本文主要是介绍大模型时代的具身智能系列专题(六),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
UCSD 王小龙组
王小龙是UCSD电子与计算机工程系的助理教授。他曾在加州大学伯克利分校与Alexei Efros和Trevor Darrell一起担任博士后研究员,在CMU RI获得了机器人学博士学位,师从Abhinav Gupta。他的研究重点是通过视频和物理机器人交互数据来学习3D和动态表示。促进机器人技能的学习,目标是使机器人能够在真实物理世界中与各种对象和环境有效互动。近期其团队分别在仿真和数据层面提出GenSim,Open X-Embodiment。
主题相关作品
- GenSim
- Open X-Embodiment
- ExBody
GenSim
现有的数据生成方法通常侧重于场景级多样性(例如,对象实例和姿势),而不是任务级多样性,因为提出和验证新任务需要人工努力。这使得在模拟数据上训练的策略很难证明其significant任务级泛化。在本文中,我们提出通过利用大型语言模型(LLM)的grounding和编码能力来自动生成丰富的仿真环境和专家演示。我们的方法,被称为GENSIM,有两种模式:目标导向生成,目标任务给到LLM, LLM提出一个任务课程来解决目标任务;探索性生成,在LLM中,从以前的任务中引导并迭代地提出有助于解决更复杂任务的新任务。我们使用GPT4将现有benchmark扩展了10倍,达到100多个任务,在此基础上我们进行了监督微调,并评估了几个LLM,包括微调的gpt和Code Llama,用于机器人仿真任务的代码生成。此外,我们观察到LLMs生成的仿真程序在用于多任务策略训练时可以显著增强任务级泛化。我们进一步发现,在最小的sim-to-real适配下,在gpt4生成的模拟任务上预训练的多任务策略表现出更强的向现实世界中看不见的长视界任务的转移,并且比基线高出25%。
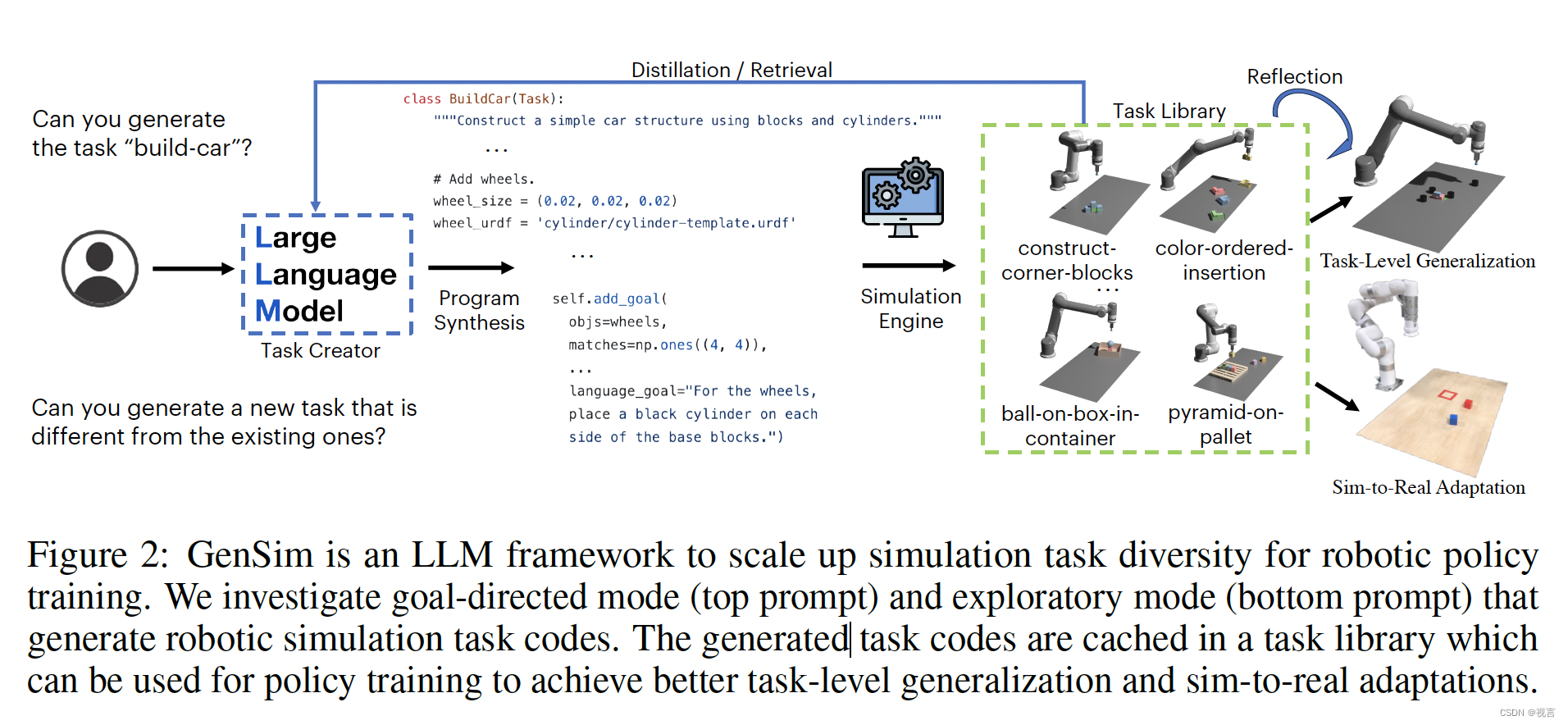
策略学习的自动任务生成
task creator
任务创建者的目标是提出新的任务描述和相应的代码实现,可以进一步分解为场景生成和演示生成。我们使用Ravens benchmark,它专注于运动原语,如推和拾取,可以通过每个时间步的两个末端执行器姿态参数化。从图3中的示例来看,模拟环境代码中的重置函数有效地初始化了资产及其属性和姿态,和参数化每个步骤动作的空间和语言目标一样。在探索性任务生成设置中,将提示pipeline生成与现有任务完全不同的新任务。在目标导向设置中,pipeline的目的是填充任务描述和指定任务名称的实现。探索性方法需要创造性和推理能力来提出新的任务,而目标导向方法侧重于将模拟编码作为一个特定的任务。
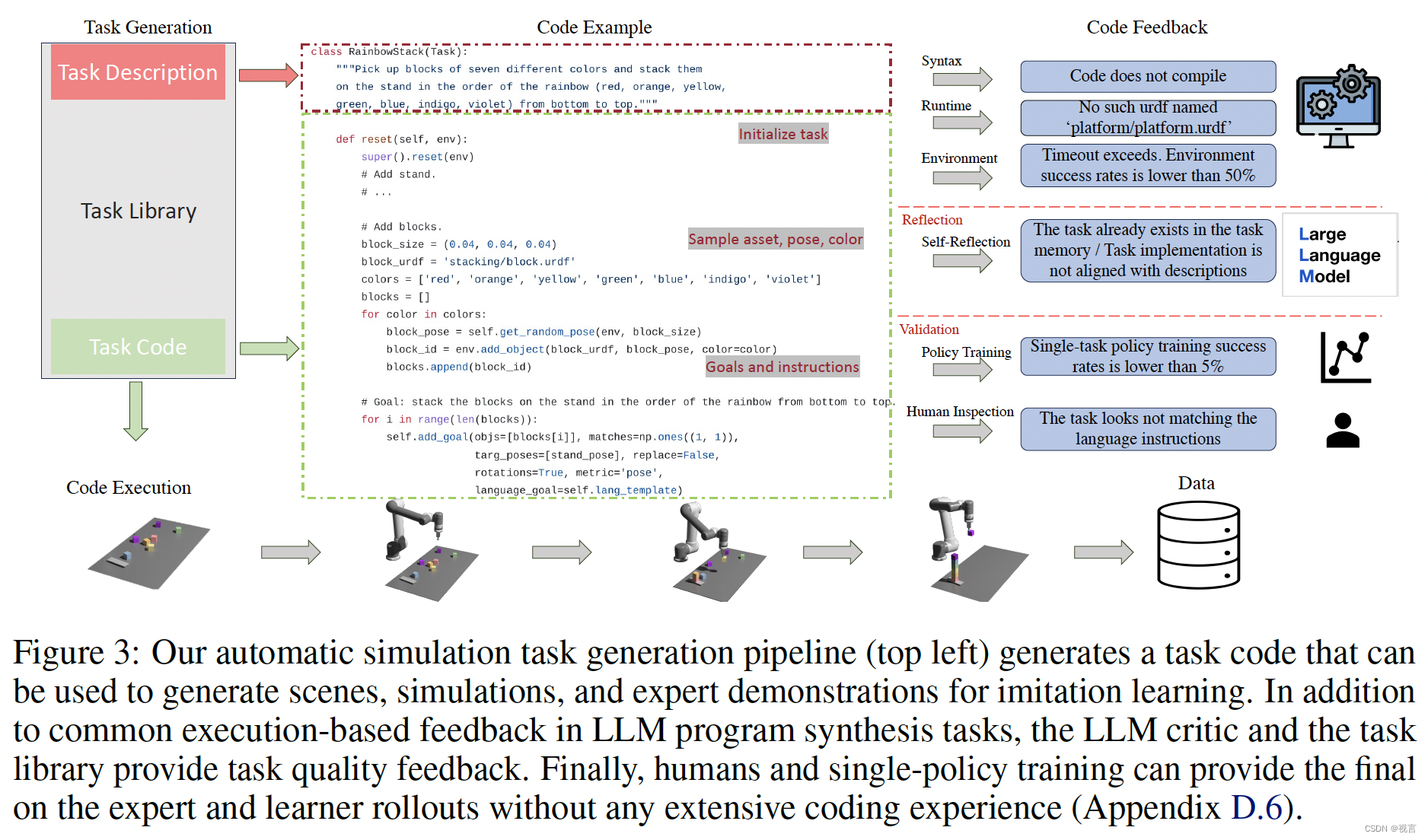
在这两种设置中(图3),语言链首先生成任务描述,然后生成相关的实现。任务描述包括任务名称、资产和任务摘要。我们在pipeline中采用少量提示来生成代码。将提示LLM从任务库中的现有任务中检索参考任务和代码。这个过程对于LLM确切地知道如何实现任务类(例如首先采样资产URDFs和构建场景的过程,然后添加空间目标和语言目标)至关重要。与其他LLM编码任务相比,机器人模拟中有各种各样的反馈形式,包括执行pipeline、模拟器、策略培训和人类。
TASK LIBRARY
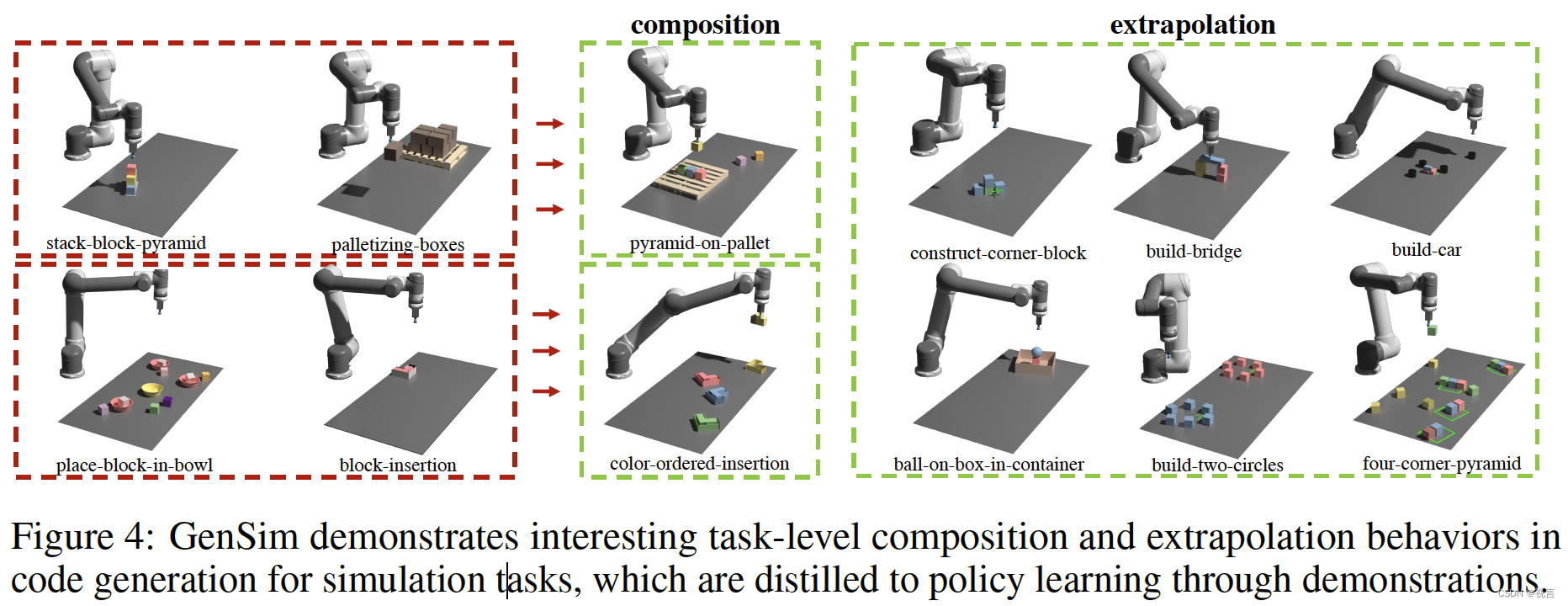
在GenSim框架中,我们利用一个外部内存,称为任务库,来检索由任务创建者生成的任务,以提出更好的新任务,并训练多任务策略。任务库是从人工管理benchmark中的任务初始化的。它为任务创建者在描述生成阶段提供了过去的任务描述列表为条件,在代码生成阶段提供过去代码列表。然后,提示任务创建者从任务库中检索参考任务,作为编码新任务的示例,即检索增强生成(RAG)。在任务实现完成并能够成功生成演示之后,我们提示LLM对新任务和任务库进行反思,并就是否应该将新生成的任务添加到库中形成一个集成决策。在图4中,我们在GenSim生成的任务中观察到有趣的组合和外推行为。这些保存的任务代码可以离线使用,以生成用于多任务策略训练的演示轨迹数据。
在探索模式下生成的任务库可以用作迭代训练任务创建者的引导数据,以在目标导向模式下生成更好的模拟任务。这对于扩展任务生成和纳入人类反馈非常重要,因为使用微调模型作为任务创建者更经济。
LLM监督的多任务策略
一旦生成了任务,我们就可以使用这些任务实现来生成演示数据和训练操作策略。我们使用双流传输网络架构,通过可用性预测来参数化策略。从代码生成到语言条件行为克隆的过程可以看作是从LLM到机器人策略低级控制和环境操作可能性的蒸馏过程。将程序视为任务和相关演示数据的有效表示(图5),我们可以定义任务之间的嵌入空间,其距离度量对诸如物体姿态和形状等感知因素的变化更为稳健,但比语言指令更具信息性。

实验
回答三个问题:LLM能否设计实现仿真任务以及能否提高LLM任务生成的性能?LLM生成的任务能否提高策略泛化性以及是否生成任务越多越好?在LLM生成的仿真任务上预训练能否在迁移到真实世界时产生策略部署的收益?
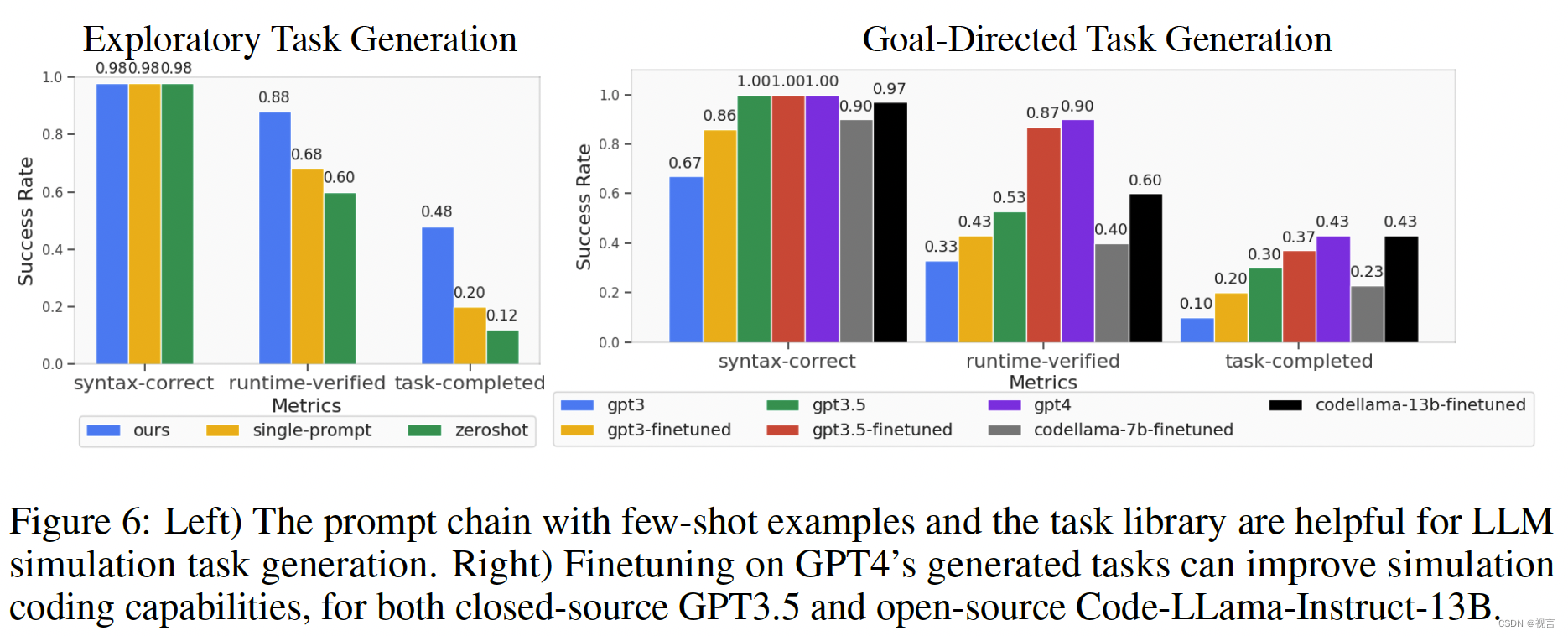
评估LLM机器人仿真任务生成
具体来说,我们测量“语法正确”的通过率序列,“语法正确”测量了基本的编码语法问题以及答案格式问题,“运行时验证”测试了资产幻觉和代码推理能力,最后“任务完成”测量了任务演示的设计(选择位置运动的成功)。这些指标显示在图6的x轴中。我们的指标具有从语法到运行时的增量结构,以成功地生成演示,其中前一个指标失败意味着后一个指标失败。为了将这些任务生成能力提炼成更经济和可扩展的语言模型,并潜在地进行自我改进,我们使用任务库中的100个gpt4生成的任务作为调优的数据集。我们使用OpenAI API对GPT模型进行微调,并通过这个微调过程获得更好的性能。此外,我们还用LoRA 微调了开源LLMs,如Code-Llama。我们使用带有简短提示的任务名称作为输入tokens,任务代码作为自回归训练的输出tokens。
任务级生成
我们采用Ravens benchmark中提出的0(失败)到100(成功)分数,该benchmark考虑了完成任务的部分分数。仿真机器人设置为带有吸力夹持器的Universal robot UR5e。策略输入是自顶向下的RGB-D重建,输出是一个功能映射,然后将其转换为选择和放置操作。我们使用CLIPort架构,但是该框架独立于我们使用的策略参数化。测试任务集没有特别选择。我们发布了一个由GPT生成的语言条件benchmark(带有模型权重和任务列表),范围从10个任务到100个任务,用于研究具有环境可能性预测的scaling策略学习。
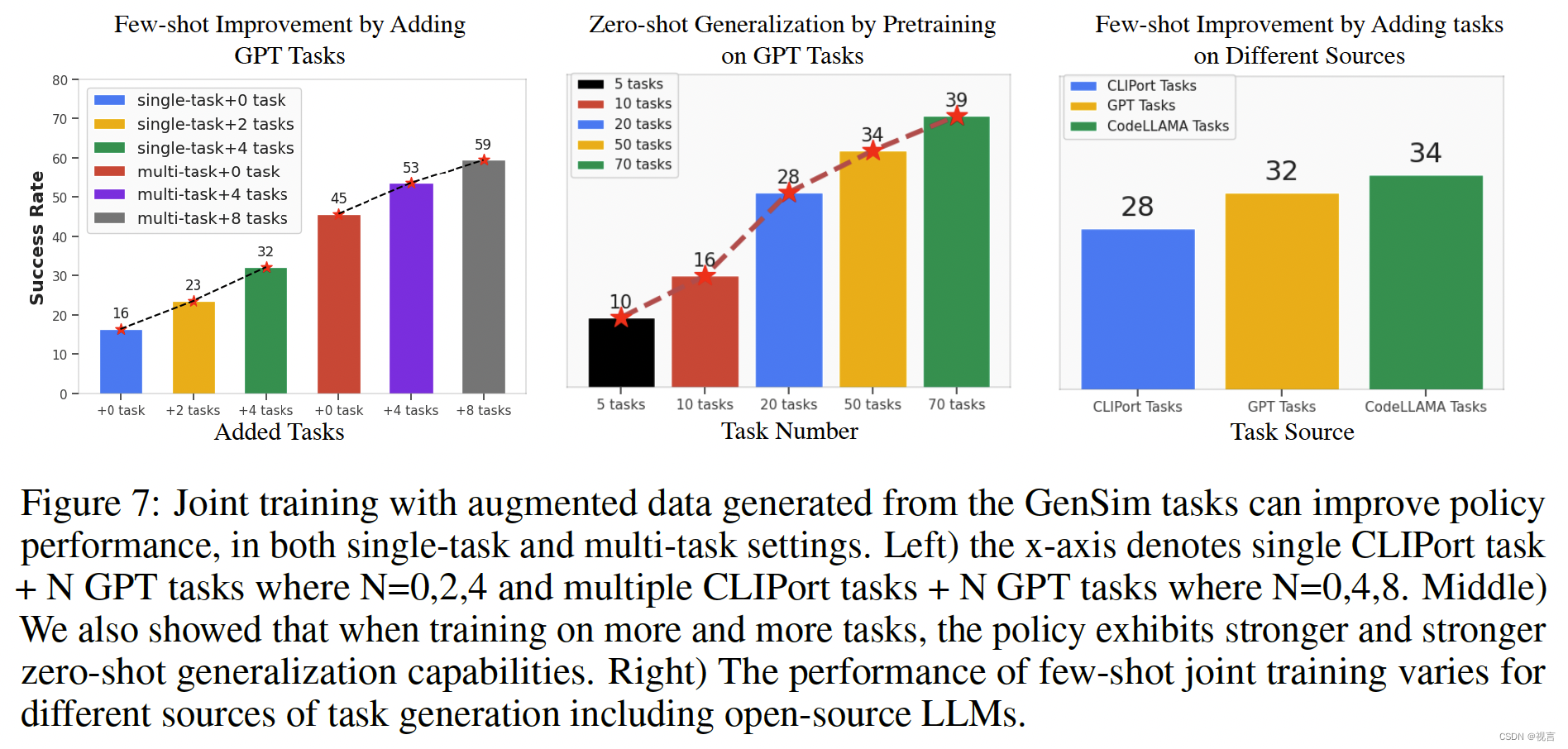
适配预训练模型到真实世界
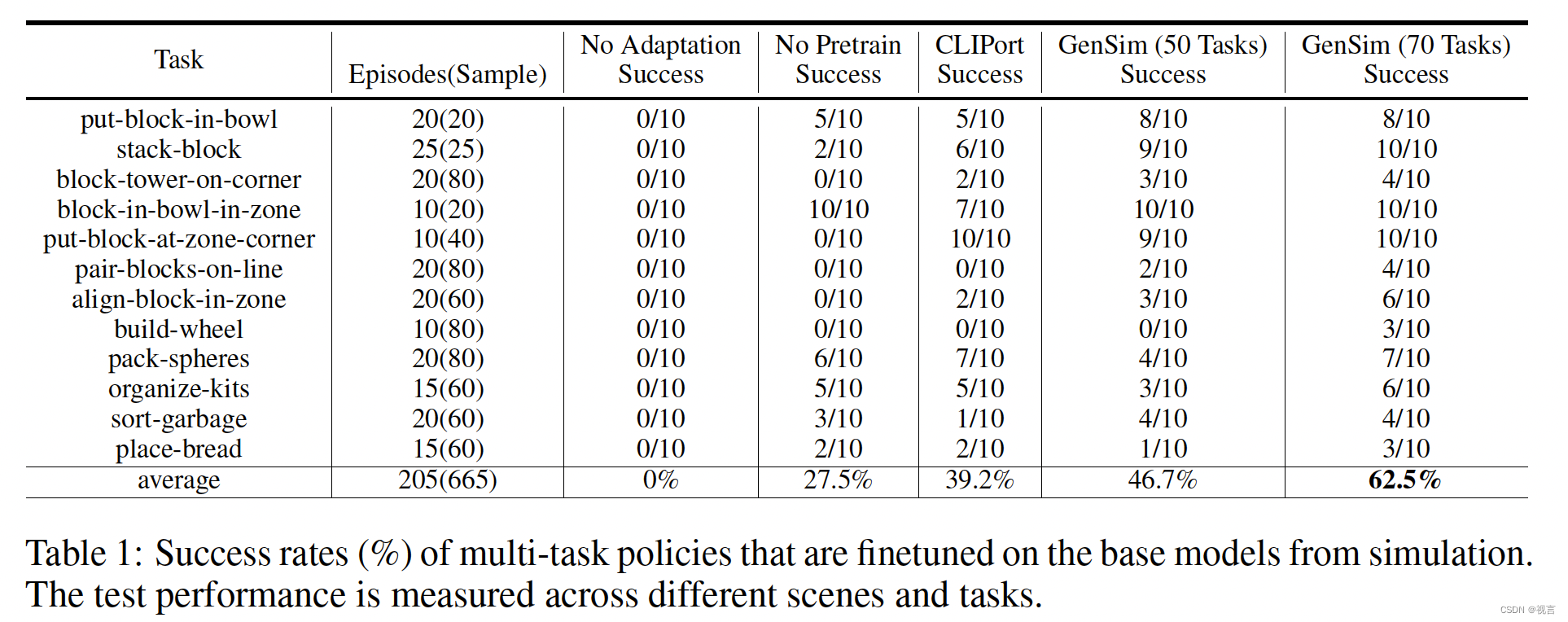
我们假设,通过在模拟中扩展LLM生成的训练任务的多样性,训练后的策略将在现实场景中表现出更强的适应性。为了进一步增强从模拟到真实的过渡,我们结合了一个适应现实世界的过程。这个过程包括为每个任务收集一小部分真实世界的数据,然后对数据进行扩充,并对模拟预训练模型进行超过50次的微调。我们使用配备吸力钳的XArm-7机器人进行现实世界的实验。鸟瞰相机面朝下安装,捕捉RGB-D观测。在表1中,对70个gpt4生成的任务进行预训练的模型在12个任务的10次试验中实现了62.5%的平均成功率,与仅对CLIPort任务进行预训练的基线相比增加了20%以上,比仅对50个任务进行预训练的模型提高了15%。从质量上讲,没有充分预训练的基线模型通常会选择或放置错误的对象,而没有调整的基线会导致分散性预测。
总结
提出了GenSim,一个可扩展的LLM框架,以增强机器人策略的各种仿真任务,其目的是将LLM的基础和编码能力提炼到低级策略中。我们研究了目标导向和探索性方法中的LLM提示、检索增强生成和微调,以生成新的仿真任务代码。我们利用生成的任务来训练多任务策略,这些策略显示了对模拟和现实世界中的新任务的泛化能力。
局限性:生成的代码仍然包含基本的语法错误,并且存在幻觉,并且缺乏物理和几何细节的基础。另一个问题是代码生成评估度量是不完美的(例如不一致的语言描述),因此生成的任务可能需要在策略训练之前进行一些手动过滤。最后,我们只探索了桌面拾取和放置任务生成,生成灵巧和复杂的机器人任务可能更具挑战性。
这篇关于大模型时代的具身智能系列专题(六)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








