本文主要是介绍糖尿病视网膜病变分级新方法:卷积网络做分割和诊断 + 大模型生成详细的测试和治疗建议,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
糖尿病视网膜病变分级新方法:卷积网络做分割和诊断 + 大模型生成详细的测试和治疗建议
- 提出背景
- 相关工作
- 3.1 数据集
- 3.1.1 病变分割
- 3.1.2 图像分级
- 3.1.3 大型语言模型(LLMs)
- 解法 = 数据预处理 + 数据增强 + 网络架构 + 训练过程 + 测试过程
- 子解法1:数据预处理
- 子解法2:数据增强
- 子解法3:网络架构
- 子解法4:训练过程
- 子解法5:测试过程
论文:https://arxiv.org/pdf/2401.02759
代码:https://github.com/Manoj-Sh-AI/Diabetic-Retinopathy-Detection-and-Clasification-System
卷积网络做分割和诊断,并通过大模型生成详细的测试和治疗建议,从而实现精准、高效的糖尿病视网膜病变检测和管理。
提出背景
糖尿病视网膜病变(DR)是糖尿病的一种严重并发症,通过破坏视网膜内的细小血管,威胁着视力,甚至可能导致失明。
该病经历四个不同阶段的发展:轻度非增殖性视网膜病变、中度非增殖性视网膜病变、重度非增殖性视网膜病变和增殖性糖尿病视网膜病变。
每个阶段都有其独特的特征,使诊断过程更加复杂,尤其是在早期阶段没有任何预警信号时。
严重性在于,及时的治疗和监测可以将新的DR病例减少约56%。
然而,准确识别疾病的早期阶段对临床医生来说是一项具有挑战性的任务,即使是那些训练有素的医生也是如此。
手工检查眼底图像以检测早期DR是一个复杂的过程,现有的诊断方法效率低下,导致眼科医生之间的意见不一致,并为研究提供了不准确的真实数据。
为应对这些挑战,各种算法已经出现,用于解决DR的检测问题。
最初,这些算法基于经典的计算机视觉方法。
然而,近年来,随着深度学习的兴起,卷积神经网络(CNN)在分类和目标检测任务(包括糖尿病视网膜病变的诊断)中展示了其强大的能力。
本研究论文介绍了一种新的方法来解决DR检测中的复杂问题。通过利用迁移学习,该方法使用一张眼底照片自动检测糖尿病视网膜病变的阶段。
值得注意的是,该方法旨在从一个有限且噪声较大的数据集中学习重要特征,呈现出作为自动解决方案中的一个有价值的DR阶段筛查工具的潜力。如图1所示,方法的有效性得到了强调。值得一提的是,提出的方法在APTOS 2019盲症检测竞赛中取得了可喜的排名,显示出其能力,获得了0.92546的高加权卡帕分数。本研究旨在显著推动DR检测方法的发展,特别是在自动化系统的背景下,解决早期诊断和干预糖尿病视网膜病变的关键需求。
轻度非增殖性视网膜病变:
- 这是糖尿病视网膜病变的最早阶段。
- 其特征是微动脉瘤的出现,对血管的影响有限,只有轻微的扭曲。
中度非增殖性视网膜病变:
- 此阶段的进展伴随着血管因扭曲和肿胀而失去输送血液的能力。
- 血管异常变得更加明显。扭曲和肿胀阻碍了正常的血液运输,影响了整体的视网膜健康。
重度非增殖性视网膜病变:
- 导致视网膜供血不足。
- 血管阻塞加剧了病情。
- 视网膜发出信号,刺激新血管的生长,以补偿减少的血供。
增殖性糖尿病视网膜病变:
- 标志着新血管的增殖。视网膜分泌的生长因子激活了新血管的增殖。
- 这些血管沿着视网膜的内层生长,并延伸到填充眼球的玻璃体中。
可以参考类似的方法来检测另一种眼疾,如黄斑变性。假设研究使用类似的迁移学习与CNN相结合的方法,从视网膜图像中分类黄斑变性的阶段
。研究人员可以应用U-Net架构来分割视网膜层和特定于黄斑变性的病变,然后将这些输出与预训练模型结合起来,以分类疾病的严重程度。
目标是创建一个自动化系统,能够准确预测和推荐必要的测试和治疗,从而改进患者护理和黄斑变性的管理,类似于在糖尿病视网膜病变研究中的做法。
相关工作
3.1 数据集
本研究中使用的图像数据来自不同的数据集。研究包括三个主要目标:病变分割、疾病/图像分级和治疗建议。
3.1.1 病变分割
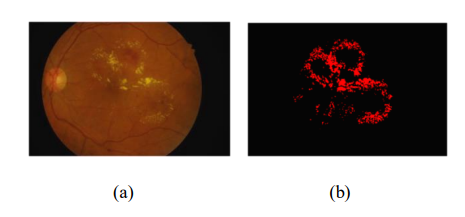
病变分割使用的眼底图像来自印度马哈拉施特拉邦南德市一家眼科诊所的视网膜专家拍摄的IDRiD数据集。
从可用的数千次检查中,我们提取了516张图像形成我们的数据集,如图2(a)和(b)所示。
专家验证所有图像均具有足够的质量和临床相关性,没有图像重复,并且包含了代表糖尿病视网膜病变(DR)和糖尿病黄斑水肿(DME)的合理混合病变分层。
眼底相机规格
图像使用Kowa VX-10 alpha数字眼底相机拍摄,视野为50度,所有图像均集中在黄斑附近。
图像分辨率为4288×2848像素,以jpg格式存储,每张图像大小约为800KB。
像素级标注数据
为了评估与糖尿病视网膜病变(DR)相关的病变分割技术的有效性,提供了针对不同异常的二值掩码,包括微动脉瘤(MA)、硬性渗出物(EX)、出血(HE)和软性渗出物(SE)。数据集包括jpg格式的彩色眼底图像以及对应的tif格式的二值掩码。
数据集包含81张带有微动脉瘤二值掩码的图像、81张带有硬性渗出物的图像、80张带有出血的图像和40张带有软性渗出物的图像。
这些数字表示图像的数量,其中一些可能包含多种病变,从而增强了数据集在糖尿病视网膜病变病变分割技术研究和性能评估中的多样性。
3.1.2 图像分级
我们研究中使用的图像数据来自多个数据集,主要集中在Kaggle糖尿病视网膜病变检测挑战赛2015(EyePACs,2015)的一个公开数据集上,以预训练我们的卷积神经网络(CNN)。
该数据集被认为是最大公开可用的数据集,包含35,126张捕捉到美国公民左眼和右眼的眼底照片。
这些图像标注了糖尿病视网膜病变的各个阶段,从没有糖尿病视网膜病变(标签0)到增殖性糖尿病视网膜病变(标签4),如图3所示。
除了Kaggle数据集,我们还整合了其他较小的数据集,包括印度糖尿病视网膜病变图像数据集(IDRiD)(Sahasrabuddhe和Meriaudeau,2018),我们使用了其中的413张眼底照片,以及MESSIDOR(视网膜眼科学领域的分割和索引技术评估方法)(Decencière等人,2014)数据集,贡献了1,200张眼底照片。
为了确保一致性,我们使用了经过眼科医生小组重新标注的标准分级版本的MESSIDOR数据集(Google Brain,2018)。
我们在Kaggle APTOS 2019盲症检测(APTOS 2019)数据集上进行了模型评估,访问限制为训练部分。
完整的APTOS 2019数据集包括18,590张眼底照片,分为3,662张训练图像、1,928张验证图像和13,000张测试图像,按Kaggle竞赛组织者的安排进行。
所有数据集都展示了类似的类别分布,如图2所示。
我们保持了数据集的原始分布,没有进行下采样或过采样。所有数据集中最小的原生尺寸为640x480。图4展示了APTOS 2019的一个示例图像。
3.1.3 大型语言模型(LLMs)
在数据集部分,生成测试/治疗建议涉及与预训练的大型语言模型的集成,从分割图像中派生出广泛的输入。
这些输入包括针对各种病变的二进制指示符,包括血管分割、出血分割、硬性渗出物分割、微动脉瘤分割、光盘分割和软性渗出物分割。
每个病变在二进制输入中表示为存在(True)或不存在(False)。
此外,还从分类或图像分级模型生成字符串输入,提供糖尿病视网膜病变(DR)阶段的见解,分为0到4类。
二进制和字符串输入的组合形成了一个强大的数据集,由预训练的大型语言模型ChatGPT处理。ChatGPT解释并综合这些多样化的信息,生成详细的测试/治疗建议,贡献于一个复杂的决策支持系统,该系统同时考虑了详细的视觉分割特征和DR严重程度的临床分类。
目的:通过先进的模式识别方法,检测和分类糖尿病视网膜病变(DR),以实现早期诊断和及时干预,从而改善患者预后。
解法 = 数据预处理 + 数据增强 + 网络架构 + 训练过程 + 测试过程
这篇论文的亮点包括:
-
利用迁移学习进行自动检测:
- 通过迁移学习和卷积神经网络(CNN),实现了单张眼底照片的自动糖尿病视网膜病变(DR)检测。
-
高效的DR检测性能:
- 在APTOS 2019盲症检测竞赛中取得了0.92546的高加权卡帕分数,展示了所提方法的高效性和准确性。
-
综合性方法:
- 方法涵盖了数据预处理、数据增强、U-Net神经网络架构的使用,充分展示了从数据准备到模型训练和评估的完整流程。
-
分割图像输入与预训练大型语言模型的集成:
- 强调了将分割图像结果与预训练的大型语言模型(如ChatGPT)相结合,用于生成测试和治疗建议。这种集成增强了系统的实用性和临床相关性。
-
填补研究空白:
- 识别并探索现有文献中的研究缺口,特别是在整合预训练的大型语言模型与分割图像输入生成建议方面的不足,以及理解这些集成组件在网络应用中的动态交互。
-
提升诊断和干预能力:
- 研究结果显示,该方法在分割视网膜结构(如血管、硬性和软性渗出物、出血、微动脉瘤和视盘)方面表现出色,具有高Jaccard、F1、召回率、精确度和准确度,证明了其在提高视网膜病理评估诊断能力方面的潜力。
-
对医疗影像分析的贡献:
- 研究成果对医疗影像和自动诊断领域有重要贡献,特别是在改善糖尿病视网膜病变患者预后方面,展示了其在医学图像分析领域的显著应用价值。
子解法1:数据预处理
之所以用数据预处理子解法,是因为需要将原始数据转换为适合模型输入的格式,提高模型的训练效率和效果。
- 定义自定义数据集类
- 之所以用自定义数据集类,是因为需要简化数据加载和预处理的过程,提高代码的模块化和可维护性。
- 实现
__init__方法:初始化数据集,存储图像和掩码的路径。 - 实现
__getitem__方法:读取和预处理每个样本,包括图像标准化和维度调整。 - 实现
__len__方法:返回数据集中样本的总数。
子解法2:数据增强
之所以用数据增强子解法,是因为可以增加数据集的多样性,防止模型过拟合,提高模型在实际应用中的泛化能力。
- 定义数据增强函数
- 之所以用数据增强函数,是因为需要系统化地对图像和掩码进行多种变换,模拟实际场景中的不同情况。
- 实现水平翻转、垂直翻转和旋转。
- 调整掩码以匹配增强后的图像。
- 将增强后的图像和掩码保存到指定目录。
子解法3:网络架构
之所以用U-Net网络架构子解法,是因为其编码器-解码器结构和跳跃连接有助于有效地捕捉高层和低层特征,实现精准的图像分割。
- 构建U-Net模型
- 之所以用U-Net模型,是因为它在医学图像分割任务中表现优异,能够同时处理全局和局部特征。
- 编码器部分:卷积层+批归一化+ReLU激活+最大池化。
- 瓶颈层:卷积层。
- 解码器部分:转置卷积+跳跃连接+卷积层。
- 分类器:1x1卷积层输出单通道。
子解法4:训练过程
之所以用训练过程子解法,是因为需要通过迭代优化模型参数,使模型能够准确地进行分割任务。
-
预训练
- 之所以用预训练,是因为设置合适的超参数和数据准备有助于模型的初始收敛。
- 配置超参数:图像尺寸、批量大小、训练轮数、学习率等。
- 加载数据集:使用自定义数据加载器。
- 初始化优化器和损失函数。
-
主训练
- 之所以用主训练,是因为需要在多个轮次中优化模型,确保模型能够有效地学习数据中的模式。
- 迭代训练:最小化损失函数,评估验证集上的性能。
- 保存最佳模型检查点。
-
训练后
- 之所以用训练后步骤,是因为需要总结训练结果并准备模型进行部署或进一步分析。
- 选择最佳模型:基于验证集上的最低损失。
- 提供训练损失、验证损失和训练时间等关键指标。
子解法5:测试过程
之所以用测试过程子解法,是因为需要评估模型在独立数据集上的性能,以确保其在实际应用中的有效性。
-
加载测试数据集
- 之所以用加载测试数据集,是因为需要评估模型在未见过的数据上的表现。
- 预处理测试图像和掩码。
-
评估模型性能
- 之所以用评估模型性能,是因为需要量化模型的分割准确性和效率。
- 计算评估指标:Jaccard指数、F1评分、召回率、精确度和准确度。
- 计算每秒帧数(FPS):评估模型的实时处理能力。
目的:通过先进的模式识别方法,检测和分类糖尿病视网膜病变(DR),以实现早期诊断和及时干预,从而改善患者预后。
子解法1:数据预处理
之所以用数据预处理子解法,是因为需要将原始数据转换为适合模型输入的格式,提高模型的训练效率和效果。
- 定义自定义数据集类
- 之所以用自定义数据集类,是因为需要简化数据加载和预处理的过程,提高代码的模块化和可维护性。
- 实现
__init__方法:初始化数据集,存储图像和掩码的路径。 - 实现
__getitem__方法:读取和预处理每个样本,包括图像标准化和维度调整。 - 实现
__len__方法:返回数据集中样本的总数。
子解法2:数据增强
之所以用数据增强子解法,是因为可以增加数据集的多样性,防止模型过拟合,提高模型在实际应用中的泛化能力。
- 定义数据增强函数
- 之所以用数据增强函数,是因为需要系统化地对图像和掩码进行多种变换,模拟实际场景中的不同情况。
- 实现水平翻转、垂直翻转和旋转。
- 调整掩码以匹配增强后的图像。
- 将增强后的图像和掩码保存到指定目录。
子解法3:网络架构
之所以用U-Net网络架构子解法,是因为其编码器-解码器结构和跳跃连接有助于有效地捕捉高层和低层特征,实现精准的图像分割。
- 构建U-Net模型
- 之所以用U-Net模型,是因为它在医学图像分割任务中表现优异,能够同时处理全局和局部特征。
- 编码器部分:卷积层+批归一化+ReLU激活+最大池化。
- 瓶颈层:卷积层。
- 解码器部分:转置卷积+跳跃连接+卷积层。
- 分类器:1x1卷积层输出单通道。
子解法4:训练过程
之所以用训练过程子解法,是因为需要通过迭代优化模型参数,使模型能够准确地进行分割任务。
-
预训练
- 之所以用预训练,是因为设置合适的超参数和数据准备有助于模型的初始收敛。
- 配置超参数:图像尺寸、批量大小、训练轮数、学习率等。
- 加载数据集:使用自定义数据加载器。
- 初始化优化器和损失函数。
-
主训练
- 之所以用主训练,是因为需要在多个轮次中优化模型,确保模型能够有效地学习数据中的模式。
- 迭代训练:最小化损失函数,评估验证集上的性能。
- 保存最佳模型检查点。
-
训练后
- 之所以用训练后步骤,是因为需要总结训练结果并准备模型进行部署或进一步分析。
- 选择最佳模型:基于验证集上的最低损失。
- 提供训练损失、验证损失和训练时间等关键指标。
子解法5:测试过程
之所以用测试过程子解法,是因为需要评估模型在独立数据集上的性能,以确保其在实际应用中的有效性。
-
加载测试数据集
- 之所以用加载测试数据集,是因为需要评估模型在未见过的数据上的表现。
- 预处理测试图像和掩码。
-
评估模型性能
- 之所以用评估模型性能,是因为需要量化模型的分割准确性和效率。
- 计算评估指标:Jaccard指数、F1评分、召回率、精确度和准确度。
- 计算每秒帧数(FPS):评估模型的实时处理能力。
目的:通过先进的模式识别方法,检测和分类糖尿病视网膜病变的不同阶段,实现早期诊断和及时干预。
-
数据预处理:定义自定义数据集类,进行图像标准化和尺寸调整。
- 定义自定义数据集类:存储眼底图像及其对应的标签路径。
- 图像预处理:标准化、调整尺寸,以适应模型输入要求。
-
数据增强:实现数据增强函数,进行图像旋转、翻转和缩放。
- 实现数据增强函数:对图像进行水平翻转、垂直翻转和旋转。
- 调整图像标签以匹配增强后的图像。
-
网络架构:构建ResNet或DenseNet模型,结合U-Net架构用于图像分割和分类。
- 构建ResNet或DenseNet模型:用于提取特征和分类。
- 结合U-Net架构:进行图像分割,识别不同的病变区域。
-
训练过程:预训练和主训练模型,使用合适的超参数,保存最佳模型检查点。
- 预训练阶段:配置超参数,准备训练和验证数据集。
- 主训练阶段:在多个轮次中迭代优化模型参数,评估验证集性能。
- 保存最佳模型检查点:基于最低验证损失选择最佳模型。
-
测试过程:加载测试数据集,计算模型在独立数据集上的性能指标,评估实时处理能力。
- 加载测试数据集:预处理测试图像和标签。
- 评估模型性能:计算Jaccard指数、F1评分、召回率、精确度和准确度,评估每秒帧数(FPS)。
这种解法通过逐步细化每个步骤,确保系统在糖尿病视网膜病变分级任务中具备高效性和准确性。
这篇关于糖尿病视网膜病变分级新方法:卷积网络做分割和诊断 + 大模型生成详细的测试和治疗建议的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




