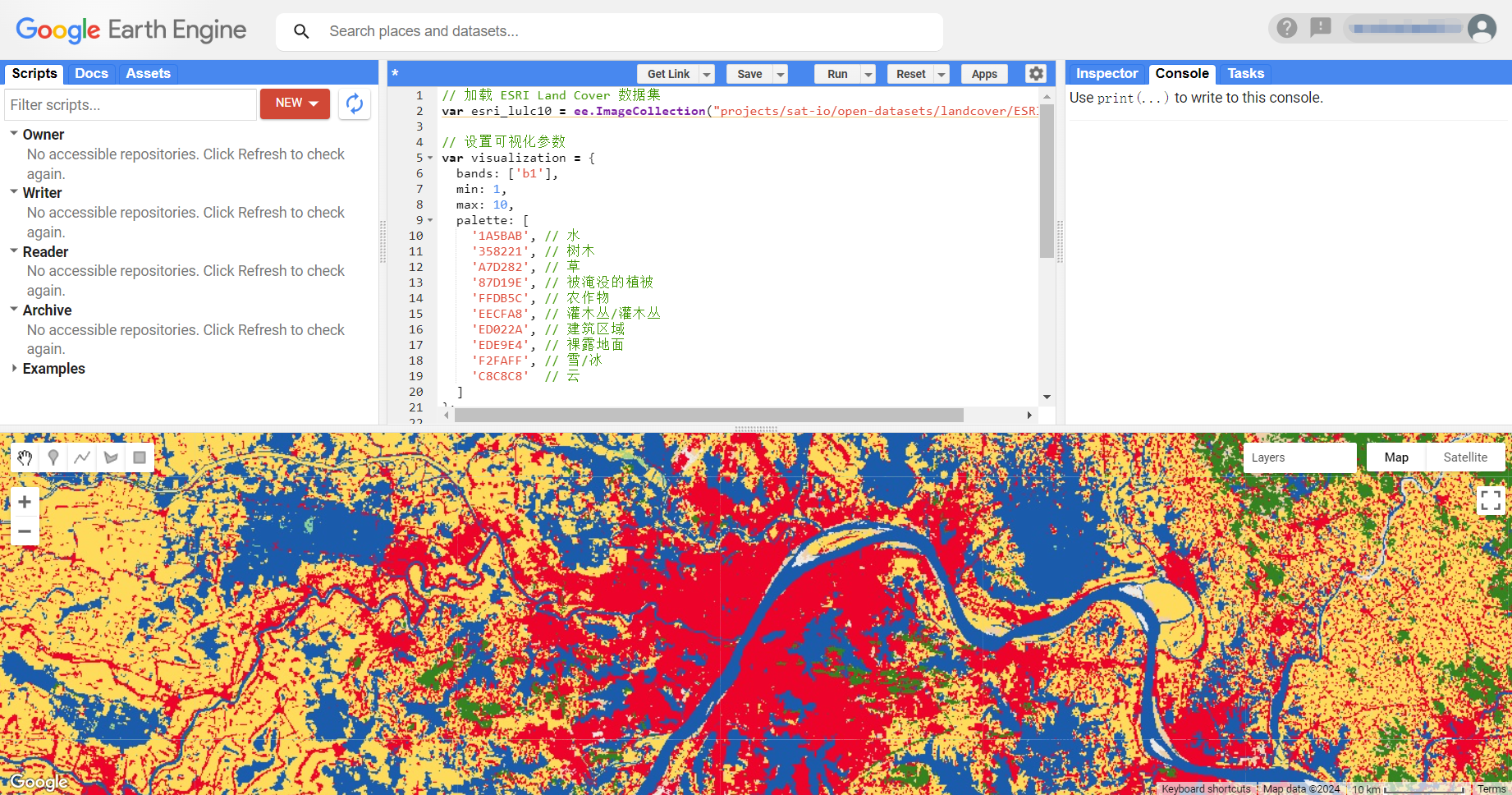
完整代码
// 加载 ESRI Land Cover 数据集
var esri_lulc10 = ee.ImageCollection("projects/sat-io/open-datasets/landcover/ESRI_Global-LULC_10m");// 设置可视化参数
var visualization = {bands: ['b1'],min: 1,max: 10,palette: ['1A5BAB', // 水'358221', // 树木'A7D282', // 草'87D19E', // 被淹没的植被'FFDB5C', // 农作物'EECFA8', // 灌木丛/灌木丛'ED022A', // 建筑区域'EDE9E4', // 裸露地面'F2FAFF', // 雪/冰'C8C8C8' // 云]
};// 定义武汉的区域
var wuhan = ee.Geometry.Rectangle([113.6938, 29.9701, 115.0227, 31.2198]);// 裁剪函数
function clip(image) {return image.clip(wuhan);
}// 裁剪数据集
var clippedEsriLulc10 = esri_lulc10.map(clip);// 将裁剪后的 ESRI Land Cover 数据集添加到地图
Map.addLayer(clippedEsriLulc10.mosaic(), visualization, 'ESRI Land Cover - Wuhan');// 设置地图中心和缩放级别以显示湖北武汉
Map.setCenter(114.3055, 30.5928, 10); // 经度、纬度、缩放级别
代码说明
-
加载数据集:
var esri_lulc10 = ee.ImageCollection("projects/sat-io/open-datasets/landcover/ESRI_Global-LULC_10m");使用
ee.ImageCollection函数加载 ESRI Land Cover 数据集。 -
设置可视化参数:
var visualization = {bands: ['b1'],min: 1,max: 10,palette: ['1A5BAB', // 水'358221', // 树木'A7D282', // 草'87D19E', // 被淹没的植被'FFDB5C', // 农作物'EECFA8', // 灌木丛/灌木丛'ED022A', // 建筑区域'EDE9E4', // 裸露地面'F2FAFF', // 雪/冰'C8C8C8' // 云] };设置显示图层的波段、颜色范围和颜色调色板。
-
定义武汉的区域:
var wuhan = ee.Geometry.Rectangle([113.6938, 29.9701, 115.0227, 31.2198]);使用
ee.Geometry.Rectangle函数定义武汉的区域。 -
裁剪函数:
function clip(image) {return image.clip(wuhan); }定义一个裁剪函数,将图像裁剪到武汉区域。
-
裁剪数据集:
var clippedEsriLulc10 = esri_lulc10.map(clip);使用
map函数对数据集进行裁剪。 -
将裁剪后的数据集添加到地图:
Map.addLayer(clippedEsriLulc10.mosaic(), visualization, 'ESRI Land Cover - Wuhan');使用
Map.addLayer函数将裁剪后的数据集添加到地图。 -
设置地图中心和缩放级别:
Map.setCenter(114.3055, 30.5928, 10);使用
Map.setCenter函数设置地图中心为湖北武汉的经度(114.3055)和纬度(30.5928),缩放级别为 10。
ESRI Land Cover数据集是一个强大的资源,它在GEE平台上的应用为研究人员和决策者提供了深入洞察地球表面变化的能力。通过本博客的介绍,可以开始在GEE中探索和分析ESRI Land Cover数据集,以支持研究和项目。
如果这对您有所帮助,希望点赞支持一下作者! 😊
点击查看原文

这篇关于GEE 10m 全球 LULC 数据集 ESRI Land Cover的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





