本文主要是介绍基础—SQL—DML(数据操作语言)修改和删除,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、引言
接着上次博客,这次讲解DML语句中的修改数据和删除数据操作。
二、DML—修改数据
- UPDATE 表名 SET 字段名1=值1 ,字段名2=值2 , ...[ WHERE 条件];
注意:修改语句的条件可以有,也可以没有。如果没有条件,则会修改整张表的所有数据。
(1)案例分析
首先表的基本结构和表的基础数据准备好了。
INSERT INTO employee VALUES (1,'1','Itcast','男','10','123456781234567890','2000-10-01'),(2,'2','张无忌','男','38','123456781234567890','1980-10-01'),(3,'3','刘德华','男','18','123456781234567890','2006-10-01'),(4,'4','赵一敏','女','18','123456781234567890','2006-10-01');
SELECT * FROM employee;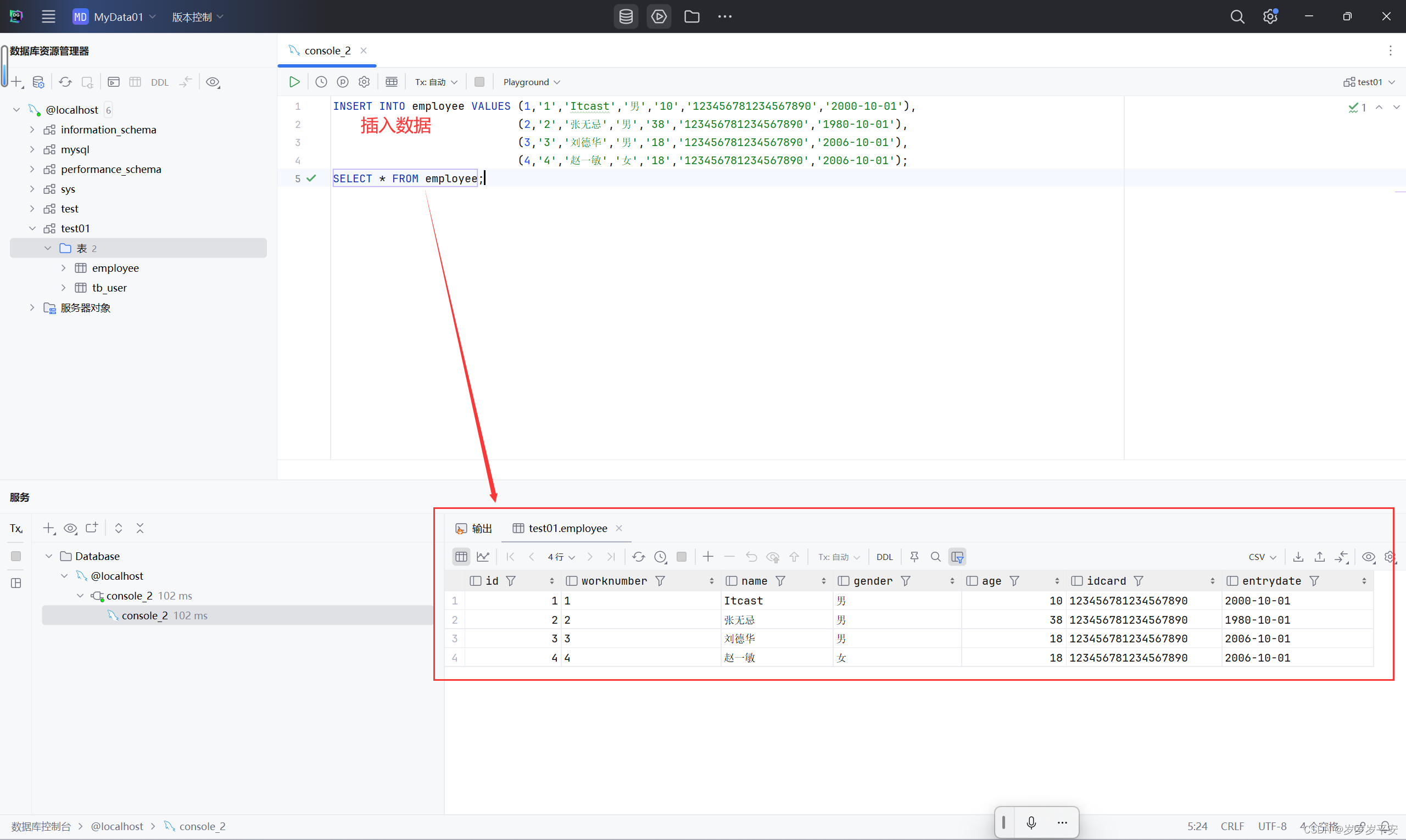
然后开始进行数据的修改操作。
(2)操作需求
1、修改 id 为1的数据,将 name 改成 " ITfeisi " 。
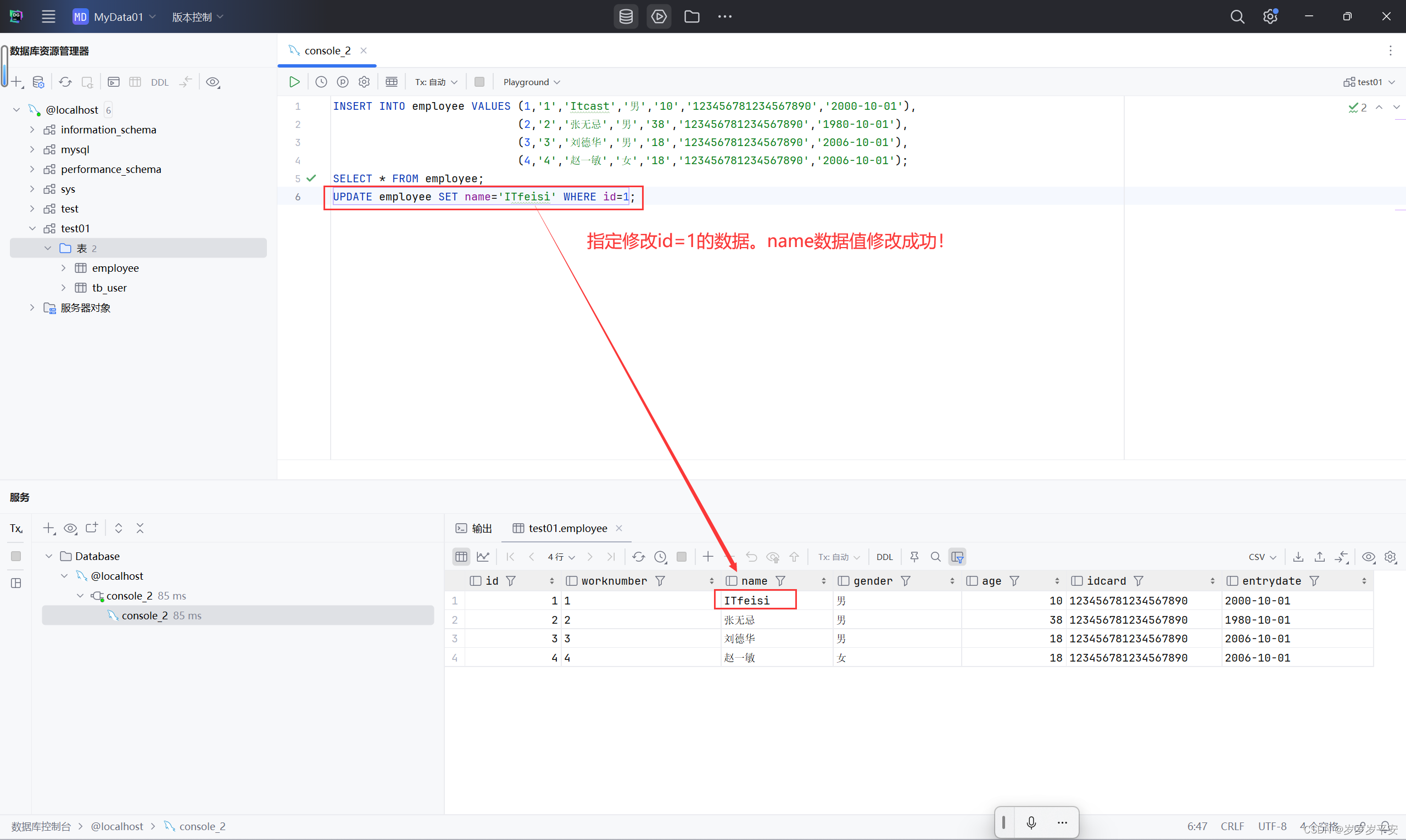
2、修改 id 为4的数据,将 name 修改为 " 小昭 ",gender 修改为 "男" 。
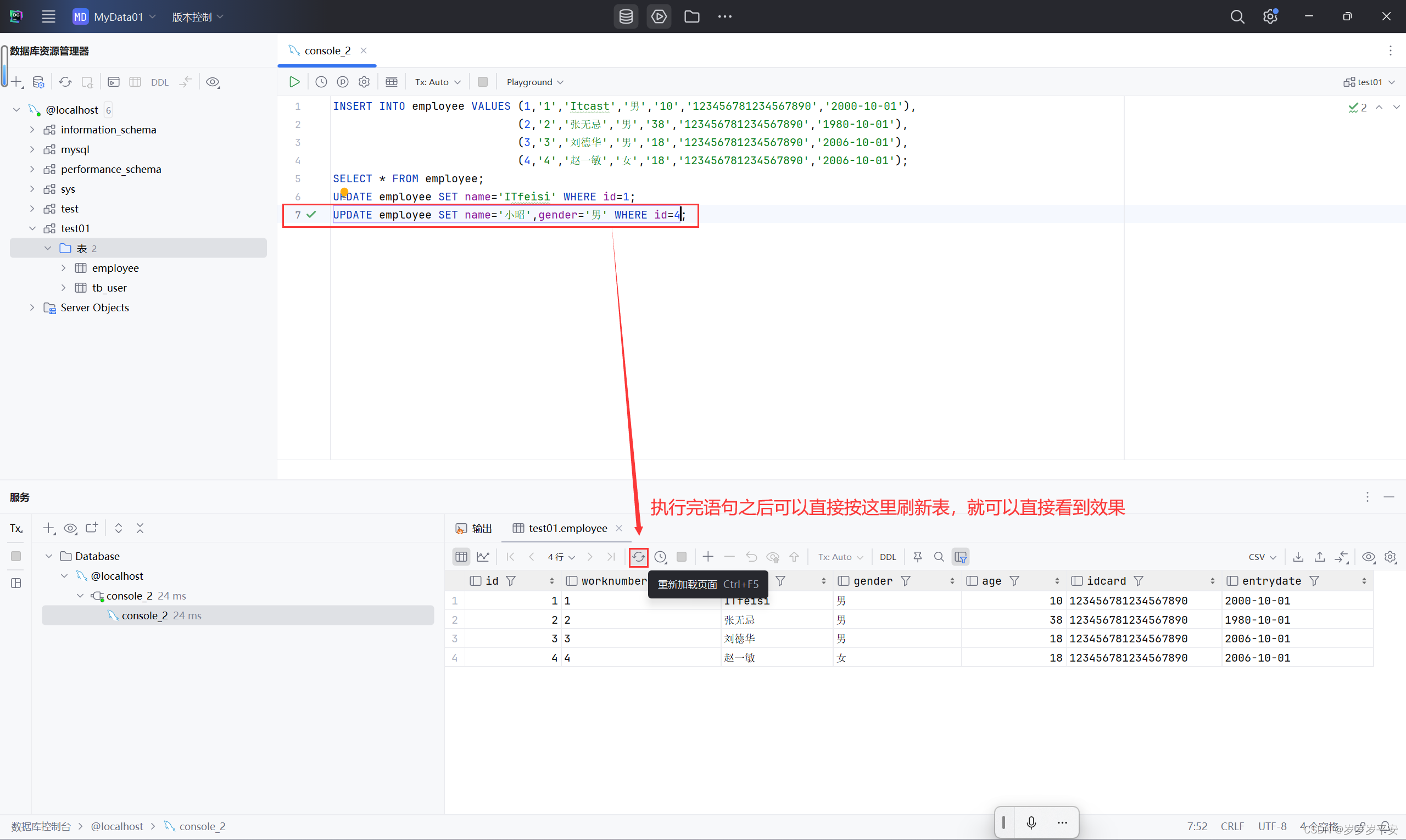
结果展示:

3、将所有的员工入职日期修改为 " 2008-01-01 " 。
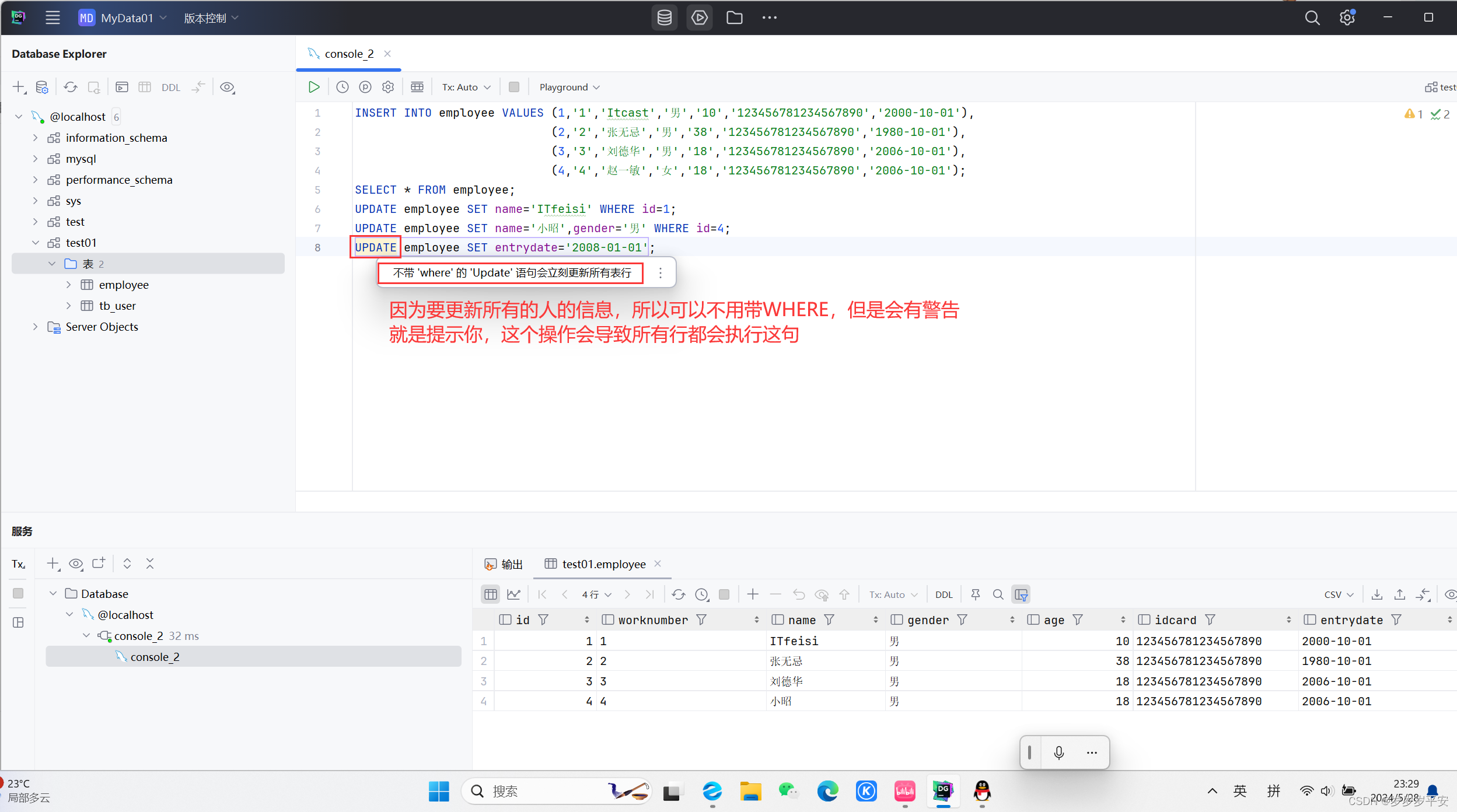
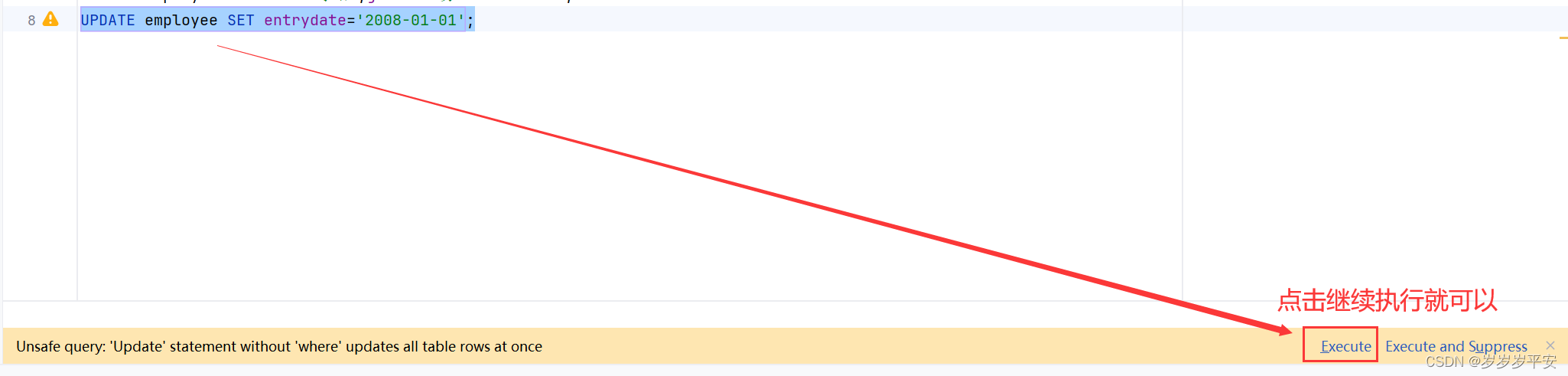
结果展示:

三、DML—删除数据
- DELETE FROM 表名 [ WHERE 条件 ];
注意:
1、DELETE 语句的条件可以有,也可以没有。如果没有条件,则会删除整张表的所有数据2、DELETE 语句不能删除某一个字段的值 (如果要删除某一字段的值,可以使用 UPDATE ,将这个字段设置为NULL就行)
(1)删除字段 gender=' 女 '的员工
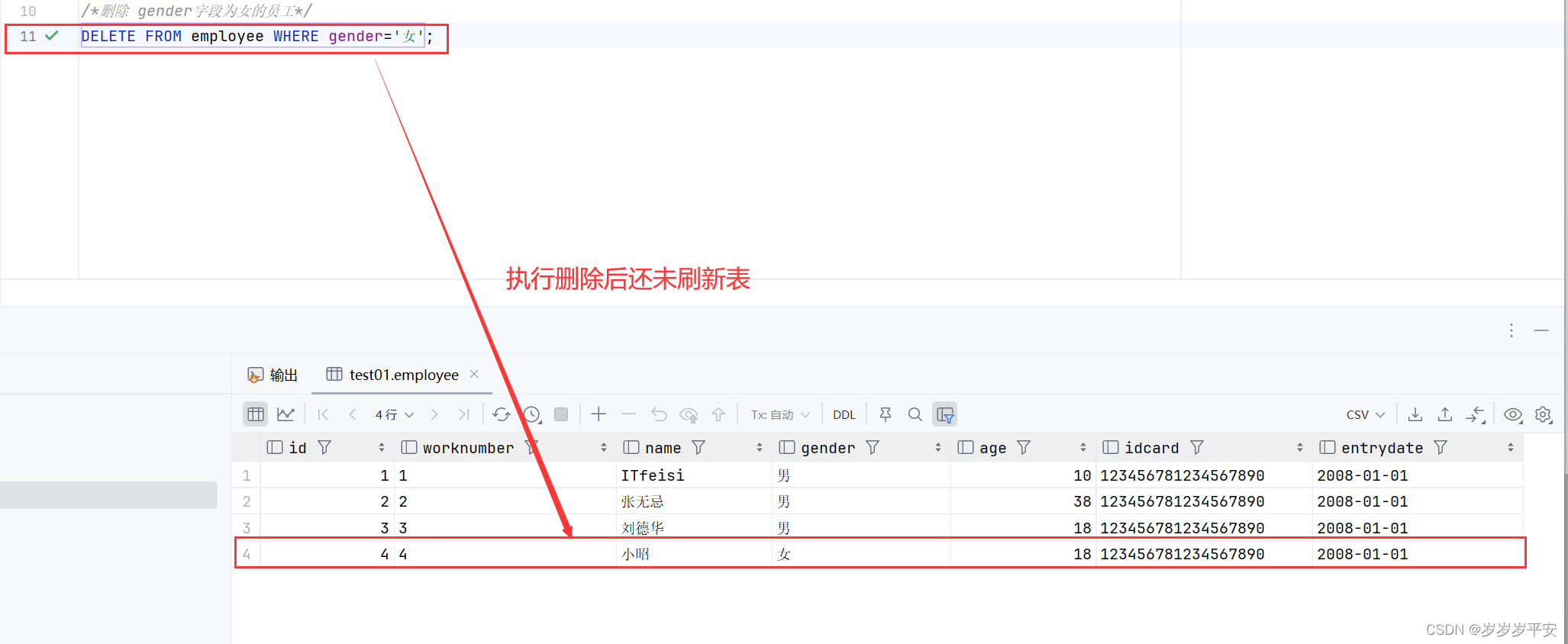

(2)删除所有的员工
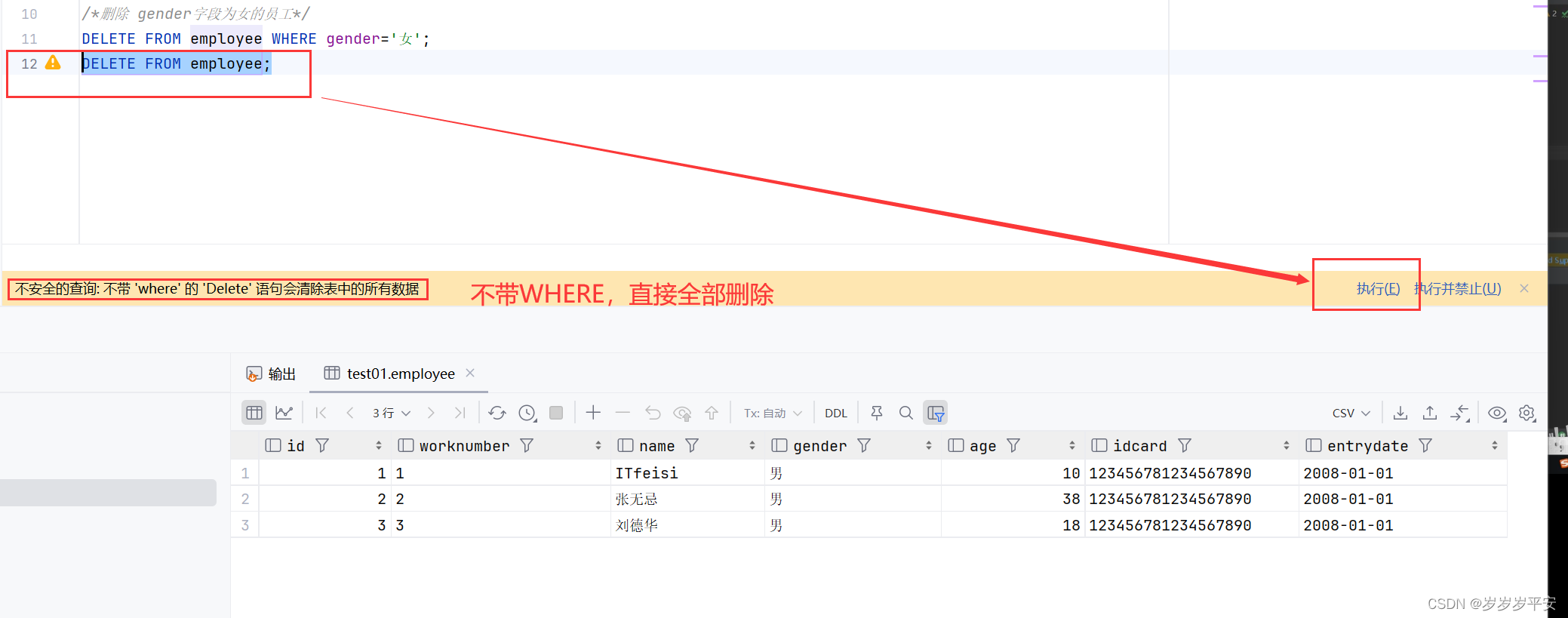
 四、小结
四、小结
DML语句已经全部学完,接下来做个小的总结。
DML语言是数据操作语言,主要控制的是数据库表中的增删改的操作。
1、添加数据
INSERT INTO 表名 (字段1,字段2,...) VALUES (值1,值2, ...) OR [ ,(值1,值2,..) ... ];
注意:字段和值的对应关系。OR:代表另外一种写法,直接给所有字段赋值或批量添加数据
2、修改数据
UPDATE 表名 SET 字段1=值1 ,字段2=值2 [ WHERE 条件 ];
注意:若没有带 WHERE 条件,则是要修改整张表的所有记录
3、删除数据
DELETE FROM 表名 [ WHERE条件 ];
注意:假如没有 WHERE 条件,就是要删除整张表的数据
这篇关于基础—SQL—DML(数据操作语言)修改和删除的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



