本文主要是介绍SpringCloud微服务项目实战 - 限流、熔断、降级处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们知道,在分布式微服务项目体系中,一个系统是由若干个子服务模块组成,这若干个子服务相互调用协同工作,对外输出服务使得整个系统运作。
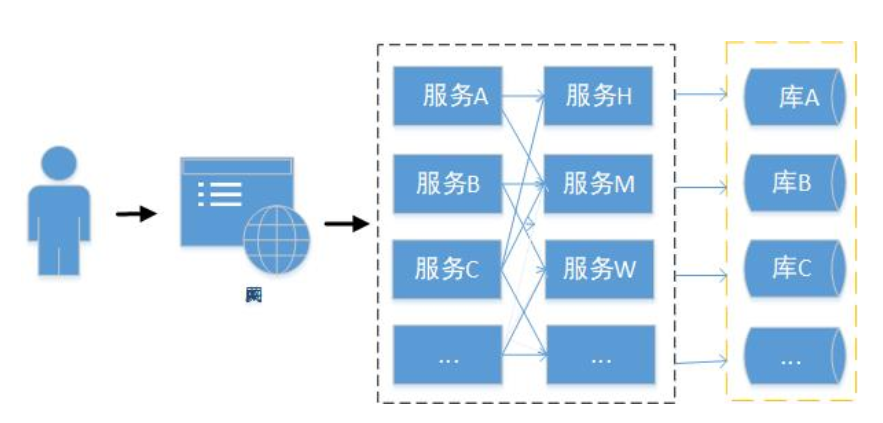
由于服务之间的相互协作调用,所以要保证整个系统完整运行,就得保证每个服务模块运行良好。但在实际庞大的分布式体系中,我们难免遇到某个服务阻塞或挂起等情况。假设客户在下单时,需要调用订单服务的接口,而订单服务有依赖了客户服务、商品服务、库存服务等,在下单时如果依赖的某个服务发生异常(请求超时),所有的请求就阻塞在这个依赖服务上,则会造成整个下单接口调用失败。就会导致整个系统下单不可用甚至雪崩,那这种问题如何解决呢?这将是我们文章里今天要讨论的话题。
在SpringCloud分布式项目中,为了保证服务的高可用,Netflix的组件Hystrix可以将这些请求隔离,针对服务限流,当某个服务不可用时能够熔断并降级,防止级联故障。
什么是Hystrix?
Hystrix中文翻译 豪猪,由于其背上长满了棘刺,从而拥有自我保护的能力。Hystrix作为Netflix开源的一款容错框架,同样具有自我保护能力。
它是一个用于处理分布式系统的延迟和容错的开源库, 在分布式系统中,许多不可避免的服务调用失败, 如超时/异常等。Hystrix 能够保证在一个依赖出现问题的情况下,不会导致整体系统服务的失败、避免级联故障、提高系统的弹性。
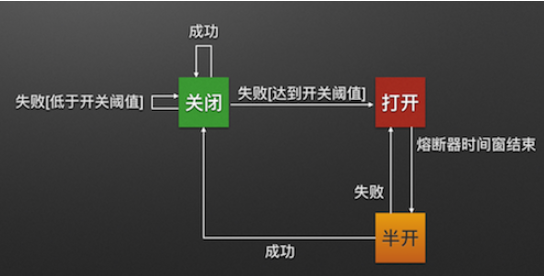
"断路器" 本身是一种开关装置,当有服务发生故障后,通过断路器的故障监控(类似保险熔断),向调用方返回一个符合预期的、可处理的备选响应(FallBack) ,而不是等待/超时或抛出异常,这样就保证了服务调用方的线程不会长时间,不必要地占用,从而避免了故障在分布式系统无线的蔓延,防止了雪崩效应的发生。
为了实现容错和自我保护,我们先看一下Hystrix的设计和实现。
Hystrix设计目标:
对来自依赖的延迟和故障进行防护和控制——这些依赖通常都是通过网络访问的
阻止故障的连锁反应
快速失败并迅速恢复
回退并优雅降级
提供近实时的监控与告警
Hystrix遵循的设计原则:
防止任何单独的依赖耗尽资源(线程)
过载立即切断并快速失败,防止排队
尽可能提供回退以保护用户免受故障
使用隔离技术(例如隔板,泳道和断路器模式)来限制任何一个依赖的影响
通过近实时的指标,监控和告警,确保故障被及时发现
通过动态修改配置属性,确保故障及时恢复
防止整个依赖客户端执行失败,而不仅仅是网络通信
Hystrix实现限流熔断降级
1,通过Command实现
首先添加Hystrix的pom依赖:

配置Hystrix属性(yml文件):
# Hystrix 默认加载的配置文件 - 限流、 熔断
hystrix:# 线程池大小threadpool:default:coreSize: 1maxQueueSize: 200queueSizeRejectionThreshold: 2# 限流策略#如果没有定义HystrixThreadPoolKey,HystrixThreadPoolKey会默认定义为HystrixCommandGroupKey的值userGroup:coreSize: 1maxQueueSize: -1queueSizeRejectionThreshold: 800userThreadPool:coreSize: 1maxQueueSize: -1queueSizeRejectionThreshold: 800# 执行策略
# 资源隔离模式,默认thread。还有一种叫信号量command:default:execution:isolation:strategy: THREAD# 是否打开超时timeout:enabled: true# 超时时间,默认1000毫秒isolation:thread:timeoutInMilliseconds: 15000# 超时时中断线程interruptOnTimeout: true# 取消时候中断线程interruptOnFutureCancel: false# 信号量模式下,最大并发量semaphore:maxConcurrentRequests: 2# 降级策略# 是否开启服务降级fallback:enabled: true# fallback执行并发量isolation:semaphore:maxConcurrentRequests: 100# 熔断策略# 启用/禁用熔断机制circuitBreaker:enabled: true# 强制开启熔断forceOpen: false# 强制关闭熔断forceClosed: false# 前提条件,一定时间内发起一定数量的请求。也就是5秒钟内(这个5秒对应下面的滚动窗口长度)至少请求4次,熔断器才发挥起作用。默认20requestVolumeThreshold: 4# 错误百分比。达到或超过这个百分比,熔断器打开。比如:5秒内有4个请求,2个请求超时或者失败,就会自动开启熔断errorThresholdPercentage: 50# 10秒后,进入半打开状态(熔断开启,间隔一段时间后,会让一部分的命令去请求服务提供者,如果结果依旧是失败,则又会进入熔断状态,如果成功,就关闭熔断)。默认5秒sleepWindowInMilliseconds: 10000# 度量策略# 5秒为一次统计周期,术语描述:滚动窗口的长度为5秒metrics:rollingStats:timeInMilliseconds: 5000# 统计周期内 度量桶的数量,必须被timeInMilliseconds整除。作用:numBuckets: 10# 是否收集执行时间,并计算各个时间段的百分比rollingPercentile:enabled: true# 设置执行时间统计周期为多久,用来计算百分比timeInMilliseconds: 60000# 执行时间统计周期内,度量桶的数量numBuckets: 6# 执行时间统计周期内,每个度量桶最多统计多少条记录。设置为50,有100次请求,则只会统计最近的10次bucketSize: 100# 数据取样时间间隔healthSnapshot:intervalInMilliseconds: 500# 设置是否缓存请求,request-scope内缓存requestCache:enabled: false# 设置HystrixCommand执行和事件是否打印到HystrixRequestLog中equestLog:enabled: falseuserCommandKey:execution:isolation:thread:timeoutInMilliseconds: 5000编写Command类:
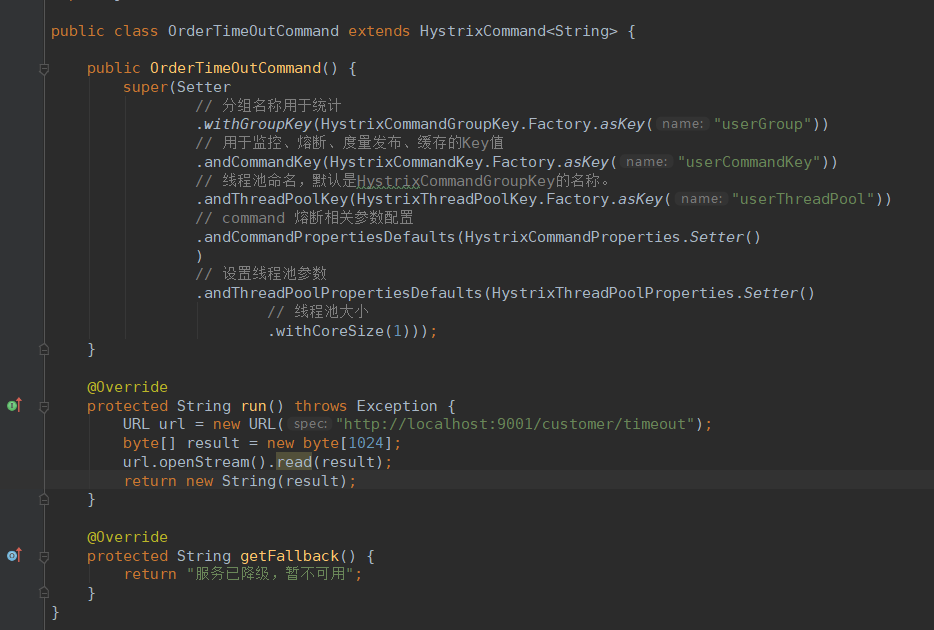
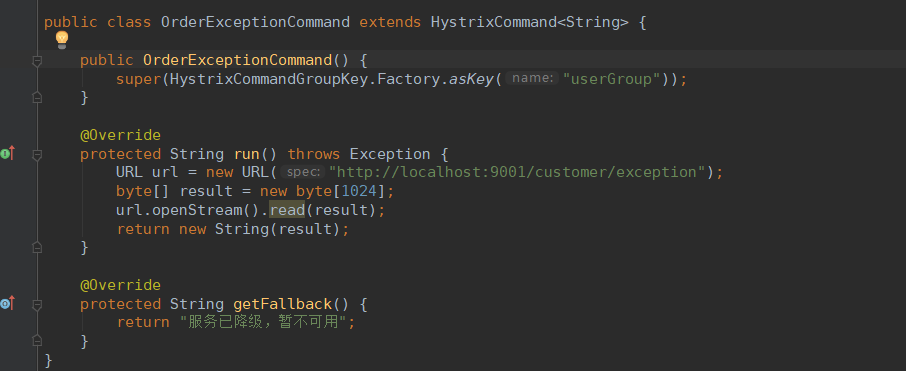
在服务提供者中写调用的接口:
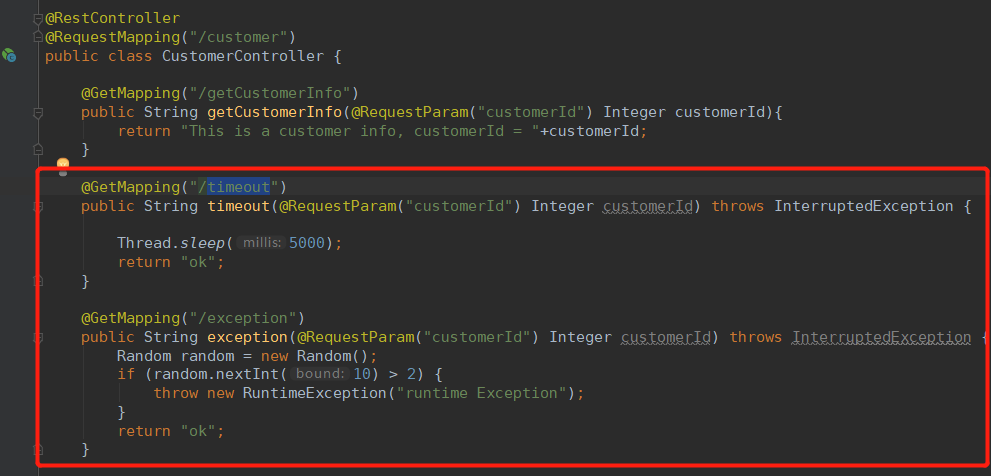
在当前服务中添加接口:
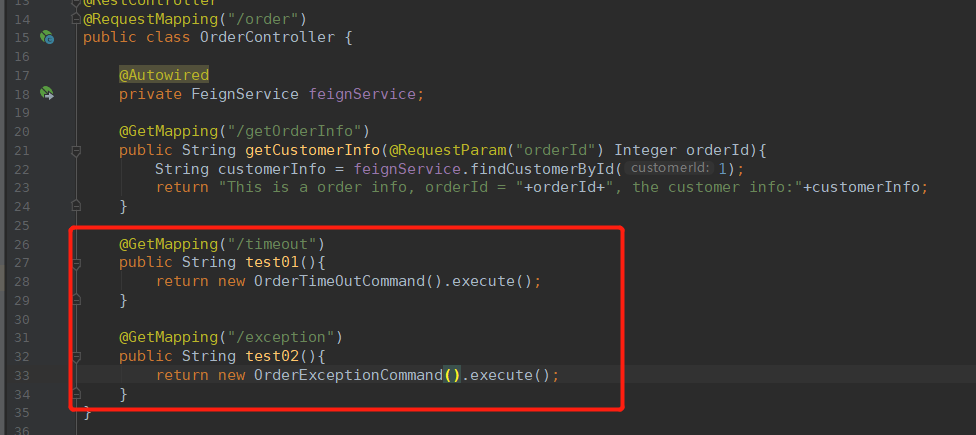
这里HystrixCommand的每次都必须使用新的对象(保证每次请求都是一个新的线程)调用其execute方法,而不能使用单例。否则会提示
Thisinstance can only be executed once.Please instantiate a new instance.
服务降级
请求order-service的/order/exception接口,因为customer-service的/customer/exception会随机抛出运行时异常。当服务异常时,将返回“服务已降级,暂不可用”,而服务正常时将返回ok。这说明我们的服务因为异常降级。
请求/order/timeout接口时,“服务已降级,暂不可用”。如果修改hystrix.command.userCommandKey.execution.isolation.thread.timeoutInMilliseconds=10000,Hstrix限制的超时时间大于接口的返回时长,就能成功返回ok。这个例子说明服务因为请求超时降级了。
服务限流
在分布式环境中,每个服务模块的请求承载量是有限的,因此为保证服务正常,我们会限制来自客户端请求的并发数。可以通过semaphore.maxConcurrentRequests.coreSize.maxQueueSize和queueSizeRejectionThreshold设置信号量模式下的最大并发量、线程池大小、缓冲区大小和缓冲区降级阈值。在示例中我们作如下设置
#不设置缓冲区,当请求数超过coreSize时直接降级
hystrix.threadpool.userThreadPool.maxQueueSize=-1
#超时时间大于我们的timeout接口返回时间
hystrix.command.userCommandKey.execution.isolation.thread.timeoutInMilliseconds=10000
这个时候当连续多次请求/order/timeout接口,在第一个请求还没有成功返回时,查看输出日志可以发现只有第一个请求正常的进入到order-service的接口中,其它请求会直接返回降级信息。这样我们就实现了对服务请求的限流。
服务熔断
在yml配置中开启熔断,并且以5秒为度量周期,当5秒内请求超过4个错误超过50%时,就会开启熔断器,所有的请求都会直接降级,如果5秒内的请求不够4个,就算有三个请求且全部失败也不会开启熔断器。10秒后熔断器进入半打开状态会让一部分请求向服务端发起调用,如果成功关闭熔断器,否则再次进入熔断状态。
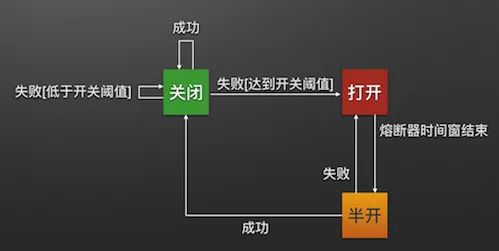
我们对order-serivce的/order/exception连续发起请求(5秒内至少4次),当我们的请求异常超过50%时,服务会直接返回降级信息。
实际上当服务异常、超时、宕机并满足熔断条件时,都会开启熔断。
2,通过FeignClient集成实现
前面通过Command要对每个接口写command类,很是麻烦,但使用Hystrix和Feign的集成就十分方便了。需要在启动类中添加注解@EnableCircuitBreaker启用熔断机制。

添加Feign客户端和降级类
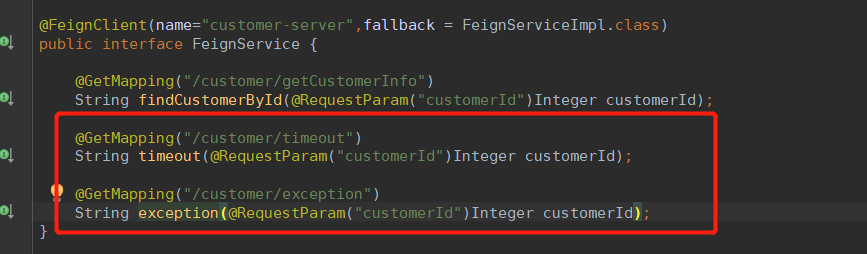
降级类:
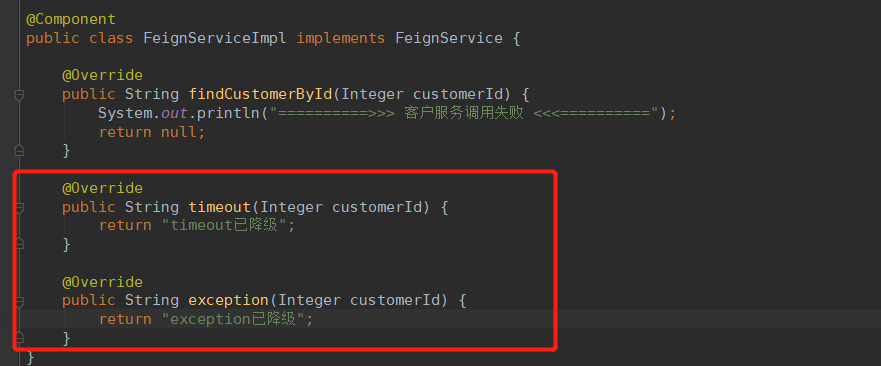
再在Controller添加接口:
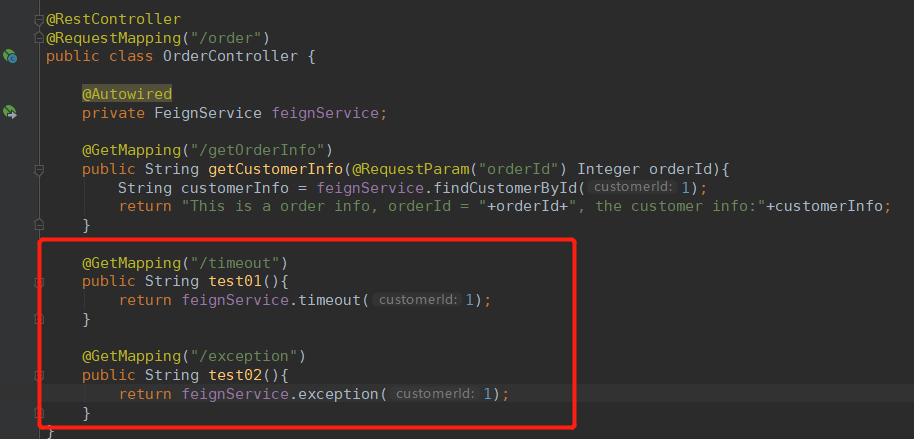
今天要说的就讲到这里,我们下一篇继续讲SpringCloud微服务项目实战。代码我也讲上传到github,请注意后续动态。
推荐阅读:
SpringCloud微服务项目实战 - API网关Gateway详解实现
SpringCloud微服务项目实战 - 网关zuul详解及搭建
SpringCloud微服务项目实战 - 微服务调用详解(附面试题)
SpringCloud微服务项目实战,服务注册与发现(附面试题)
Spring Cloud微服务项目实战--Eureka服务搭建
扫码关注公众号,发送关键词获取相关资料:
发“Springboot”领取电商项目实战源码;
发“SpringCloud”领取学习实战资料;
这篇关于SpringCloud微服务项目实战 - 限流、熔断、降级处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




